







学习基础,就是打牢基础知识部分。

1 《深度学习》简介
2 线性代数
2.1
基本概念:有标量、向量、矩阵、张量
2.2
基本概念:hadmaard乘积、点积、
矩阵有矩阵乘积这种运算,满足分配律和结合律,不满足交换律。但是两个向量乘积满足交换律。(因为两个向量点积是标量。)
2.3 单位矩阵和逆矩阵
2.4 线性相关和生成子空间
解释Ax=b发生了什么?
我们可以理解为b为一组向量A的生成子空间,是原始向量线性组合抵达的点的集合。
所以Ax=b是否有解非常重要。
2.5 向量大小
2.7 特征分解
将矩阵分解成一组特征向量和特征值。
判断其能不能分解的条件?
2.8 奇异值分解
矩阵分解为奇异向量和奇异值。
2.10 迹运算
2.12 主成分分析(重温理论推导过程)
讨论了PCA的编码和解码函数。
并且使用输入和输出的L2范数来知道最优的编码函数就是一个D即可。在L2范数下最优编码x只需要Dx即可。
请参考http://blog.codinglabs.org/articles/pca-tutorial.html这个博客讲的很不错。
PCA的提出愿景
这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。
上面给出的是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。例如,我们到底删除哪一列损失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始数据决定具体的降维操作步骤
PCA算法的步骤

但我们关心的是为什么?这样就可以降维?
PCA原理
1 首先我们先理解Ax=b表示的意义,它表示x经过A作为基变换到A展开的空间中,表示为b。
2 然后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。而且如果基的数量少于向量本身的维数,则可以达到降维的效果。
3 但是如果选择最好的基来达到降维的效果呢?或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
一种直观的感觉就是,这个基一定是线性无关且能投影后的投影值尽可能分散。这可以用方差量化它,寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
或者说将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)
4 所以我们需要找到一个矩阵P,使得PX=Y。让X经过P变换之后到变成Y,而Y的协方差矩阵D是对角化的? 这是目的。而我们又发现D跟X的协方差矩阵C有关系。D=PCPT,所以我们要找的就是能让C对角化的P。在矩阵中,让C对角化的就是它的特征向量了,而根据选择特征向量的数目来完成降维。
问题:
3 概率和信息论
3.2 随机变量
4 数值计算
4.1 上溢和下溢出
4.3 基于梯度的优化方法
5 机器学习基础
5.1 学习算法
简洁的定义:对于任务T和性能度量P,一个由计算机程序在经验E中学习指的是,经过E改进,它在T上P有提升。所有的东西任务、经验、性能度量不一致而已。
5.1.1 任务分类
分类
输入缺失分类
回归
转录:语音识别
机器翻译
结构化输出:
异常检测:
合成和采样:
缺失值填补:
去噪:
密度估计:
5.1.2 性能度量
5.1.3 经验
主要有无监督和有监督算法
5.2 容量、过拟合和欠拟合
它们之间的关系:可以借助统计理论得到一些东西,那就是假设训练集和测试集都在同一个数据生成分布中。那我们知道训练误差和测试误差的期望是一致的。那如何降低训练误差(欠拟合)或者缩小训练误差和测试误差的差距(过拟合)呢?
可以通过改变容量来防止过拟合或者欠拟合,也有很多方法可以控制模型的容量,比如改变输入特征或者加入特征对应参数都可以。
1 有其它方法能够处理过拟合和欠拟合嘛?比如动态调整?
2 只要用机器学习就一定要面临过拟合和欠拟合?
3 容量可以量化嘛?
减小泛化误差(测试误差):我们希望泛化误差尽可能的小(提高泛化能力),怎么办呢?
我们必须记住奥卡姆剃刀原则,越简单的泛化误差越好。有一种VC维可以量化模型容量,但是其理论边界太大。
1 其他减小泛化误差的方式?
2 其他量化模型容量的理论?
3
泛化误差和容量的关系:泛化误差是一个关于模型容量的U型函数。左边是欠拟合区域,右边是过拟合区域。
1 只是一个简单的分析而已,根本没有什么用的。我们仅仅知道这是个U型函数,但是无法量化
2
对于容量无限大情况的讨论:
我们可以将参数学习算法嵌入到另一个增加参数数目的算法来创建非参数学习算法。比如外循环调整多项式系数(容量),内循环通过线性回归来做。
1 这其实就是动态的调整容量来达到比较好的分类效果而已。训练时间长,在不知道容量情况下
5.2.1 没有免费午餐定理
没有万能的模型,机器学习目标不是找一个通用的算法,而是理解什么样的先验分布与真实世界有关,以及什么样学习算法在该数据分布上效果最好。
这不就是算法书上原话嘛?
5.2.2 正则化
正则化(英语:regularization)是指为解决适定性问题或过拟合而加入额外信息的过程
目的: 是为了降低泛化误差。
- L1正则化是指权值向量w ww中各个元素的绝对值之和,通常表示为∣ ∣ w ∣ ∣ 1 ||w||_1∣∣w∣∣1
- L2正则化是指权值向量w ww中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为∣ ∣ w ∣ ∣ 2 ||w||_2∣∣w∣∣2
1 是为了控制权值向量而设定的。
5.3 超参数和验证集
5.3.1 交叉验证
目的: 是当数据集太小,L具有过高的方差时候用的。
理论基础:
5.4 估计、偏差和方差
5.4.1 点估计
点估计为一些感兴趣的量提供单个“最优”预测。
5.4.2 偏差
有无偏和渐近无偏两种。
5.4.4
5.11 促使深度学习出现的挑战
传统机器学习不行的原因是对于很多问题,传统机器学习泛化能力差。
1 还有其它原因促使深度学习的出现吗?
2 传统机器学习泛化能力差的典型例子?如何理论化?
3
第6 章 深度前馈网络
1 为什么深度网络可以非线性?因为有激活函数。
2 有没有其他像深度学习一样的工具? 深度学习的策略是学习函数映射,其中有两种参数,一个是从一大类函数中选择某种函数,一个是学习这个函数的参数。前者表示隐藏层,后者表示w。

6.1
我们看下一个简单的前馈神经网络是什么解决XOR函数问题的就可以了。
1 如何训练参数?
2
6.2 基于梯度的学习
1 神经网络和传统机器学习的优化算法有什么不同?
2 为什么用概率论的东西来设计loss函数呢?
6.2.1 代价函数
Loss function无非就是2个方面,首先,要反应你所应用的领域的ground truth,至少是你假定的ground truth,如果有多个ground truth,要根据你想要的方向来取舍。第二,loss function要有合理的梯度,可以被求解
0-1损失函数(0-1 lossfunction), (2)感知损失函数(Perceptron Loss),(3)平方损失函数(quadratic loss function),(4)Hinge损失函数(hinge loss function),
(5)对数损失函数(Log Loss):
对数损失, 即对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是在概率估计上定义的.它常用于(multi-nominal, 多项)逻辑斯谛回归和神经网络,以及一些期望极大算法的变体. 可用于评估分类器的概率输出.

交叉熵损失函数为什么好?

1 这个结果简单漂亮,但就是一步的求导。所以可以直接在代码中写出来,因为代码不会求导,只能根据求导公式硬编码出来。。这。
2 其实python实现求导只需要硬编码基本求导法则和构建计算图两个部分,然后进行传播就可以了。。。。。https://zhuanlan.zhihu.com/p/103383643
应该是用树实现的求导的。
2 还有就是https://zhuanlan.zhihu.com/p/35709485说交叉熵函数是凸函数,我就很好奇,如何证明一个函数是凸函数呢?
单输出网络
条件为:全连接、单输出、最小二乘法、sigmod函数

多输出情况下

多层正向和反向传播

参考:
https://zhuanlan.zhihu.com/p/36503849
损失函数设计,比较好懂一些
https://zhuanlan.zhihu.com/p/35709485
交叉熵损失函数为什么好的解释
2017Feed Forward and Backward Run in Deep Convolution Neural Network被17
CNN的卷积公式和前向传播和反向传播的详解论文(非常推荐看,看这个懂所有。)
https://blog.csdn.net/z_feng12489/article/details/89187037
这个是一个简单单层和多层MLP的正向和反向传播的公式,就是看这个推导公式的。挺有意思的。
https://zhuanlan.zhihu.com/p/32819991
非常好的例子推算多层MLP反向传播,看懂了误差项的来由。最详细的反向传播了。
6.3 隐藏单元设计
并没有过多的指导,更多的是经验。 对比各种激活函数及其性能。
6.3.1 整流线性单元及其扩展
比如整流线性单元在x=0处,不可微。 (可微意味着连续,连续不一定可微)可微也意味着在该点有导数。
常用的有Sigmoid、tanh(x)、Relu、Relu6、Leaky Relu、参数化Relu、随机化Relu、ELU。
其中,最经典的莫过于 Sigmoid函数 和 Relu函数 。
最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
还有,通常来说,很少会把各种激活函数串起来在一个网络中使用的
6.4 架构设计
它应用具有多少单元,以及单元如何连接?
6.4.1 万能近似性质和深度
指的是:如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 ℝn 的紧子集 (Compact subset) 上的连续函数。尽管如此,此定理并没有涉及到这些参数的算法可学性 (Algorithmic learnablity)。注意任意近似和连续。Goodfellow的言外之意是说,“广而浅薄”的神经网络在理论上是万能的,但在实践中却不是那么回事。因此,网络往“深”的方向去做,才是正途。(这个议题,回头我们再深入探讨)
6.5 思考
1 显然,对于输出是一个向量来说。需要有多个输出神经元,那么w如何更新?
2 全连接和部分连接区别?
3 理论证明,两层神经网络可以无限逼近任意连续函数。为什么?单层网络只能够拟合什么函数?单层只能够拟合线性函数,这也就是单层神经网络不能解决异或问题的原因。
但是两层就可以无限拟合??
首先有结论:
1 分段线性函数可以拟合任意连续函数,如何理解?用这个结论来理解两层神经网络拟合任意参数。
2 在人工神经网络领域的数学观点中,「通用近似定理 (Universal approximation theorem,一译万能逼近定理)」指的是:如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 ℝn 的紧子集 (Compact subset) 上的连续函数。
注意,以下为定理,这个定理告诉我们,任意线性有足够高精度逼近一个连续函数。有点像MCMC的理论基础。

1 在数学有数值计算这个领域,能够结合这个指导设计不一样的神经网络呢?
2
6.5 反向传播的计算图
参考:
1 https://www.bilibili.com/video/BV1kE4119726?p=9
花书的同济子豪兄看的
https://bigquant.com/community/t/topic/113287
万能近似定理的一个解释
http://neuralnetworksanddeeplearning.com/chap4.html
视觉证明万能近似定理(篇幅较长)
7 深度学习的正则化
主要是为了防止过拟合。

7.1 参数正则化
7.2 数据增强:
当数据量不多时,可以对原始数据做各种操作来扩充数据集,获取原始数据的方方面面的东西。
7.3 模型集成:
类似于随机森林。
7.4 dropout:
每个神经元都有一定概率被掐死。可以防止过拟合?
解释:
1 每个神经元都有机会和所有合作,减少神经元的专一性。
2 留下来的就是它大而化之的经验。
3 会有2的n次方的模型集成。
4 达到数据增强的效果。
5 引入稀疏性
7.5 早停:
在它快要过拟合就停止住。

参考:
https://www.bilibili.com/video/BV1kE4119726?p=10
b站一个同济大学的
8 深度模型的优化
基础知识:

我们其实想要优化的是基于某个概率分布生成的数据loss函数最小,但是我们其实不知道真实数据分布,只能够有训练样本靠优化来做,这是知乎的一个解释,关于梯度下降为什么能够收敛的回答。挺好的


1 机器学习问题可以变成优化问题去解。 也就是说,也可以转成其他问题去解决?
2 机器学习的优化问题一般都是基于梯度下降来解的。 也就是说,优化还有其他方法来解?
8.1.3 批量算法和小批量算法
纯优化问题一般是在可行解中找到最优解,而机器学习的loss是在训练样本上的和。
所以自然而然可以用小样本逐次训练,而批量的大小由精确梯度、多核架构、并行性决定的。
小样本的随机性抽取非常重要,很多样本之间高相关。要去除掉。
额外的遍历也会带来诸多好处,当训练样本数目增长的时候,泛化误差上计算瓶颈会有诸多影响。有论文在这方面工作。
8.2 优化的挑战
8.2.1 病态
病态以及使用牛顿法解决病态问题。
8.2.2 局部最小值
排除局部最小值是主要问题的检测方法是画出梯度范数随时间的变化。
还有鞍点、悬崖、长期依赖、非精确梯度、局部和全局结构的弱对应。
1 既然在高维空间中有这么多问题,花书建议在传统优化算法上研究怎样选择更佳的初始化点更好。这样就更好趋向比较好达到最小值
2 如何研究优化算法性能上界? 近似算法是可以的,
8.3 基本算法
深度学习的优化器基本框架

后续的优化器都在这个基本框架上有不同形式
8.3.1 SGD 介绍(1847)

2 SGDM(借助惯性冲出局部最小值)

这个图中,就表示了梯度、momentum、和真实movement,在第二个球的时候,这个时候比较平,梯度比较小,如果是SGD的话说不定就停在这里。但是SGDM来说,它就会计算之前的一定时间的趋势,进而借助惯性冲出去到第三个球。
思想就是:记住histroy和往前多看一些总是好的。
3 Adagrad(克服走太快的缺点)

在图中就是走的太快了,所以加一个分母,记录之前的梯度平方和再开平方。防止之前步子太大,然后跳过最优值点。
4 RMSprop

思想:克服Adagrad分母太大,有时候就特别小步的走,因为分母一直在增加。
5 Adam

6 优化器实际应用
BERT:用ADAM训练
Transformr:用ADAM
Tacotron:用ADAM
YoLo: 用SGDM训练
Mask-R-CNN: SGDM
ResNet: 用SGDM训练
Big-GAN: 用ADAM训练
MEMO:用ADAM训练


以上都是Adam和SGDM对比

后来有人使用Adam和SGDM结合版本使用。

还有人提高Adam,比如https://www.bilibili.com/video/BV1Bz411B7kR?p=2视频说的2018的一些论文。
还有人提高SGDM,比如
1 3,4,5都是自适应改学习率的,都是2014年之后提出,为什么2014之后根本没有新的优化器????
2 提出的都没有超过ADAm,因为它们抢到了最新的位置。关注于Adam和SGDM的区别和对比。
3
4 其他优化算法
如果只是简单做优化的话,那么凸优化是有理论指导的。所以我们有能力把非凸变成凸,后面就是凸优化的事情了。
1 随机梯度下降的理论推导过程?
上面已经回答了。但是具体的优化过程不知道。
2 经典的神经网络优化算法?
3 把神经网络比作函数生成器的话,那么每个样本的输入都是在让这个函数生成器工作一次? 可不可以更好?
这就是优化算法的不同了。
4 激活函数的意义?
5 loss的种类以及区别?
6
参考:
https://www.bilibili.com/video/BV1Bz411B7kR?from=search&seid=1562094829455358917
李宏毅的优化器视频

8.1 神经网络训练会遇到的问题
问题: 高维、非凸、参数空间巨大
导致的结果:震荡、局部最优值、鞍点、过拟合、梯度消失、梯度爆炸。
8.2 梯度下降
8.3 一阶优化器
山抖不抖
8.4 二阶优化器
一般不会用

关于B站的深度学习详解
1 神经网络的结构
最经典的神经网络架构就是MLP,而最经典的例子,就是手写数字识别的例子。
神经元就是装数字的容器,装的就是激活值。整个神经网络就是一个函数器,里面每个神经元都是一个函数计算器。

上图是一个典型的一层神经网络的计算方法,我惊讶的是这不就是把输入变换到一个W张开的空间中,然后激活函数让它在那个空间中又非线性了吗?
问题?
1 为什么要分层?我们为何设计这个结构?
我们可能的期望是:比如对于手写数字识别例子来说。每一层都可以抽取到数字的某个部分或者边缘,然后在最后一层组合起来得到想要的结果。
实际上: 我们不知道如何工作的。
2 为什么可以做到智能判断?
3 神经网络就是一个函数器,我们仅仅知道如何设置这个机器中的参数就行了。神经元就是数字的仪器。
4 使用sigmod函数的意义?
5
2 神经网络如何训练?
1 最经典的反向传播算法,
那么最经典的例子就是手写数字的识别。对于它来说,每个样本都是单独输入到一个神经网络中,每个样本都会经历一次反向传播,进而每个样本都会对参数进行修改。
梯度更新公式不是推导而是创造然后定义出来的。理解这个你需要知道
1)导数 通俗理解为f(x)沿着正方向的一个变化率
2)偏导数 通俗理解为f(x1,x2、xn)沿着某个x正方向的变化率。
3)方向导数 通俗理解为f(x1,x2、xn)沿着所有x合方向的变化率。(也可以说是某一趋近方向的导数值)
4)梯度 梯度是一个向量,有大小与方向。 梯度的方向是最大方向导数的方向; 梯度的值是最大方向导数的值
5)梯度下降法 既然在变量空间的某一点处,函数沿梯度方向具有最大的变化率,那么在优化目标函数的时候,自然是沿着负梯度方向去减小函数值,以此达到我们的优化目标
2 完整的反向传播算法理论推导
一个简单的例子来说
以下是一个简单的网络,其中参数都已经随机初始化了。那么这个网络我们先走下前向传播过程



对应的代码实现为
#!/usr/bin/env python
#coding:utf-8
import numpy as np
def nonlin(x, deriv = False):
if(deriv == True):
return x * (1 - x)
return 1 / (1 + np.exp(-x))
X = np.array([[0.35], [0.9]])
y = np.array([[0.5]])
np.random.seed(1)
W0 = np.array([[0.1, 0.8], [0.4, 0.6]])
W1 = np.array([[0.3, 0.9]])
print 'original ', W0, '\n', W1
for j in xrange(100):
l0 = X
l1 = nonlin(np.dot(W0, l0))
l2 = nonlin(np.dot(W1, l1))
l2_error = y - l2
Error = 1 / 2.0 * (y-l2)**2
print 'Error:', Error
l2_delta = l2_error * nonlin(l2, deriv=True)
l1_error = l2_delta * W1 #back propagation
l1_delta = l1_error * nonlin(l1, deriv=True)
W1 += l2_delta * l1.T
W0 += l0.T.dot(l1_delta)
print W0, '\n', W1
代码这部分
l2_delta = l2_error * nonlin(l2, deriv=True)
l1_error = l2_delta * W1 #back propagation
l1_delta = l1_error * nonlin(l1, deriv=True)
这三行就完成了相邻两层的反向传播,所以很容易就得所有的反向传播了。
参考:
https://www.bilibili.com/video/BV1kE4119726?p=11
b站上同济子豪兄
https://www.bilibili.com/video/BV1bx411M7Zx
b站关于深度学习之神经网络的结构 3Blue1Brown出版的。
https://blog.csdn.net/hrkxhll/article/details/80395033
随机梯度下降法的原理,就是为什么需要那样更新权重?
https://blog.csdn.net/walilk/article/details/50978864
一篇更解释更好的为什么要那样更新权重的博客。
https://www.cnblogs.com/guoyaohua/p/8542554.html
深度学习的优化算法综述
介绍反向传播算法,虽然有部分错误,但是却让我明白了其中过程。
https://www.bilibili.com/video/av29071445/?p=1
B站的凸优化课程学习(中科大)
https://www.bilibili.com/video/BV1bx411M7Zx
3Blue1Brown上关于深度学习网络结构的设计解释
https://www.bilibili.com/video/BV1TE411s75B?from=search&seid=1562094829455358917
哔哔哩上关于机器学习优化器的解释
https://www.bilibili.com/video/BV1Bz411B7kR?from=search&seid=1562094829455358917
李宏毅的关于优化器的视频
9 CNN
1 CNN的出现原因?为什么有它?
基于一些观察:1 图像结构类型的数据的话,一些模式是小于整个图像的。2 同样的模式会出现图的很多地方 3 通道是不变的。

9.1 卷积网络
9.1 .1 一个例子
下图是一个32*32*3的三维图片,右边是一个三维卷积核。那么如何卷积成深度为1的特征图呢?

我们可以使用多个filter分别卷积,得到原三维数据的多个深度为1的特征图。比如下面就是

我们发现前面是32*32*5的,后面是28*28*1的。这个计算过程一定要搞清楚。在后面会讲,那么经过多次卷积,我们可以获得28*28*n的卷积层。(n>=1),那么计算过程是怎样的呢?
如下所示,左一为输入7*7*3,左2,3为fileter(3*3*3)。左4为计算结果(3*3*2)。

具体计算过程为每移动一个步长,就把两个三维数据进行计算,求和。加上偏置项得到右1的第一个元素。
9.1.2 权值共享
原始数据用同样的filter去扫这个图,filter里面的就是说权重。这个原始数据都是用同样的filter扫的。权值是共享的。
9.1.3 池化层
池化就是浓缩,选择某个区域的一个具有代表性的值表示这个区域。比如maxvalue或者mean。
9.1.4 标准卷积网络组成

9.1.6 应用
CNN所解决的问题:
1 图像需要处理的数据量太大,导致成本很高,效率很低
2 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高

https://www.bilibili.com/video/av28733156/?p=3 入门学习视频
9.1.6 思考
1 步长的选择?
2 偏置项? 是什么,干什么?如何做的?
3 fileter的初始值是固定的吗?感觉没变过? filter的数目控制呢?
4 每个fileter对原始数据会卷成一个比如28*28*1的数据。这个1一定是确定的?那可不可以卷成28*28*n的任意数据呢?为什么这么计算呢? 或者说,这样计算其实是在说明什么呢? 为什么可以提取出原数据特征?
5 卷积的次数有没有确定?
6 有权值共享,那就是说可以不权值共享或者部分权值共享咯? 针对不同区域,权值可以不共享?
7 为什么需要池化层?池化需要多少次?
8 激活函数的确定?
9 如何给卷积以形式化的定义呢?就是卷积的数学化表达式?
10 有很多种卷积方式的。

CNN的反向传播推导


对于第l层,误差对于该层每一个权值(组合为矩阵)的导数是该层的输入(等于上一层的输出)与该层的灵敏度(该层每个神经元的δ组合成一个向量的形式)的叉乘


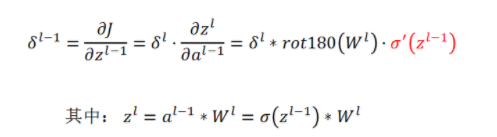
数学中的卷积和卷积神经网络中的卷积严格意义上是两种不同的运算
CNN的变体

1 回顾3blue视频那个手写数字识别的例子来说,其就是图像输入到神经网络中,没有卷积,卷积就是MLP的增强版,可以对结构化数据很好的处理。
2 所以最重要的就是池化到卷积、卷积到池化层的误差灵敏度如何传播过去。理解了反向传播,就可以逐层更新参数。
3
扩展资料:
1 两个高斯分布之和(卷积)理论推导
两个高斯分布之和绝不是对应坐标相加,卷积的物理意义不是两个概率密度相加,而是自变量相加后发生的概率。

参考:
Notes on Convolutional Neural Networks ,作者Jake Bourvie比较详细的介绍了CNN 的求导方法。
http://www.uml.org.cn/ai/201809102.asp?artid=21154
https://zhuanlan.zhihu.com/p/61898234
我是看这两个博客看懂的卷积网络的反向传播机制。
2020A Survey of the Recent Architectures of Deep Convolutional Neural Networks被220
CNN的综述
2017Feed Forward and Backward Run in Deep Convolution Neural Network被17
一个比较好的CNN正、反向传播的公式推导论文
10 RNN
10.1 展开计算图


1 上述只是一个简单的推导,但是还是有感悟。只需要写好前向传播的表达式,那么反向传播套路基本都一致的。
2
最简单的RNN及其变体。
LSTM(在memorty cell 部分有3个组成部件)



1 请分析为什么有时候RNN非常的不work。
截断梯度,可以解决的,用clipping,是工程式的。
这关于模型可解释性的内容了,你需要分析参数的变化才可以。
因为RNN反复使用W,所以学习率根本就不好调整。可以用LSTM稍微让其好些。它可以deal with gradiente vanishing(not gradient explode).
2 RNN对应的理论基础其实就是它根据模型的不同,状态转移公式和如何反向传播更新参数的公式推导。那CNN也要进行这一步的。
3
10.4 GRU只有两个输入
相对于LSTM,拿掉一个门。旧的不去,新的不来。
RNN的前向和反向传播更新公式
参考:
https://www.cnblogs.com/Finley/p/6845325.html
一个RNN的简单手写python实现。
https://www.bilibili.com/video/BV1JE411g7XF?p=21
李宏毅关于RNN的两集视频
https://zhuanlan.zhihu.com/p/28806793
就是这个帮助我推导了RNN的传播公式和其反向传播公式
https://manutdzou.github.io/2016/07/11/RNN-backpropagation.html
如果想要推导rnn可以看这篇公式它更为细节一点,上面那个当作理解吧。
https://www.jianshu.com/p/1dc21b622cf9
LSTM的基本公式及一些变体
https://zhuanlan.zhihu.com/p/83496936
LSTM的反向传播公式
第11章 实践方法论

11.1 性能度量
评估模型的好坏

混淆矩阵
11.2 参数调优

1 调参数不就是一个机器的工人吗。。。。。
2
参考:
https://www.bilibili.com/video/BV1kE4119726?p=14
同济子豪兄带我们学习深度学习
第 13 章 深度学习应用

第13章 线性因子模型

第14章 自编码器
主要就是考虑去噪和变分编码器。

14.1 概念
压缩: 有降维、去噪。


用于无监督的,编码器和解码器都是神经网络结构
举个例子:

在这里,编码器来编码,学到的维度。解码器负责解码出来。

代码例子: 针对minst的手写图片的例子来做的。

14.1 降噪自编码器
最简单的降噪自编码器如图
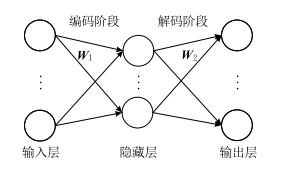
14.2 降噪自编码器
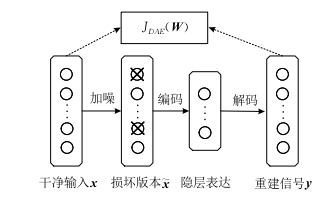
14.2.2 边缘降噪自编码器
给x加入噪声,变成x‘,再让编码器编码得到wx’,以x和wx‘和最小二乘法作为loss函数。
14.2.2.1 线性边缘降噪自编码器
1 不用任何优化算法,仅仅利用最小二乘法求导解析解就可以直接算出W。这种思想很好,利用loss函数为最小二乘法进而直接算出W。
下面两张图就是其中的推导,首先我们要知道最小二乘法的本质是什么。


2 疑问 ,
1 这里只有一个W,是不是意味着编码器只有一层?是的。领域适应性边缘降噪自编码器是由一些单层降噪自编码器组合而
2 而且是线性的,其实就不咋地,不知道能不能做成非线性的,深度学习就是强调非线性的特别强才做出来的。快的原因也是因为是线性的,而且求导可得w或者x这样的东西,所以求导式子非常漂亮。
3 x是怎么变成x’的,也就是如何加噪声的?
4
14.2.2.2 非线性边缘降噪自编码器
参考:
2019自编码神经网络理论及应用综被1
主体公式求导方法
关于矩阵求导的公式查询
https://blog.csdn.net/weiwei935707936/article/details/100798683
最小二乘法矩阵求导方式的解释。
2012Marginalized denoising autoencoders for domain adaptation被700
线性降噪编码器的原论文
2014Marginalized denoising auto-encoders for nonlinear representations被135
非线性降噪编码器的原论文
14.3 变分自编码器
理论基础:
1 先理解数值计算和采样计算
2 还要理解KL散度 https://www.jianshu.com/p/43318a3dc715
3 高斯噪声的加入。http://www.ruanyifeng.com/blog/2012/11/gaussian_blur.html
阮一峰,的高斯噪声的引入
4 高斯混合模型GMM https://zhuanlan.zhihu.com/p/30483076
知乎上的高斯混合模型解释
https://www.bilibili.com/video/BV13b411w7Xj?from=search&seid=9203391886051092194
白板推导的高斯混合模型介绍
LDA是什么?
5 KL散度
KL散度能够衡量两个分布之间的距离,用到了变分法。
KL散度
KL散度并不是度量两个分布的距离,其实不是的,因为没有对称性。KL衡量的更多是借助熵来表示原始分布和近似分布的的信息损失度。

高斯混合模型基础
1 高斯混合模型可以用除了极大似然估计的方法求参数吗?
2 高斯混合模型为什么用极大似然估计没有解析解呢?
3 高斯混合模型为什么就可以用EM算法来迭代得到近似解呢?

VAE相对于AE可以干什么
1 解码器部分应该是单独能够提取出来的,并且对于在规定维度下任意采样的一个编码,都应该能通过解码器产生一张清晰且真实的图片,因为得到了分布。 为什么现有模型AE不能单独提出解码器呢?
2 VAE的思路是从每一个样本经过encode中得到一个分布,让它靠齐标准正态分布,然后从这个标准正态分布中,随机采样,经过decode生成一个图片。其中得到的多个分布z,每个都是连续的,所以我们可以任意控制这些分布的参数来生成不一样的图片。
其思想图如图:
其中,每个z因变量都可以认为是构成这个图片的一个重要特征,而且这个特征是连续的。可以任意取值。以此得到不一样的图片。

详细图如下:

总结:就是本质还是自编码器那一套,但是其用两个神经网络对每个样本分别得到均值和方差(?)。然后每个样本都有对应正态分布,从每个正态分布采样出Z,这就完成编码器功能。
但是解码器就是从Z到X^.但如果就这样的话,X和X^就会训练之后等同了。正态分布的均值就是样本的值,方差都为0. 所以让所有正态分布往标准正态分布靠齐,就是在本来X和X^的loss函数中。
加入KL散度来度量这两个分布。
1 每个样本如何得到均值和方差?
2 让正态分布靠齐标准正态分布就能够让其有好的生成能力?如何解释?
这种思想很神奇,模型中间的有的部件的想让它,可以设计它的loss到总loss中去。
3 从正态分布中采样值得是?
这是模型的计算图:




1 这是VAE的设计图其中m是编码,c是m加上噪声之后的编码。后面接一个解码器。整体还是自编码器的设计模型。但是它为什么这样设计呢? VAE与AE最大的两点不同就是采样分布和loss函数。
2 理论基础高斯混合模型呢?就是说,任何一个数据的分布,都可以看作是若干高斯分布的叠加。但是需要极大似然法来求三种参数。
3 真实的步骤为:
1 我们希望求P(x),但是太难求了,我们转而求
其中
,
。我们构建解码器去求解P(x|z)的两个参数。
2 其中我们希望max(P(x)) ,
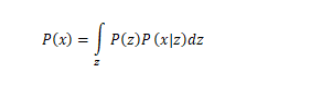

以上式子几乎可以很多都没做,单单就是加了一个q(z|x)而已。
根据上式子,我们发现只需要最大化
即可,那么这项可以写成
那么就变成求 第一项的最小,和第二项的最大,其实这两项就是loss函数的组成部分。而且我们构建的第二个神经网络叫做Encoder,它求解的结果是
,
可以代表任何分布。值得注意的是,这儿引入第二个神经网路Encoder的目的是,辅助第一个Decoder求解
,这也是整个VAE理论中最精妙的部分,下面我会详细地解释其中的奥妙。
这个第二项的表达式有点奇怪,我想细看下。有点像EM算法来做的,其实Eq(z|x)是后验分布,是解码器在先前设计的,为了求解解码器的公式中,而创建编码器。



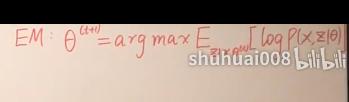
直觉: 我们本质是想要得到样本数据(训练集)


14.3.1 贝叶斯观点的VAE
先看蒙特卡洛的数学原理


数值计算和采样计算在样本量变大的时候,会越来越逼近。

李宏毅关于深度学习的变分器

1 VAE直接让我感受到了理论指导模型的典范,完全是理论的推导,来指导模型该如何设计的。
参考:
https://kexue.fm/archives/5253
苏简琳的博客,入门变分自编码器看这个
https://zhuanlan.zhihu.com/p/61611088
蒙塔卡罗的数学原理和其抽样次数N趋向无穷大的时候,其精确度推导
https://www.cnblogs.com/leoo2sk/archive/2009/05/29/1491526.html
蒙特卡洛的另一个博客
https://www.bilibili.com/video/av15889450/?p=33
李宏毅深度学习变分编码器视频
http://www.gwylab.com/note-vae.html
李宏毅变分编码器视频的解说博客
https://blog.csdn.net/weixin_40955254/article/details/81415834
CSDN上关于变分编码器的资料
https://www.cnblogs.com/weilonghu/p/12567793.html
讲的比较好的变分编码器
14.1 变分自动编码器(显示捕获数据分布)泛函的微分就是变分

得到每个隐变量的方差,每个采样都可以重构一张图片。


这个编码器就是捕获一些特征,每个隐变量都有自己的分布。贴近正态分布,而解码器,就是解码所有的特征,生成样本。变分的终极目的就是


GNN(隐式捕获数据分布)
参考:
https://www.bilibili.com/video/BV1kE4119726?p=17
同济子豪兄的参照
https://www.sohu.com/a/226209674_500659
苏剑林关于变分自编码器VAE的解释。
https://cloud.tencent.com/developer/article/1096650
一个网上的介绍
第15章 表示学习

好的表示可以让数据主要矛盾突出,也就是能够形式化好看(数学)等等。
特征工程VS表示学习
15.1 贪心权重逐层训练
每一层都是无监督。
15.2 迁移学习和领域自适应
用很少的数据量来泛化工程。



15.3 半监督因果关系

要求:
16 章 结构化概率模型
















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









