






ABSTRACT
联邦学习是一种机器学习技术,其中具有本地数据的多个客户端协作训练机器学习模型。在主要的联邦学习算法FedAvg中,客户端在本地训练机器学习模型,并与服务器共享训练后的模型。虽然敏感数据永远不会发送到服务器,但恶意服务器可以通过在每一轮训练中访问客户端的模型来构建原始训练数据。加密、可信执行环境或差分隐私等安全聚合技术可用于解决此问题。然而,这些技术会产生计算和通信开销,或影响模型的准确性。在本文中,我们考虑了一种安全的多方计算设置,其中客户端使用附加秘密共享将其模型发送到多个服务器。我们的解决方案提供了安全聚合,只要至少有两个非串通服务器。此外,我们提供了数学证明,表明在每个训练轮结束时的安全聚合模型与FedAvg提供的模型完全相等,而不影响准确性,并且具有高效的通信和计算。与最先进的安全聚合解决方案SCOTCH相比,实验结果表明,我们的方法比SCOTCH快557%,同时将客户端的通信成本降低了25%。此外,在平衡、不平衡、IID和非IID数据分布下,训练模型的精度与FedAvg完全相同,但仅慢8%。
KEYWORDS:
privacy-preserving machine learning, federated learning, secure
aggregation, additive secret sharing
INTRODUCTION
机器学习(ML)被广泛用于数据分析,并且需要大量的数据来进行更好的预测。多个数据所有者将受益于对其聚合数据执行ML任务。然而,由于知识产权或隐私法(即《健康保险可携带性和责任法案》(HIPAA)[17]和《通用数据保护条例》(GDPR)[11]),数据所有者不想向对方透露其敏感数据。联邦学习(FL)允许在每个用户的站点本地训练机器学习模型,然后以某个频率仅与中央服务器通信参数,以生成由所有站点共享的全局模型。谷歌[25]最近引入了联邦学习,使移动设备能够协作学习共享预测模型,同时将所有训练数据保持在本地。看起来,联合学习通过将训练数据集保存在用户的网站上并在本地训练机器学习模型来保护数据安全。然而,即使只有参数而不是数据被传送到中央服务器,参数也可能被分析以泄露大量的私人数据[18,39]。基于差分隐私[15,35,37]和安全多方通信[7,33,38],已经提出了不同的安全聚合技术来增加联合学习的数据隐私。然而,这些技术会影响模型的准确性,并分别产生计算和通信开销。最近,提出了SCOTCH[28]框架,该框架确保了联邦学习中训练数据的严格隐私保证。SCOTCH[28]是一个简单的联合学习框架,允许使用安全的外包计算和秘密共享进行分散梯度聚合。尽管SCOTCH[28]在训练时间和通信成本方面有效率的提高,但其准确性随着客户数量的增加而降低。此外,在联邦学习中需要一种安全的聚合方法,该方法在训练时间和通信成本方面是有效的,并且至少具有与FedAvg[25]相同的准确性。在这项工作中,我们介绍了FedShare,作为一种用于联邦学习的高效安全聚合框架。FedShare不允许服务器通过使用附加密钥共享方案来访问每个客户端的模型更新。客户端根据参与服务器的数量创建多个更新共享。特别是,我们的贡献是:
•我们分析了用于联邦学习的最先进的安全聚合协议的局限性。
•我们介绍了FedShare,与主要的基线联邦学习算法FedAvg[25]相比,该框架通过使用附加秘密共享方案在不影响准确性的情况下提供有保障和可扩展的隐私。
•我们从数学和实验上证明,在FedShare中每轮训练后的聚合的权重完全等于FedAvg[25]。因此,使用FedShare或FedAvg[25]训练的模型的准确性之间没有差异。
•我们将FedShare与最先进的技术SCOTCH[28]在准确性和效率方面进行了比较。实验结果表明,在没有任何额外昂贵操作的情况下,FedShare在准确性和通信成本方面优于SCOTCH[28]。
2. BACKGROUND
在本节中,我们介绍了一些关于联合学习、推理攻击和秘密共享的初步内容,以帮助理解所提出的框架。
2.1 Federated Learning
McMahan[25]引入了联邦学习(FL)作为一种创新解决方案,使客户能够使用其本地数据集协同训练ML模型(例如,深度神经网络),同时数据集将保存在本地。由于无需将数据集发送给第三方,这提高了数据所有者的隐私。FedAvg[25]是联合学习解决方案的主要基线算法。在每轮训练𝑡中,联邦服务器𝐹选择𝑚客户端的一个子集,并发送当前全局模型𝑊𝑡每个客户端。每个客户端使用他自己私有的数据来训练E个epoch,并将Wt发送返回给服务器F。然后,𝐹根据每个客户端的数据大小计算从所选客户端接收的更新的加权平均值以生成𝑊𝑡+1。同样的过程仍在继续𝑇训练回合。
2.2 Inference Attacks against ML
机器学习模型容易受到推理攻击,在推理攻击中,对手学习有关用于训练ML模型的数据的信息。如果用于训练ML模型的数据是敏感的,那么成功的推理攻击就会揭开这些敏感数据。我们将简要讨论其中的一些攻击。成员推断攻击(MIA)确定是否使用特定记录来训练模型[19,36]。属性推断攻击旨在推断训练记录的属性[14,32]。重建攻击试图重建训练样本[8,32]。最后,源推断攻击(SIA)的目的是找到特定训练数据的所有者[20]。
2.3 Secret Sharing
许多安全多方计算(SMPC)协议[12,16,27]的主要构建块之一是密钥共享[4]。密钥共享或密钥分割是指我们通过这样一个方法将密钥分成n部分,这个密钥可以被重建当只有足够数量的人合并他们各自的部分。m-out-of-n密钥共享事指至少需要有m个密钥部分才会泄露整个密钥。加法密钥共享是一种基于加法运算的密钥共享方案,必须要有所有的密钥份额部分才能解开这个密钥。由于其简单实用,在相关工作中得到了广泛的应用[3,7,10,13,22,28,31]。由于附加密钥共享需要所有的各方共享才能揭示秘密,因此它是n-out-of-n密钥共享,因为在这种情况下𝑚 = 𝑛。
.
3 RELATED WORK
针对参与联合学习训练过程的客户端的推理攻击可以由中央服务器执行,因为它可以在训练期间访问所有客户端的模型更新。此外,第三方可以进行攻击,因为它在完成训练过程后可以访问训练的模型[1,6,26]。然而,Nasr等人[29]展示了,与独立设置相比,第三方对于FL的高性能的成功的成员推断攻击更加困难。即使攻击者在针对联邦ML模型的成功推理攻击中推断出敏感信息,在大多数情况下,推断出的信息也无法链接到特定的客户端。然而,由于中央服务器可以访问所有客户端的每次更新,因此它可以成功地对客户端进行推理攻击。考虑到中央服务器只需要来自客户端的更新的聚合,而不需要单独的每个更新,最近的许多贡献都集中在FL中的安全聚合问题上。安全聚合是一个计算密钥总和的问题,其中没有一方向其他方或聚合器透露其自己的密钥部分。安全聚合技术可以分为四类,包括密钥共享、差分隐私、同态加密和可信执行环境。我们将分别讨论每一组,因为每一组都有自己的优点和缺点。
3.1 Differential Privacy
基于差分隐私的解决方案通常具有较低的通信或计算成本开销。然而,差异隐私使模型无法达到其潜在的准确性。Hybridalpha[37]通过在客户端之间使用分布式噪声和功能加密, 的一种基于差分隐私的机制。DPFL[15]是一种联邦优化算法,用于客户端在训练过程中隐藏其贡献,不需要模型的权重。通过添加高斯噪声,Dopamine [23]中的客户端使用具有差分隐私的随机梯度下降(DP-SGD)。
3.2 Homomorphic Encryption
虽然基于同态加密的解决方案通常不会牺牲模型的准确性,但它们在客户端和服务器端都需要大量的计算资源。因此,这些解决方案中的大多数仅适用于 cross-silo settings,其中有可靠的通信和强大的计算资源,但不能用于跨设备设置。PrivFL[24]使用加性同态加密来解决线性回归和逻辑回归算法中的安全聚合问题。BatchCrypt[38]试图通过量化梯度值来解决同态加密的加密和通信成本。SAFELean[13]中的聚合器使用加密方案的加性同态特性来聚合客户端发送的加密数据。
3.3 Trusted Execution Environment
可信执行环境可以用来解决安全聚合的问题,因为它可以防止未经授权的实体访问客户端发送到服务器的真实数据。但是,无论是在传输中还是在静止时,都需要将数据作为内层进行加密。此外,研究人员已经发现,可信执行环境存在关键的side-channel安全缺陷,可能会从安全容器中捕获机密数据。FedBuff[30]在他们提出的异步联邦学习算法中使用Intel SGX来解决安全聚合问题。
3.4 Secret Sharing
基于秘钥共享的解决方案比其他机制更受欢迎,主要有三个原因。首先,它们具有可接受的跨设备联合学习开销。其次,它们通常对用户流失具有鲁棒性。第三,秘钥共享通常不会影响训练模型的准确性。根据所遵循的体系结构,秘密共享解决方案可以分为两大类。
3.4.1
Single Server. 在这一类别中, secret shares将在客户之间分配。这种方法的主要优点是它只需要一个聚合服务器。SecAgg[7]是第一个研究联邦学习中的安全聚合问题的工作。然而,与常规聚合相比,SecAgg[7]大大增加了客户端的通信成本。SecAgg+[5]和FastSecAgg[21]降低了客户的通信成本。
3.4.2
Multiple Servers. 在第二类中,secret shares将分布在多个服务器而不是客户端之间。虽然这种方法需要至少一个额外的服务器来进行聚合,但这类客户端的通信成本远低于第一类。SAFELearn[13]依赖于秘密共享和同态加密。它讨论了一种通用的解决方案,该解决方案可用于大多数联邦学习算法,包括FedAvg[25],通过使用姚的加密电路或BMR协议。然而,它大大增加了训练过程的计算时间。SAFER[3]除了使用特定的聚合公式外,还使用压缩技术来降低客户端的通信成本,该公式只需要对添加操作进行安全评估。引入该聚合公式的主要原因是为了降低乘法安全评估的计算成本。然而,这个新公式只是在特定情况下对原始聚合公式的估计,并非在所有情况下都是如此。我们的工作FedShare属于第二类,采用了最近提出的SCOTCH[28]的思想,并使用了n-out-of-n 加性秘密共享技术。在以下部分中,我们将讨论SCOTCH[28]以及FedShare的不同之处。表1显示了现有解决方案之间的一般比较。
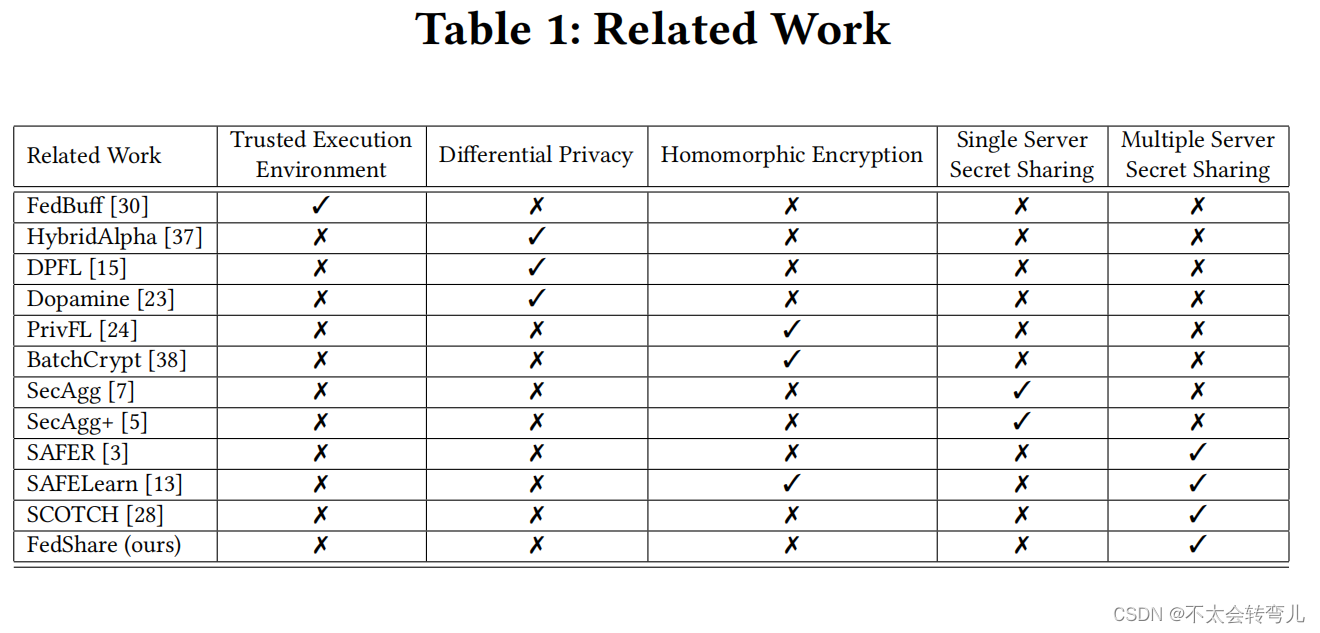
4 SCOTCH FRAMEWORK
由于FedShare是基于SCOTCH[28]的,我们将讨论该框架的架构,并以一轮训练为例。然后,我们讨论如何改进这个框架。SCOTCH[28]基于𝑛非串通服务器和𝑚客户。SCOTCH[28]和其他相关工作之间的主要区别之一是,SCOTCH[38]不需要客户端之间的任何类型的通信,因为它们不向彼此发送任何秘密或其他类型的信息。此外,虽然基于SMPC的解决方案需要服务器之间的通信[13],但SCOTCH[28]不需要服务器之间进行这种通信。总之,SCOTCH[28]中唯一的通信是客户端到服务器和服务器到客户端,但不需要服务器到服务器或客户端到客户端的通信。在SCOTCH[28]开始训练过程后,每个客户端𝑐 ∈{𝑐1, 𝑐2, …𝑐𝑚}训练一个ML模型经过E个epochs,使用SecureML[27]原语将训练后的模型从浮点域转换为整数域(可以看这个里面的定点数截断),并使用加法秘密共享创建n(服务器数量)个秘密共享。最后,每个秘密共享将被发送到相应的服务器。每个服务器计算客户端的秘密份额的加权总和,称为∑并发送∑/𝑛 到所有客户。最后,每个客户端可以通过将从所有服务器获得的 Σ/𝑛 总和转换为浮动域来计算下一轮训练的模型。这里我们用一个例子来让这个过程更加清晰。假设有三个客户𝑐1, 𝑐2 和 𝑐3台和两台服务器𝑠1和𝑠2。𝑐1,𝑐2,𝑐3训练模型,称为𝑊1,𝑊2,以及𝑊3。然后,C1将w1转到整数域。由于存在两个服务器,c1通过一个方式创建了两个secerts,
w
1
1
{w^1_1}
w11 和
w
1
2
{w^2_1}
w12 并且
w
1
1
{w^1_1}
w11 +
w
1
2
{w^2_1}
w12 = w1。然后c1将
w
1
1
{w^1_1}
w11 发送到s1,将
w
1
2
{w^2_1}
w12发送到s2。
c2和c3都遵循同样的方法。 c2 将 w 2 1 {w^1_2} w21 发送到s1,将 w 2 2 {w^2_2} w22发送到s2,c3将 w 3 1 {w^1_3} w31 发送到s1,将 w 3 2 {w^2_3} w32发送到s2。
然后,s1计算 σ 1 \sigma _1 σ1 = ( w 1 1 {w^1_1} w11 + w 2 1 {w^1_2} w21 + w 3 1 {w^1_3} w31)/2, 同时 s2 计算 σ 2 \sigma _2 σ2 = ( w 1 2 {w^2_1} w12 + w 2 2 {w^2_2} w22 + w 3 2 {w^2_3} w32)/2。 最终每个客户端从 s1 收到 σ 1 \sigma _1 σ1,从 s2 收到 σ 2 \sigma _2 σ2,并计算他们的和 r1 = σ 1 \sigma _1 σ1 + σ 2 \sigma _2 σ2, 再将 r1 转换回浮点域,并叫做 R1 ,使用𝑅1作为用于开始下一轮训练的模型的权重。SCOTCH[28]的最终模型的准确性低于FedAvg[25]。
根据他们论文中的报道,即使在独立和同分布(IID)和平衡数据分布的情况下,通过将MNIST、EMNIST和FMNIST数据集的客户端数量从2个增加到5个,模型的准确性也分别从97.5%下降到53%、98.5%下降到54.9%和85%下降到50%。这将在跨领域和跨设备的场景中成为一个问题,当数十、数百甚至数千个客户参与到训练过程中时。
此外,SCOTCH[28]没有考虑到每个客户拥有的培训记录的数量可能不同。实际上,客户对全局模型的影响应该与训练记录的数量成比例[25]。我们注意到,在对SCOTCH[28]框架的正式实施进行调查后,我们发现了一个严重的错误,这是通过增加客户端数量而失去准确性的主要原因。由于编程语言中存在传递引用和传递值的概念,该漏洞位于其实现的secret-sharing部分。通过在实现中修复该漏洞,训练模型的准确性将得到提高,但以下问题仍有待解决。
首先,它与不平衡的数据分布不兼容,因此,训练的模型与FedShare不兼容。其次,由于不必要的float到int和int到float转换,它将非常慢。第三,每个客户端的带宽使用率会高得多。
5 PROPOSED FRAMEWORK
基于SCOTCH[28]解决安全聚合问题的思想,我们引入了FedShare。与SCOTCH[28]相比,FedShare:
•在类似假设下提供完全平等的隐私保障。
•降低每个客户的通信成本𝑂(2𝑛)到𝑂(𝑛)哪一个𝑛是服务器的数量。
•在IID、非IID、平衡和不平衡设置中达到与FedAvg[25]完全相同的训练精度,远高于SCOTCH[28]。
5.1 Entities
我们考虑有𝑛个诚实但好奇的服务器和𝑚客户端。每个客户端 𝑐𝑖 拥有自己的私有数据集 𝑑𝑖 用于训练过程。此外,我们有一个外部服务器,称为主服务器 𝑆∗。主服务器 𝑆∗ 是一个与现有的任何 𝑛 个服务器都不同的服务器,或者它可以是 𝑛 个服务器中随机选择的任何一个,以降低新服务器的成本。与FedAvg[25]类似,我们考虑𝑇个培训轮次(round),每个客户端在每个轮次(round)中训练模型E个epochs。
5.2 Threat Model
与SCOTCH[28]类似,我们假设了一个被动安全的威胁模型,也称为诚实但好奇的威胁模型。所有实体(包括客户端、服务器和主服务器)都以“诚实”的方式行事,并正确遵循指定的框架规范。然而,这些实体中的任何一个都可能有意且好奇地试图通过检查从其他实体接收的数据来破坏隐私。
5.3 FedShare
在下文中,我们将讨论FedShare的主要步骤,如图1所示。
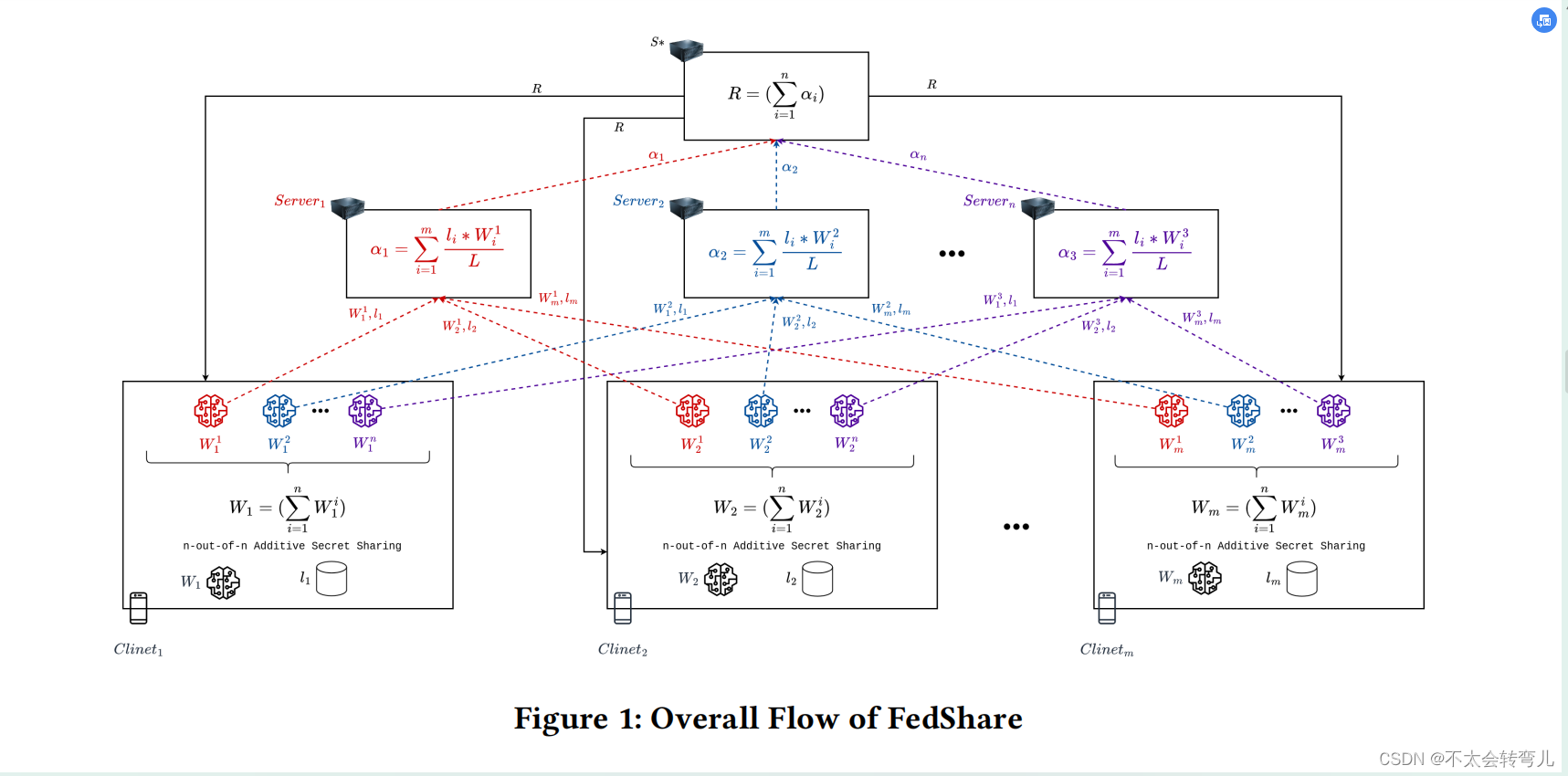
5.3.1 Local Training. 每个客户端 Ci 训练模型 Wi 进行 E 个Epochs。 然后, 每个客户端 Ci 从模型 Wi 的权重创建
w
i
1
{w^1_i}
wi1,
w
i
2
{w^2_i}
wi2,…,
w
i
n
{w^n_i}
win 的 secret shares。这些 secret shares的总和等于𝑊𝑖 如等式1所示。
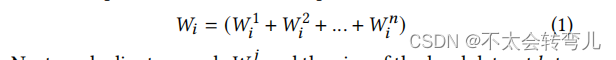
然后,每个客户端 Ci 发送
w
i
j
{w^j_i}
wij 和本地数据集大小
l
i
{l_i}
li 给服务器 Sj。 该过程如算法1所示。我们注意到
l
i
{l_i}
li 只会发送一次到服务器,不需要在每一轮训练中发送。与SCOTCH[28]相比,在创建浮点 secret shares时,我们不担心从浮点域到整数域的转换或其他方式。

5.3.2 Server Aggregation. 在完成本地训练阶段后,每个服务器 S𝑗 开始聚合 secrets。当每个服务器 S𝑗 接收到来自每个客户端 C𝑖 的
w
i
j
{w^j_i}
wij 后 ,它只是计算 secrets 的总和。此外,它通过将每个客户端的数据集大小
l
i
{l_i}
li 相加来计算总数据集大小,从而找到总训练记录数 𝐿。换句话说,𝑠𝑗 计算客户端 {C1,C2,…,Cm} 的第 𝑗 个秘密份额的加权总和。该权重总和被称为
α
j
{ \alpha _j}
αj, 如公式2所示:

这个过程在算法2中展示。每个服务器 𝑠𝑗 对每个客户 𝑐𝑖 的了解仅限于第 𝑗 个 secret share 和本地数据集的大小 𝑙𝑖 。由于每个服务器只能访问每个客户的一个份额,而不能访问其他份额,因此客户的隐私将得到保护。

5.3.3 Lead Server Aggregation.
每个服务器 𝑠𝑗 将服务器聚合的结果 𝛼𝑗 发送到主服务器 𝑆∗。接下来,𝑆∗ 根据公式3计算 𝑅。
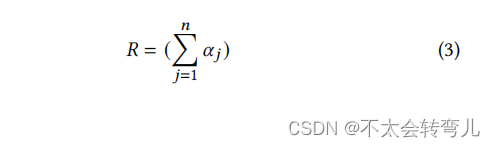
最后,𝑆∗ 将 𝑅 广播给客户,客户使用 𝑅 作为模型下一轮训练的权重,如算法3所示。

图2显示了我们提出的解决方案的高级版本。在高级版本中,我们随机选择其中一个服务器作为主服务器。因此,所选服务器既进行服务器聚合又进行主服务器聚合。因此,在FedShare中仍然提供相同的隐私保证时,不需要单独的主服务器。
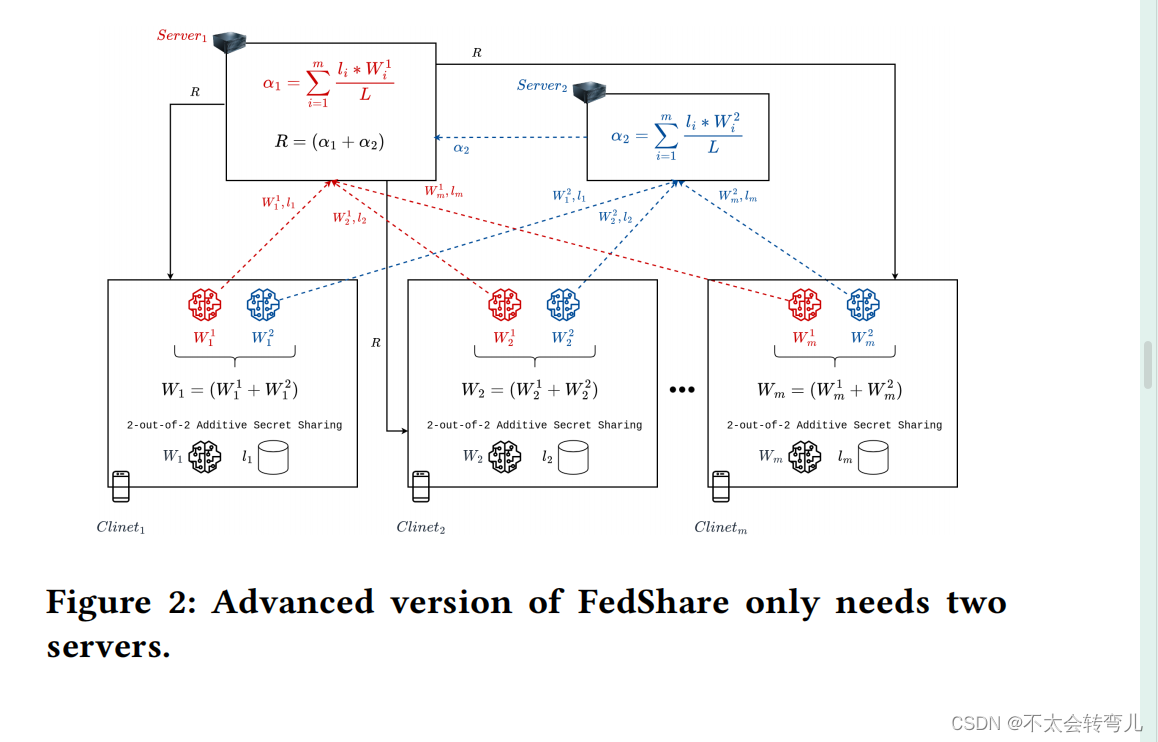
6 ANALYSIS
在接下来的章节中,首先我们讨论我们工作的隐私保证。接下来,我们展示我们的工作在每个训练轮结束时等同于 FedAvg [25]。最后,我们分析我们工作的通信成本,并将其与 FedAvg [25] 和 SCTOCH 进行比较。
6.1 Privacy Guarantee
我们的工作保证客户更新的隐私,只要满足以下两个条件:首先,至少有一个服务器不与其他服务器勾结。换句话说,如果所有服务器相互勾结,那么服务器可以重构(reconstruct 恢复出)secret,因为它们每个人都能访问一个份额,而所有秘密份额都分布在这些服务器之间。然而,如果即使有一个服务器不与其他服务器勾结,那么就会缺少一个秘密份额,那些勾结的服务器也无法重构秘密。第二,至少有两个客户不与其他客户勾结。如果所有客户相互勾结,除了其中一个客户之外,那么勾结的客户可以基于勾结客户的权重计算 𝑅,然后从基于所有客户的权重,包括勾结和非勾结客户的 原始 𝑅 中减去它。因此,他们将找到非勾结客户的原始模型更新。例如,两家不同的公司,比如亚马逊和谷歌,达成协议使用我们的框架。外,它们同意将谷歌(或亚马逊)视为 leader。通过这种方式,只要这两家公司不相互勾结,就能保护谷歌和亚马逊客户的隐私。此外,通过在过程中添加另一方,可以降低突破数据所有者隐私的风险。例如,每个欧洲国家的卫生组织可以提供一个服务器。通过这种方式,只要至少有一个卫生组织不与其他卫生组织勾结,所有客户的隐私(不仅是特定组织的一个客户组)将得到保护。
6.2 Equivalence to FedAVG
我们想要证明 FedShare 每轮训练结束时的结果确切等于 FedAvg [25]。我们证明了其中一轮的情况,但可以通过归纳法轻松地证明所有训练轮次。我们将 𝐶 = {𝑐1, 𝑐2, …, 𝑐𝑚} 定义为参与当前训练轮次的 𝑚 个客户的集合。考虑到FedShare和FedAvg [25]都使用完全相同的本地训练过程,我们将重点放在秘密分享和聚合过程上。因此,我们将 𝑊𝑐 视为由客户 𝑐 在本地训练的模型。
Theorem 1. 我们设 𝑃 是特定回合的FedAvg[25]的结果模型,以及 𝑅 是同一轮FedShare的结果模型,那么𝑃 = 𝑅.
Proof. 对于 FedAvg [25],下一轮训练将从公式4开始。
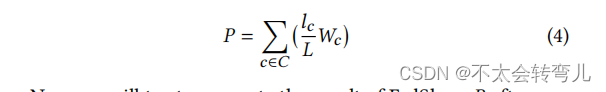
现在我们将尝试计算 FedShare 在一轮训练后的结果 𝑃。我们将 𝑆 视为包含 𝑛 个服务器的集合,将 𝑆∗ 视为主服务器。每个客户端从 W 中创建 n-out-of-n 的加法密钥份额。们用公式5表示客户 𝑐 ∈ 𝐶 对于服务器 𝑠 ∈ 𝑆 的秘密份额,记作
w
c
s
{w^s_c}
wcs。
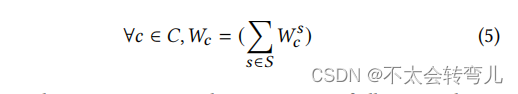
然后,每个服务器计算它从客户那里收到的所有秘密的总和,如公式6所示。
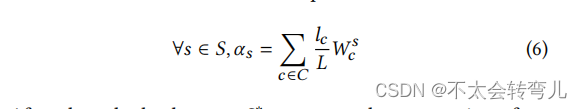
之后,主服务器 𝑆∗ 计算由服务器发送给它的 𝛼𝑠 的总和,如公式7所示。
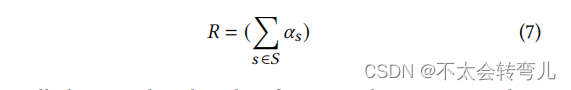
最后,通过展开 𝑅 的值,我们可以看到根据公式8,𝑅 = 𝑃。
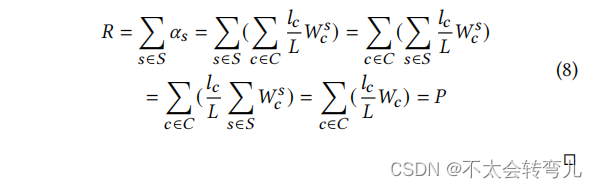
6.3 Communication Cost Analysis
现在我们想讨论在 FedShare 与 SCOTCH [28] 相比,客户的通信成本将减少多少。对于 SCOTCH [28],客户需要将秘密份额发送到 𝑛 个服务器,并再次从 𝑛 个服务器接收聚合的秘密。由于客户发送的秘密份额的大小(例如字节)等于其接收的聚合秘密的大小,我们可以将 𝛽 视为将要发送到服务器或从服务器接收的数据的大小。在 SCOTCH [28] 中,每个客户需要 𝛽𝑛 用于上传和 𝛽𝑛 用于下载,总共为 2𝛽𝑛。在 FedShare 中,虽然每个客户仍然需要将秘密份额上传到服务器,但只需要从主服务器下载 𝛽,总共为 (𝑛 + 1)𝛽。因此,与 SCOTCH 相比,使用 FedShare 的客户通信成本几乎减少了一半。(但服务器和主服务器之间的聚合也有通信,在此我倾向于实际过程中客户端数量会比服务器端多很多。)例如,当 𝑛 = 2 时,FedShare 客户需要的带宽减少了25%。这种改进对于较大的 𝑛 值更为有效。例如,对于 𝑛 = 5 和 𝑛 = 10,FedShare 客户分别需要少了40%和45%的带宽。此外,由于两个服务器之间的通信(例如,服务器与主服务器之间)通常比客户与服务器之间的通信快上几个数量级,因此FedShare还减少了训练时间。我们注意到这一改进仅仅是因为我们的架构。因此,其他技术,比如压缩,可以用来进一步减少通信成本。从数学角度来看,考虑 𝜃(𝐴, 𝐵) 作为将通过网络从节点 𝐴 发送到节点 𝐵 的对象的大小。在 SCOTCH [28] 中:
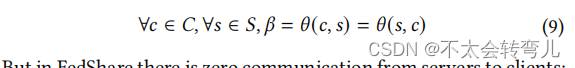
但在 FedShare 中,从服务器到客户的通信为零:
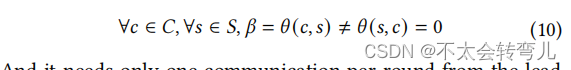
而且每轮只需要从主服务器到客户的一次通信,与服务器的数量无关:
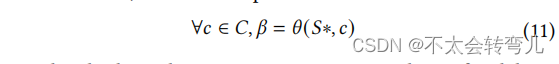
关于FedShare和SCOTCH [28]的通信成本分析的更多细节显示在表2中。表2中显示了服务器n和客户m的数量,分别用 𝑛 和 𝑚 表示,而 𝛽 是必须传输的数据的大小。
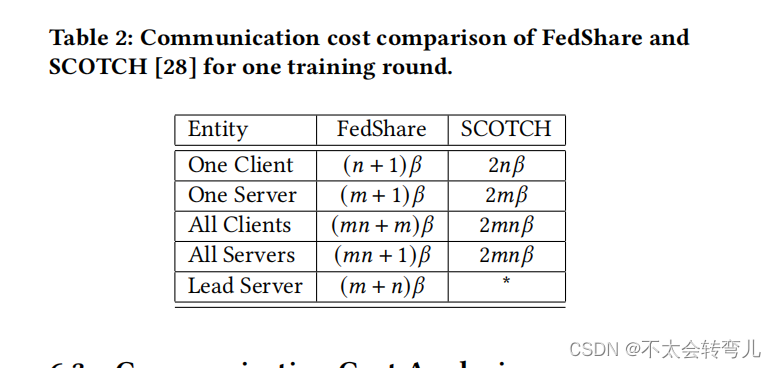
在FedShare中,每个客户在第一轮培训中向服务器发送一个额外的整数,表示训练记录的数量。我们在表中没有考虑它,因为它仅在第一轮培训中发生,而在剩余的轮次中不会发生。此外,这个数字所需的带宽比 𝛽 小一个数量级。
7 EXPERIMENTAL RESULTS
我们进行了不同的实验来展示FedShare是实用的,并且在具有高效通信成本的同时与FedAvg [25]同样有效。此外,我们将结果与SCOTCH [28]进行比较,以展示FedShare不受SCOTCH [28]的限制。我们的实现基于Python 3.8,Tensorflow 2.9.1和Flask 2.2。我们模拟了整个联邦学习过程,包括本地训练、聚合以及客户端和服务器之间的网络通信。此外,我们的源代码(https://github.com/v4va/FedShare)是公开可用的,供有兴趣重现我们结果的人使用。
7.1 First Experiment
由于我们想要将结果与SCOTCH [28]进行比较,我们在第一系列实验中考虑了与SCOTCH [28]相同的设置。使用MNIST、FMNIST和EMNIST数据集,训练了一个具有三个dense layer的神经网络。根据均匀随机分布,将训练数据平均分配给客户,以表示平衡和独立同分布的数据分布。学习率为0.01,本地的 epoch 为4。对于SCOTCH [28]和FedShare,服务器的数量为3。考虑到SCOTCH [28]的实验最多只涉及5个客户,我们使用了他们的原始实现来获取10、20和40个客户端的结果。然而,我们直接复制了他们在论文中报告的2、3、4和5个客户的结果。图3显示了训练模型的准确性。正如我们在数学上证明的,我们的结果表明,在所有三个数据集中,FedShare 和 FedAvg [25] 在性能上表现相似,即使有40个客户。另一方面,随着客户数量的增加,FedAvg [25] 与 SCTOCH 之间的差距也在增大。例如,在这些数据集上,使用具有20个客户端的 SCOTCH [28] 在这些数据集上训练的模型的准确度与随机猜没有什么区别。 这个实验清楚地表明,FedShare通过提供类似于SCTOCH [28]的隐私保证和FedAvg [25]的准确性,结合了两者的优势。

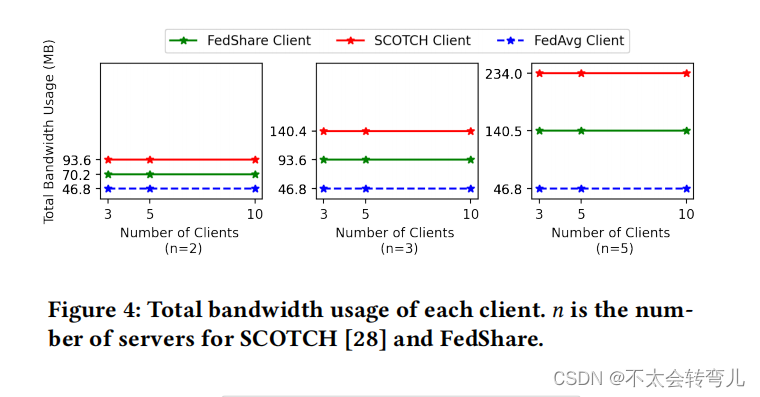
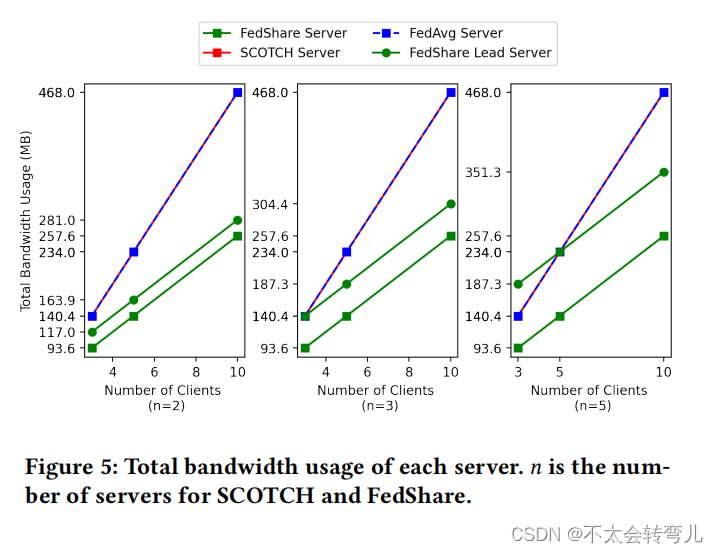
我们已经报告了这三种算法训练模型所需的带宽,以展示FedShare需要的带宽明显少于SCTOCH [28]。根据图4和图5,FedAvg [25] 在所有设置中都具有最低的带宽使用率,但它不支持安全聚合,这可能会破坏客户的隐私。这个实验表明,每个客户的通信成本对于FedShare和SCOTCH来说都取决于服务器的数量 (𝑛),但与客户的数量 (𝑚) 无关。此外,我们看到在SCOTCH和FedShare中,随着服务器数量的增加,客户的通信成本呈线性增加。然而,在最简单的设置下(𝑛 = 2),与SCOTCH [28]相比,FedShare客户需要的带宽少了25%。随着服务器数量的增加,SCOTCH和FedShare客户之间的通信成本差距也在增大。例如,当 𝑛 = 5 时,FedShare客户需要的带宽少了40%。表3显示了FedShare实体通信成本的更多细节,将上传和下载带宽分开。我们看到增加服务器的数量会线性增加客户的上传成本,但不会影响客户的下载成本。例如,当 𝑛 = 2 时,对于任意数量的客户,客户所需的下载带宽与 𝑛 = 5 时相等。
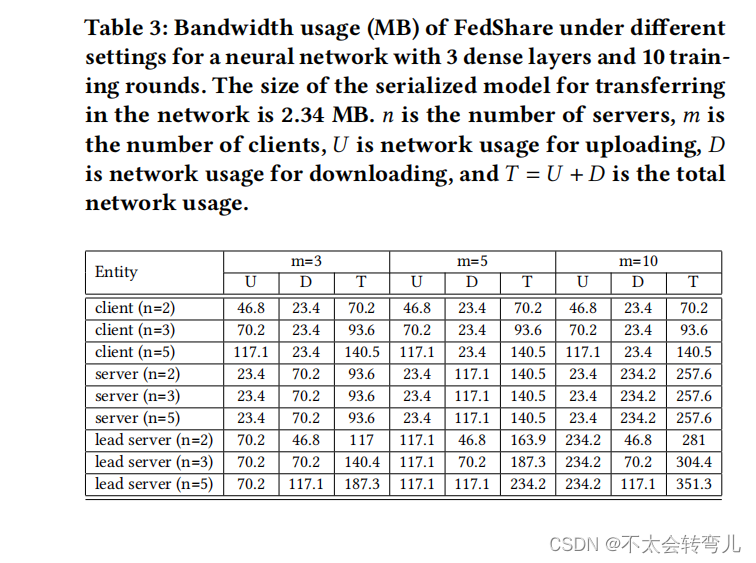
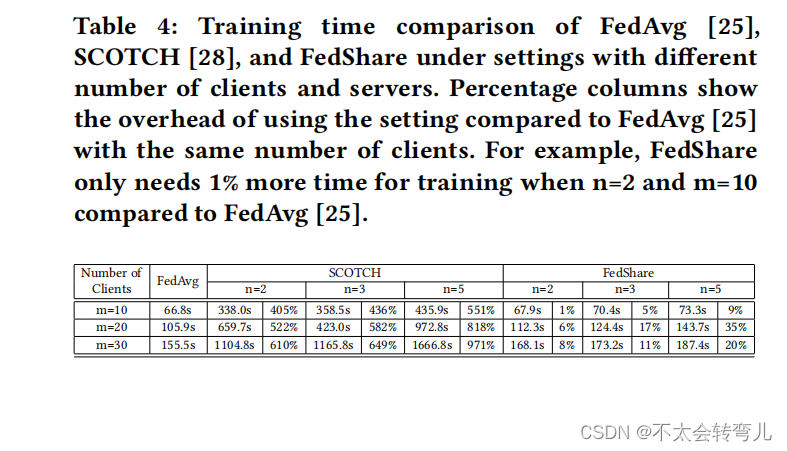
这三种算法的训练时间比较如表4所示。这些实验在一台搭载Intel Core i7-6700HQ处理器和Nvidia GeForce GTX 950M GPU,具有16GB内存的设备上运行。每个算法在MNIST数据集上进行五次实验的平均值,并进行了10轮训练的报告。虽然我们可以使用我们的工作的高级版本,因为它更快,不需要额外的主服务器,但我们使用了一个单独的主服务器来显示,即使在这种情况下,FedShare也比SCOTCH [28]快几倍,而且只比FedAvg [25]慢一点,这使得FedShare完全实用。例如,当我们考虑 𝑛 = 2,𝑚 = 30 时,我们发现虽然FedShare比FedAvg慢了8%(168.1秒对比155.5秒),但与SCOTCH [28]相比快了557%(168.1秒对比1104.8秒)。
7.2 Second Experiment
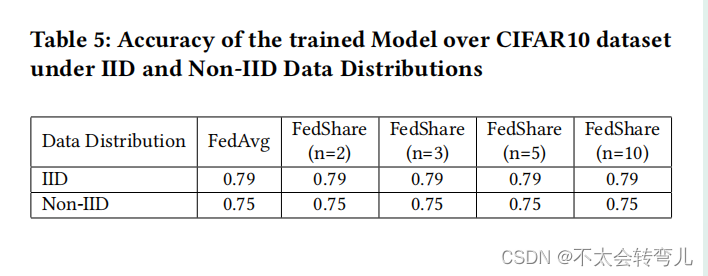
在第二个实验中,我们使用了CIFAR10数据集,该数据集有50,000个训练数据和10,000个测试记录,包含10个类别。我们使用FedAvg [25]和FedShare训练了一个包含16层的CNN模型,进行了5轮本地训练。对于FedShare,服务器的数量为2、3、5或10。我们考虑了10个客户之间的两种不同的数据分布设置。第一种数据分布是IID,其中数据集在客户之间均匀且随机地分布。对于第二种分布,我们根据标签对数据集进行了排序。因此,排序后,所有具有相同标签的记录将在一起。接下来,我们将数据集分为20个部分,并随机分配给每个客户两个部分。因此,每个客户将具有1或2个不同的标签,考虑到每个类别的记录数为5,000。根据表5,我们看到在IID或非IID设置中,FedShare的性能与FedAvg [25]相似。我们还看到增加服务器数量对训练模型的准确性没有任何影响。因此,FedShare适用于我们希望通过增加服务器(secrets share)来获得一个高隐私保证的的情况。
7.3 Third Experiment
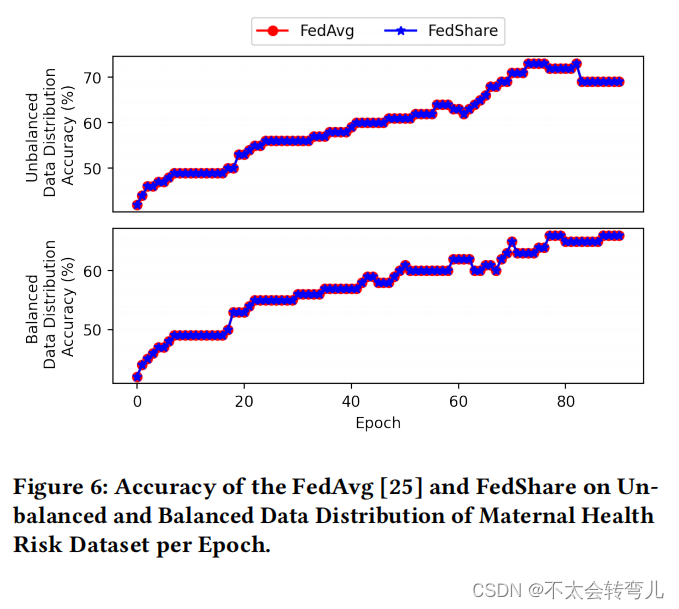
为了在非图像数据集上获得实验结果,我们在第三个实验中使用了母亲健康风险数据集[2],这是一个隐私敏感的数据集。这是一个具有7个特征和1014个记录的表格数据集。任务是将母亲的风险分类为低、中和高三个级别。我们将90%的数据用于训练,10%用于测试。此外,我们使用两种不同的方法将训练数据分配给10个客户,包括平衡和不平衡的分布。在不平衡的数据分布中,每个客户的训练记录数量是不同的。我们使用FedShare和FedAvg [25]对模型进行了90轮的训练。我们在图6中报告了每轮的模型准确性,而不仅仅是报告最终模型的准确性。除了我们的数学证明外,图6清楚地显示了在平衡和不平衡的数据分布下,FedShare每轮训练结束时的模型与FedAvg [25]完全相同。
8 CONCLUSION
FedShare是FedAvg [25]算法的一个版本,它通过确保隐私来解决了安全聚合的问题。我们的数学证明以及对各种数据集和设置的实验证明,使用FedShare和FedAvg [25]训练的模型的准确性没有任何差异。此外,FedShare在不对客户或服务器进行任何计算密集或通信密集的操作,具有合理的开销。由于FedShare的分散性质,它非常适合像区块链这样的环境。一个可能的研究领域是在Hyperledger Fabric等区块链平台上实现FedShare。















 2432
2432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









