







一、灰狼优化算法GWO(代码获取:底部公众号)
灰狼优化算法(Grey Wolf Optimization, GWO)是一种基于自然界灰狼群体行为的启发式优化算法。它模拟了灰狼群体在求解问题时的协作和竞争行为,通过模拟灰狼的觅食行为来优化问题的解。算法的基本思想是将问题的解空间看作是灰狼的生态系统,灰狼的位置代表解的位置,灰狼的适应度代表解的优劣。算法通过模拟灰狼群体中的四种行为(搜寻、围攻、追逐和逃避)来更新灰狼的位置,以找到更好的解。以下是灰狼优化算法的基本步骤:
-
初始化灰狼群体:随机生成一定数量的灰狼,并为每个灰狼分配随机的初始位置。
-
计算适应度:根据问题的特定适应度函数,计算每个灰狼的适应度。
-
更新灰狼位置:根据每个灰狼的适应度和其他灰狼的位置,更新每个灰狼的位置。这一步模拟了搜寻、围攻、追逐和逃避行为。
-
更新最优解:更新全局最优解,记录适应度最好的灰狼的位置和适应度。
-
终止条件判断:检查是否满足终止条件,例如达到最大迭代次数或达到预设的适应度阈值。
-
返回最优解:返回全局最优解作为算法的结果。
灰狼优化算法的优点包括简单易实现、收敛速度较快、对参数的选择不敏感等。它在许多优化问题上都取得了良好的效果,如函数优化、机器学习模型参数优化等。需要注意的是,灰狼优化算法作为一种启发式算法,并不保证能够找到全局最优解,而是寻找到较好的解。在应用该算法时,合适的参数设置和问题特性分析对于取得好的结果至关重要。
二、GWO优化BP流程
GWO算法优化BP神经网络的流程:
-
初始化灰狼群体:随机生成一定数量的灰狼,并为每个灰狼分配随机的初始位置。每个灰狼的位置表示神经网络的权重和偏置。
-
计算适应度:使用BP算法计算每个灰狼的适应度。适应度可以使用神经网络的性能指标,如均方误差(MSE)或分类准确率。
-
更新灰狼位置:根据每个灰狼的适应度和其他灰狼的位置,更新每个灰狼的位置。这一步模拟了搜寻、围攻、追逐和逃避行为。更新位置的过程可以使用一些标准的优化算法操作,如计算新位置的平均值、最小值或随机位置。
-
更新最优解:更新全局最优解,记录适应度最好的灰狼的位置和适应度。这个位置对应于神经网络的最佳权重和偏置。
-
执行BP算法:使用更新后的权重和偏置进行一次BP迭代,即前向传播和反向传播过程。根据训练数据计算梯度,并使用梯度下降算法更新权重和偏置。
-
终止条件判断:检查是否满足终止条件,例如达到最大迭代次数或达到预设的适应度阈值。如果满足条件,转到步骤 7,否则返回步骤 3。
-
返回最优解:返回全局最优解作为优化后的神经网络模型。
使用灰狼优化算法优化BP流程可能需要进行一些参数调整和实验,以找到最佳的算法配置。这包括灰狼数量、最大迭代次数、适应度函数选择等。同时,还应注意防止算法过拟合和选择合适的停止准则。
三、部分代码
SearchAgents_no=20; % 狼群数量
Max_iteration=40; % 最大迭代次数
dim=121; % 此例需要优化两个参数c和g
lb=-10*ones(1,121); % 参数取值下界
ub=10*ones(1,121); % 参数取值上界
% 节点总数
numsum=inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum;
lenchrom=ones(1,numsum);
bound=[-3*ones(numsum,1) 3*ones(numsum,1)]; %数据范围
Alpha_pos=zeros(1,dim); % 初始化Alpha狼的位置
Alpha_score=inf; % 初始化Alpha狼的目标函数值,
Beta_pos=zeros(1,dim); % 初始化Beta狼的位置
Beta_score=inf; % 初始化Beta狼的目标函数值,
Delta_pos=zeros(1,dim); % 初始化Delta狼的位置
Delta_score=inf; % 初始化Delta狼的目标函数值,
Positions=initialization(SearchAgents_no,dim,ub,lb);
Convergence_curve=zeros(1,Max_iteration);
l=0; % 循环计数器
h0=waitbar(0,'GWO优化BP即将完成,请等待...');
while l<Max_iteration % 对迭代次数循环
for i=1:size(Positions,1) % 遍历每个狼
% 若搜索位置超过了搜索空间,需要重新回到搜索空间
Flag4ub=Positions(i,:)>ub;
Flag4lb=Positions(i,:)<lb;
% 若狼的位置在最大值和最小值之间,则位置不需要调整,若超出最大值,最回到最大值边界;
% 若超出最小值,最回答最小值边界
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb; % ~表示取反
x= Positions(i,:);
% 计算适应度函数值
cmd = ['-w1 ',num2str(Positions(i,1)),' -B1 ',num2str(Positions(i,2)),' -w2 ',num2str(Positions(i,3)),' -B2 ',num2str(Positions(i,2))];
fitness=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn);
if fitness<Alpha_score % 如果目标函数值小于Alpha狼的目标函数值
Alpha_score=fitness; % 则将Alpha狼的目标函数值更新为最优目标函数值
Alpha_pos=Positions(i,:); % 同时将Alpha狼的位置更新为最优位置
end
if fitness>Alpha_score && fitness<Beta_score % 如果目标函数值介于于Alpha狼和Beta狼的目标函数值之间
Beta_score=fitness; % 则将Beta狼的目标函数值更新为最优目标函数值
Beta_pos=Positions(i,:); % 同时更新Beta狼的位置
end
if fitness>Alpha_score && fitness>Beta_score && fitness<Delta_score % 如果目标函数值介于于Beta狼和Delta狼的目标函数值之间
Delta_score=fitness; % 则将Delta狼的目标函数值更新为最优目标函数值
Delta_pos=Positions(i,:); % 同时更新Delta狼的位置
end
end
a=2-l*((2)/Max_iteration); % 对每一次迭代,计算相应的a值,a decreases linearly fron 2 to 0
for i=1:size(Positions,1) % 遍历每个狼
for j=1:size(Positions,2) % 遍历每个维度
% 包围猎物,位置更新
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % 计算系数A,Equation (3.3)
C1=2*r2; % 计算系数C,Equation (3.4)
% Alpha狼位置更新
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % 计算系数A,Equation (3.3)
C2=2*r2; % 计算系数C,Equation (3.4)
% Beta狼位置更新
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % 计算系数A,Equation (3.3)
C3=2*r2; % 计算系数C,Equation (3.4)
% Delta狼位置更新
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
% 位置更新
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
end
l=l+1;
Convergence_curve(l)=Alpha_score;
waitbar(Max_iteration,h0)
end
close(h0)四、仿真结果
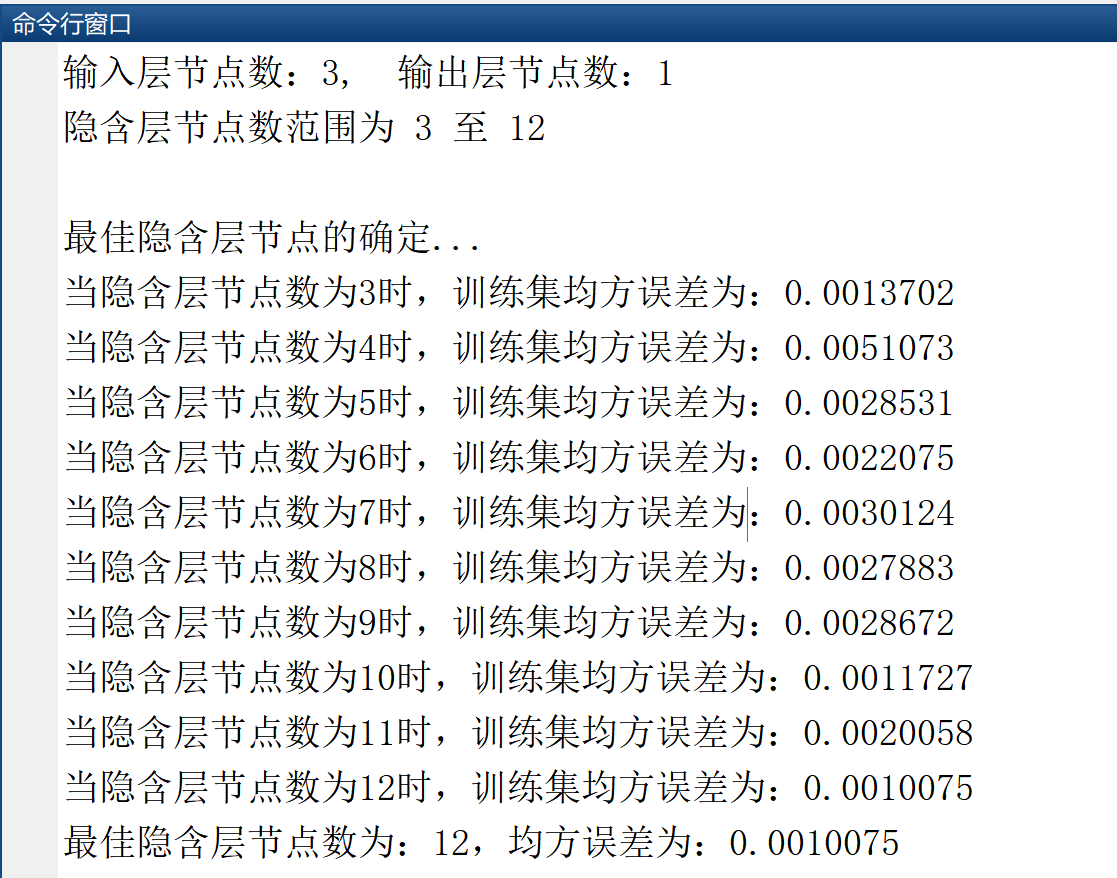
(1)根据经验公式,通过输入输出节点数量,求得最佳隐含层节点数量:
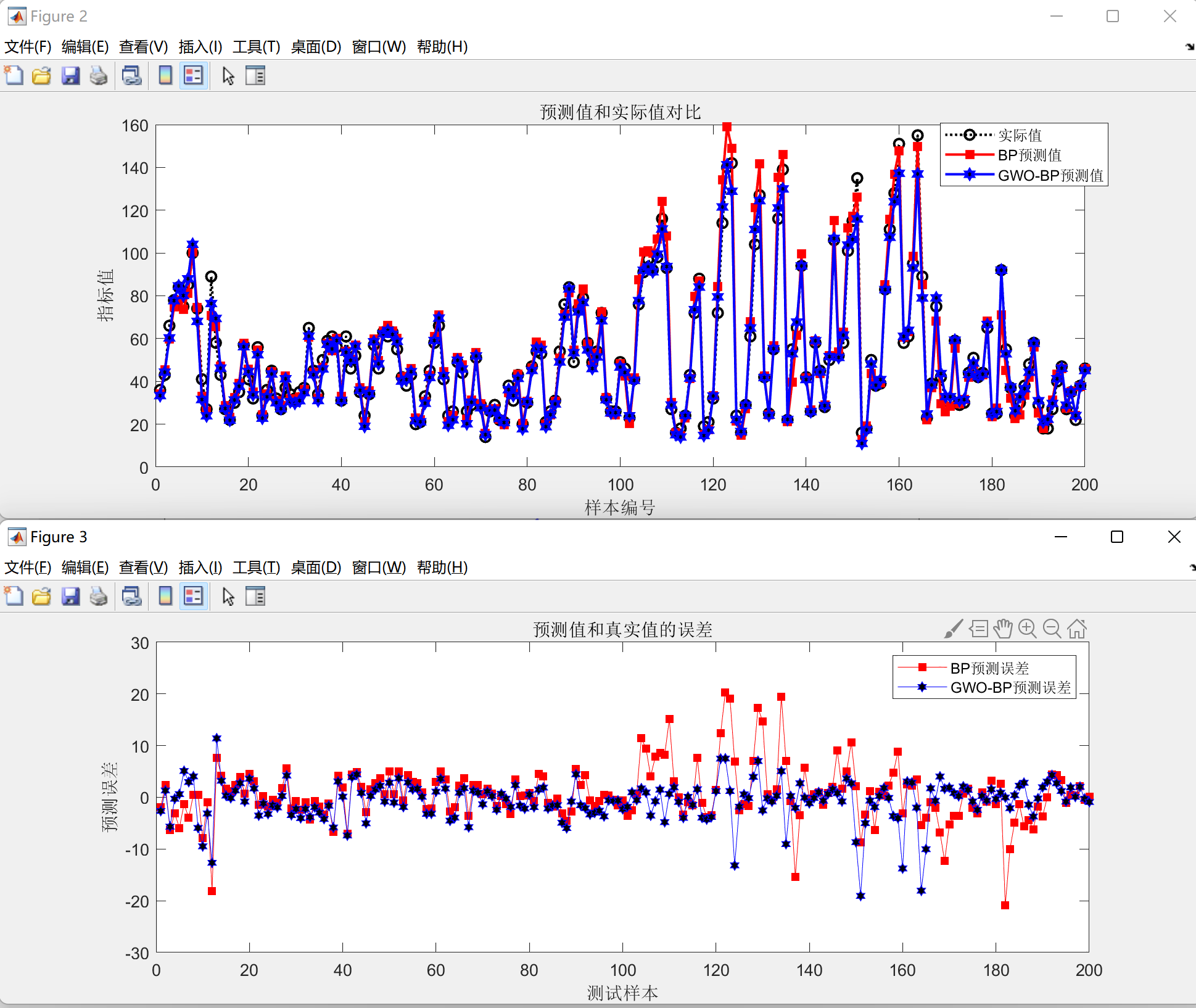
(2)BP和GWO-BP的预测对比图和误差图
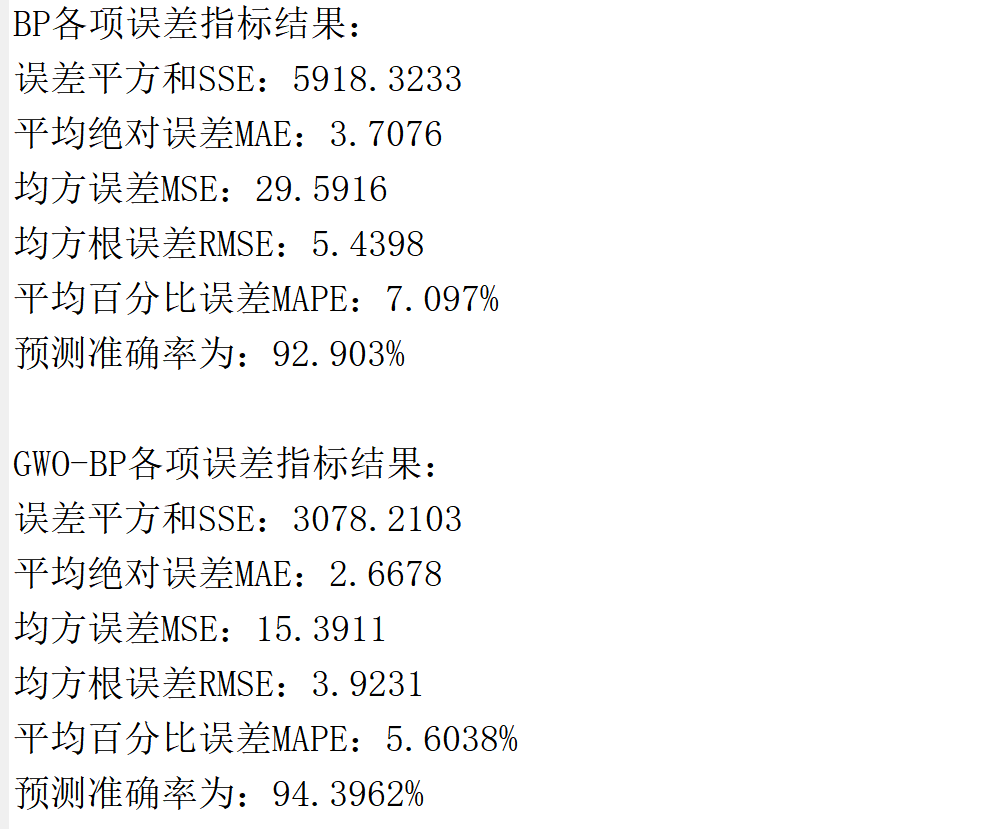
(3)BP和GWO-BP的各项误差指标
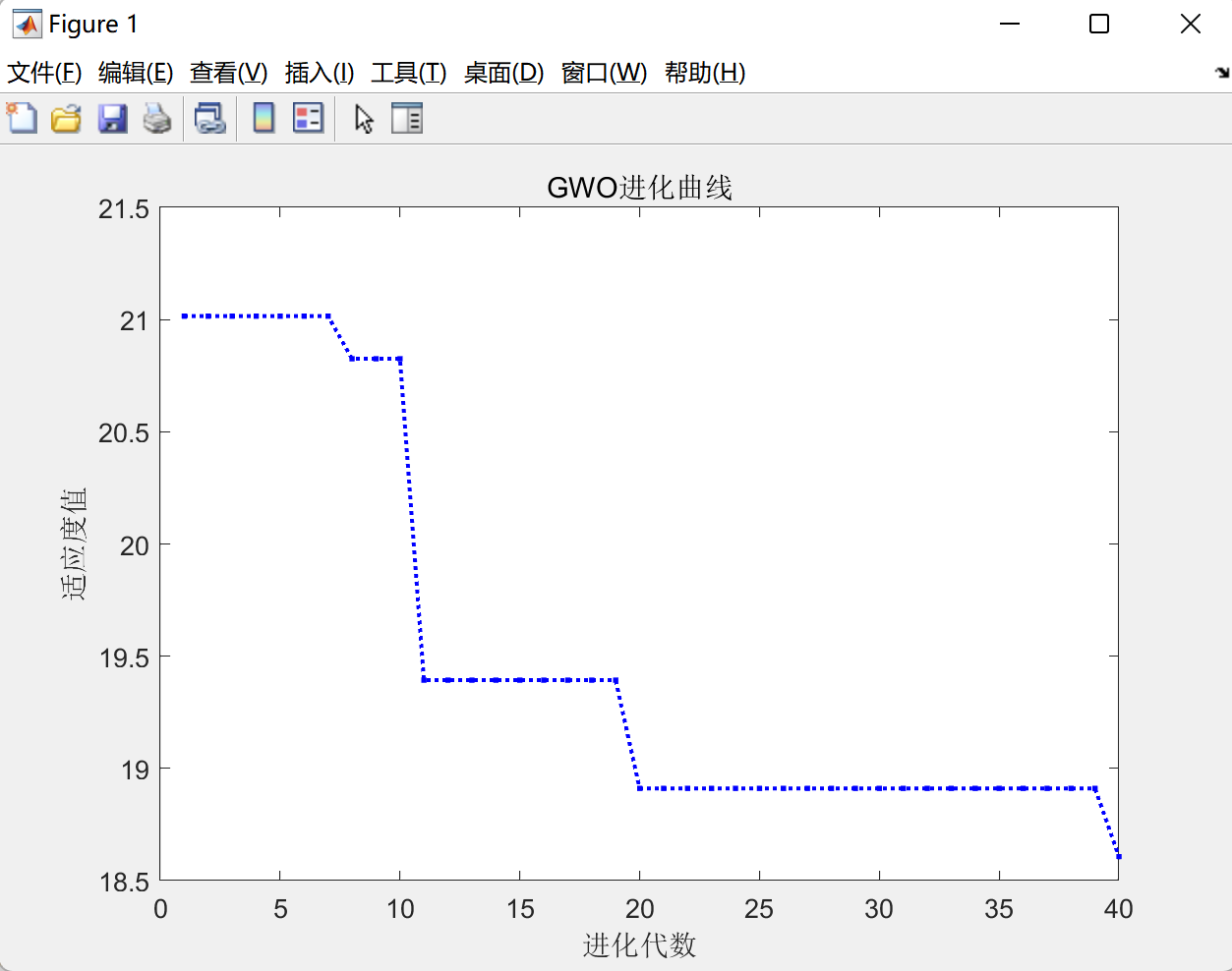
(4)灰狼优化算法GWO适应度进化曲线
(5)BP和GWO-BP模型的回归图

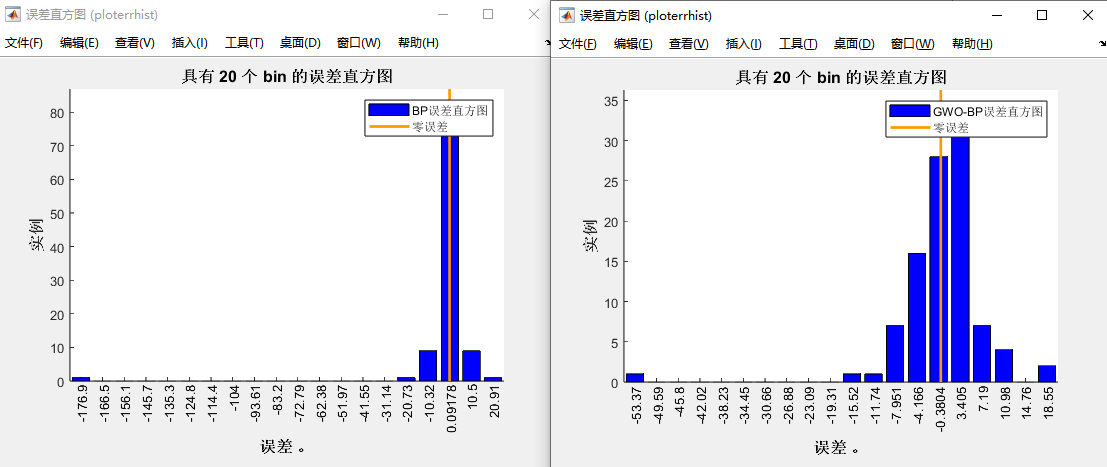
(6)BP和GWO-BP模型的误差直方图
五、BP算法优化
| BP算法优化 | |
| 遗传算法 GA-BP | 灰狼算法 GWO-BP |
| 鲸鱼算法 WOA-BP | 粒子群算法 PSO-BP |
| 麻雀算法 SSA-BP | 布谷鸟算法 CS-BP |


















 5008
5008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











