







LLM 的局限性
1. LLM 的知识不是实时的
2.LLM 可能不知道你的私有领域及业务知识
如何增强模型的能力
既然模型的知识不是最新的,那我们能不能扩展他的知识,比如将数据库中的数据检索给他来增强它的能力? 答案是完全可以,这种通过检索的方法来增强生成模型的能力就是 RAG (Retrieval Augmented Generation)
如何做一个RAG?
1.将相关信息先进行检索,数据来源可以是你的数据,也可以是 ES 等检索引擎
2.构建 Prompt 将用户的问题以及检索到的信息喂给 LLM
3.LLM 根据已知的信息进行回复
接下来为了说明 RAG 的作用先上一个例子:
这里先封装一个 AIHelper
from openai import OpenAI
class AIHelper:
PROMPT_TEMPLATE = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
用户问:
{query}
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""
def __init__(self):
self.llm = OpenAI(
api_key="your key"
)
def get_completion(self, prompt, model="gpt-3.5-turbo-1106"):
response = self.llm.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
temperature=0,
max_tokens=1024,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0].message.content
def build_prompt(self, **kwargs):
return self.PROMPT_TEMPLATE.format(**kwargs)
if __name__ == "__main__":
ai_helper = AIHelper()
prompt = ai_helper.build_prompt(query="llama2 有多少参数?")
res = ai_helper.get_completion(prompt)
print(res)
运行上面的代码结果是
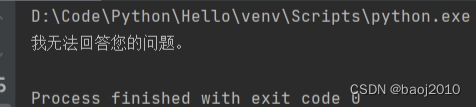
没错,gpt3.5 发布的时候 llama2 还没有发布,所以无法回答你的问题
接下来我们把 llama2 的知识喂给他
假如我们从数据库或者搜索引擎检索到了这些信息:
本文来自DataLearner官方博客:重磅!Meta发布LLaMA2,最高700亿参数,在2万亿tokens上训练,各项得分远超第一代LLaMA~完全免费可商用! | 数据学习者官方网站(Datalearner)
根据官方的介绍,Meta和Microsoft准备将LLaMA2引入到Azure公有云以及Windows本地上。目前已经在AzureAI上开放了LLaMA2系列的6个模型供大家使用。
LLaMA2模型的参数范围从70亿到700亿不等,在超过2万亿tokens数据集上训练。官方对齐微调的结果称为LLaMA2-Chat系列,专门针对场景优化。
接下来我们修改一下代码
from openai import OpenAI
class AIHelper:
PROMPT_TEMPLATE = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
{context}
用户问:
{query}
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""
def __init__(self):
self.llm = OpenAI(
api_key="your key",
)
def get_completion(self, prompt, model="gpt-3.5-turbo-1106"):
response = self.llm.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
temperature=0,
max_tokens=1024,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0].message.content
def build_prompt(self, **kwargs):
return self.PROMPT_TEMPLATE.format(**kwargs)
if __name__ == "__main__":
ai_helper = AIHelper()
knowledge = """
本文来自DataLearner官方博客:重磅!Meta发布LLaMA2,最高700亿参数,在2万亿tokens上训练,各项得分远超第一代LLaMA~完全免费可商用! | 数据学习者官方网站(Datalearner)
根据官方的介绍,Meta和Microsoft准备将LLaMA2引入到Azure公有云以及Windows本地上。目前已经在AzureAI上开放了LLaMA2系列的6个模型供大家使用。
LLaMA2模型的参数范围从70亿到700亿不等,在超过2万亿tokens数据集上训练。官方对齐微调的结果称为LLaMA2-Chat系列,专门针对场景优化。"""
prompt = ai_helper.build_prompt(query="llama2 有多少参数?", context=knowledge)
res = ai_helper.get_completion(prompt)
print(res)
再次运行上面的代码:
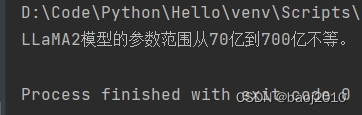
没错,现在 LLM 可以根据我们给他的信息来回答问题了。
原理就是这么简单
如何搭建一个知识体系并根据用户的query来检索得到最匹配的知识喂给大模型才是关键所在
如何搭建知识体系
搭建知识体系,说白了就是搭建一个检索系统,你可以用最暴力的方式,直接通过数据库中的模糊查询来取到匹配的数据,当然数据库不支持分词,最好是配合 ElasticSearch(简称ES) 这样的工具做一个关键词检索会比较好。将你数据库中的数据灌入到 ES 就能使用关键词搜索了
接下来假设你已经具备了这么个 ES 服务,我们通过代码示例来看看如何与 LLM 结合在一起为用户提供一个垂直领域的问答机器人
先封装一个 ESClient 用来检索数据
class EsClient:
def __init__(self):
self.client = Elasticsearch(
hosts=['服务地址'],
http_auth=('用户名', '密码')
)
self.index_name = "test"
def create_index(self, index_name):
self.client.indices.delete(index=index_name)
if not self.client.indices.exists(index=index_name):
self.client.indices.create(index=index_name)
return index_name
def save(self, paragraph_text):
index_name = self.create_index(self.index_name)
actions = [
{
"_index": index_name,
"_source": {
"keywords": self.to_keywords_zh(para),
"text": para,
"id": f"doc_{i}"
}
}
for i, para in enumerate(paragraph_text)
]
helpers.bulk(self.client, actions)
@staticmethod
def to_keywords_zh(input_string):
word_tokens = jieba.cut_for_search(input_string)
stop_words = set(stopwords.words('chinese'))
filtered_words = [w for w in word_tokens if not w in stop_words]
return ' '.join(filtered_words)
def search(self, query_string, top_n=3):
response = self.client.search(
index=self.index_name,
query={
"match": {
"keywords": self.to_keywords_zh(query_string)
}
},
size=top_n
)
return {hit['_source']['id']: {'text': hit['_source']['text'], 'rank': i} for i, hit in
enumerate(response['hits']['hits'])}上面代码用到了 jieba, elasticsearch7 库,可以通过 pip 自行安装
ESClient 提供了 save 方法,可以将文本灌入 ES 服务,search 方法提供了搜索功能
接下来就可以这么玩了:
if __name__ == "__main__":
ai_helper = AIHelper()
esclient = EsClient()
query="llama2 有多少参数?"
query_res = esclient.search(query, 4)
context="\n\n".join(v['text'] for k, v in query_res.items()
prompt = ai_helper.build_prompt(query=query, context=context)
res = ai_helper.get_completion(prompt)
print(res)没错就是这么简单
向量数据库
ES 数据库是通过关键词去匹配搜索结果的,如果关键词换成 英文:how manay parameters does llama2 have, 那 ES 里面可能就出不了结果了。
这个时候 向量数据库 就该登场了。
什么是向量数据库?
解释这个问题之前我们需要先了解什么是向量
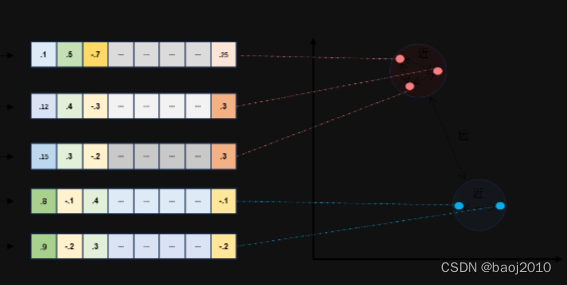
通常,我们将一个文本转成一组浮点数,每个下标 i,对应一个维度,假如这个数组长度是 1000,那我们就把这个数组想象成为一个 1000 维空间的一个点,这个过程用英文来表示叫 Embeddings
既然是空间的一个点,那么点和点之间是可以计算距离的,距离越近代表语义越相似。
如何向量化?
这又需要用到模型了,毕竟机器是不知道 parameter 和 参数 的意思是一样的,所以需要大量的数据进行训练,让这种相似的语义的词生成的向量之间的距离比较接近
提供一个向量化函数参考:
def get_embeddings(texts, model="text-embedding-ada-002", dimensions=None):
'''封装 OpenAI 的 Embedding 模型接口'''
if model == "text-embedding-ada-002":
dimensions = None
if dimensions:
data = client.embeddings.create(
input=texts, model=model, dimensions=dimensions).data
else:
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]如何计算向量之间的距离?
两种方法:余弦距离,欧氏距离
余弦距离就是夹角大小,夹角越小余弦值越大,也就是越相似
欧式距离是直线距离,直线越短越相似。
还是看代码:
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧氏距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)接下来测试一下
# query = "国际争端"
query = "global conflicts"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦距离:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:
print(l2(query_vec, vec))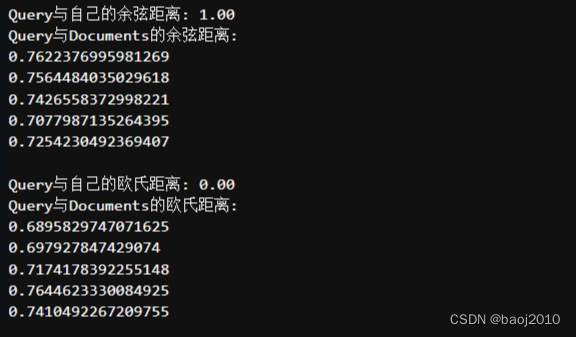
运行后可以看到,向量化后,检索就不受语言不同的影响了
不管是 global conflicts 还是 国际争端 都能匹配上 documents 中的前两条
解释清楚了向量,那么向量数据库就是存储这些向量的数据库了
下面模拟一个向量数据库与 LLM 结合的例子
import chromadb
from chromadb.config import Settings
class VectorDBHelper:
def __init__(self, collection_name, embedding_fn):
self.chroma_client = chromadb.Client(Settings(allow_reset=True))
self.collection = self.chroma_client.get_or_create_collection(
name=collection_name
)
self.embedding_fn = embedding_fn
def save(self, documents):
embeddings = self.embedding_fn(documents)
self.collection.add(
documents=documents,
embeddings=embeddings,
ids=[f"doc_{i}" for i in range(len(documents))]
)
def search(self, query, top_n):
embeddings = self.embedding_fn([query])
results = self.collection.query(
query_embeddings=embeddings,
n_results=top_n
)
res = zip(results['ids'][0], results['documents'][0])
return {id: {'text': text, 'rank': i} for i, (id, text) in enumerate(res)}
向量数据库工具类 VectorDBHelper,同样提供了两个方法,save 会将文本向量化并存到数据库中,search 会根据 query 搜索最匹配的记录返回
最终例子:
if __name__ == "__main__":
ai_helper = AIHelper()
vec_db= VectorDBHelper("test", embedding_fn=get_embeddings)
query="llama2 有多少参数?"
query_res = vec_db.search(query, 4)
context="\n\n".join(v['text'] for k, v in query_res.items()
prompt = ai_helper.build_prompt(query=query, context=context)
res = ai_helper.get_completion(prompt)
print(res)当然向量数据库并不是替代 ES 这类关键词数据库,向量数据库的问题是不够精准,在一些医学领域比如:非小细胞肺癌 会把 小细胞肺癌 查出来并放在第一位,这种场景 ES 反而效果更好。实际使用过程中往往是结合两者,将向量数据库及 ES 搜索得到的结果进行重拍返回最优结果。
关于这部分有兴趣可以关注私聊。
文中可能有疏漏之处欢迎指正















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









