







1 罐子模型简介
1.1 基本模型
基本罐子模型中,罐子包含x个白色和y个黑色的球,它们混合在一起。从中中随机抽取一个球,观察其颜色;然后将其放回缸中(或不放回缸中),并重复选择过程。
在此模型中可以回答的可能问题是:
- 我可以从n次抽取中中推断出白色和黑色的所抽取到次数占n的比例吗?有多大比例?
- 知道x和y,抽取特定序列(例如,一个白色然后是一个黑色)的概率是多少?
- 如果我只观察n个球,我如何确定没有黑球?(第一个问题的变体)
1.2 不同问题的分布
- 二项式分布:罐子初始有两种颜色的球,放回抽取。在n次抽取中某种颜色被抽到的次数,它的分布列属于二项分布。其表达式如下(其直观含义就是n次抽取中有k次抽到某种球的概率)

- β-二项分布:如上所述,除了每次观察到一个球,都会向罐子中添加一个相同颜色的附加球。因此,罐子中的大理石总数增加了。参见Pólya缸模型。
- 超几何分布:罐子初始有两种颜色的球,每次提取后球不返回罐子。那么在n次抽取中抽取某种颜色球k次,它的分布是超几何分布。(它描述了从有限N个物件(其中包含M个指定种类的物件)中抽出n个物件,成功抽出该指定种类的物件的次数(不放回)。称为超几何分布,是因为其形式与“超几何函数”的级数展式的系数有关。)
- 多元超几何分布:如上所述,但球具有两种以上的颜色。
- 几何分布:在n次抽取中,抽取k次才第一次成功抽取某种颜色球的概率。直观就是在n次伯努利试验中,试验k次才得到第一次成功的机率。详细地说,是:前k-1次皆失败,第k次成功的概率。几何分布是帕斯卡分布当r=1时的特例。
- 负二项式分布:罐子初始只有两种颜色球,n次抽取中,到k次都没有抽取某种颜色球的概率。它表示,已知一个事件在伯努利试验中每次的出现概率是p,在一连串伯努利试验中,一件事件刚好在第r + k次试验出现第r次的概率。
- 统计物理学:能量和速度分布的推导。
- 该埃尔斯伯格悖论。
- Pólyaurn each:每次绘制特定颜色的球时,都会将其替换为另外一个相同颜色的球。
- 霍普瓮:波利亚瓮额外的球叫突变。绘制增幅器后,它会与其他全新颜色的球一起被替换。
- 占用问题:将k个球随机分配给n个骨灰盒后,占用骨灰盒的数量分布。
-
非中心超几何分布:指的是n次抽取不放回中,某种球被抽取的概率较大。有偏向性
2 波利亚罐子模型
2.1 模型简介
基本的Pólya罐子模型中,罐子包含x白色和y黑色的球;从中随机抽出一个球,观察其颜色;然后将其返回到骨灰盒中,并将相同颜色的另一个球添加到骨灰盒中,并重复选择过程。感兴趣的问题是抽取某种颜色球数量的演变以及抽取的球的颜色顺序。
2.2 不同问题的分布
- beta-binomial分布(贝塔二项式分布):初始罐中只有两种颜色球,比如在n次抽取中某种颜色球被抽取的次数概率分布列。是一个贝塔二项式分布列。因为每次抽取某种球的成功概率未知或者随机时,而是从β分布中随机得到。那么如果每次该种颜色球所占罐子球比例知道,那么就是普通二项式分布。不知道就认为该抽取次数随机变量符合贝塔分布,是一个随机变量。
而贝塔分布是指一组定义在(0,1) 区间的连续概率分布,由两个参数控制。也就是贝塔分布是作为一个概率的概率分布而来的。因此,对于一个我们不知道概率是什么,而又有一些合理的猜测时,beta分布能很好的作为一个表示概率的概率分布。
比如初始波利亚罐子中有3种颜色球,那么初始的贝塔分布参数为(a=1/3-2,b=3-1/3-2),所以可得a=1,b=2。但是我们只关心某一个颜色球被抽次数所占比例分布,a/(a+b)=1/3,自然也就可以和度为3的规则树的情况对应起来了,贝塔分布就是作为某次伯努利实验中某种颜色球所占比例。推广的看就是先验概率为1/3,根据每次抽的情况,来更新(a,b)。
那么贝塔分布其表达式长什么样子呢?
2.2.1 一个例子

在上图中,将最普通的二项分布的参数p作为一个贝塔分布的随机变量,那么用贝塔分布(a,B)去刻画这个p。
那么这个联合起来的分布就是上图所示,那么如果计算呢?其计算公式如下
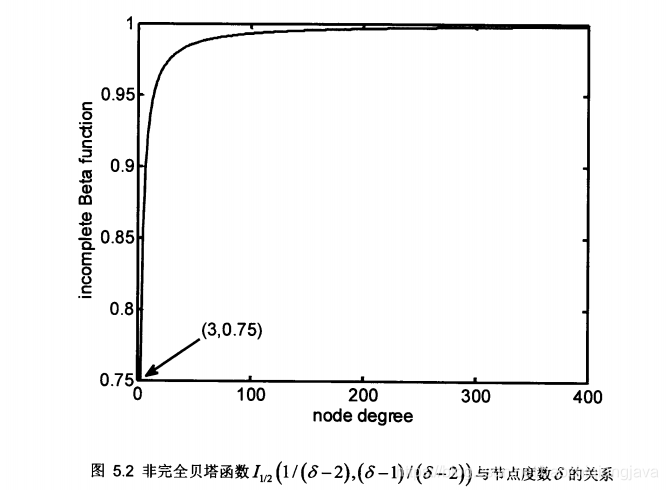
在董文祥的论文中,不完全的贝塔公式计算就是替换积分上限为1/2即可。

如果想要计算,只需要按照如上方法计算贝塔分布的概率值即可。
- Dirichlet多项式分布(也称为多元Pólya分布):初始罐子有多种颜色球,每种颜色的球数上的分布,在n次抽取中,某种颜色球所占比例收敛到狄利克雷分布。
Dirichlet分布是Beta分布的多元推广。Beta分布是二项式分布的共轭分布,Dirichlet分布是多项式分布的共轭分布。
参考:https://www.zhihu.com/question/26751755
- ting,β-二项分布和β分布:
- Dirichlet过程,中餐厅过程,Hoppe缸:
- 莫兰(Moran)模型:
3 我所关注的波利亚罐子模型部分


这里的向量X的联合分布,就是在q次抽取中,各种颜色球被抽取过得次数的联合分布。而当抽取次数趋于无穷时,每种颜色球被抽取次数占全部抽取次数的比例收敛到狄利克雷分布。还可以得到在n次抽取中某种颜色球抽取次数的边缘分布(等价于整个分支节点数目的边缘分布)。

那么只考虑n次抽取中一种球被抽取次数占比的分布的话,它收敛于贝塔分布。( Dirichlet分布是Beta分布的多元推广。Beta分布是二项式分布的共轭分布,Dirichlet分布是多项式分布的共轭分布。),我们仅仅对n次抽取中某个颜色球被抽取次数占比对应贝塔分布感兴趣。
思考:
别人需要某个理论的时候的流程是:研究某个问题,利用数学建模过程,发现在某些假设下等价于某个数学上已知模型,学习该数学模型,看与这个问题内在规律是否对应。可根据问题的研究的不同,对该数学模型做取舍。比如这里仅仅只对n次抽球中某个颜色球抽取次数占比感兴趣。那么问题如下
1 如何衡量谁的模型好或者不好?在指标上表现
2 考虑某一种方法,性能一般,但也可以数学建模,然后验证其性质?有发论文的价值吗?
3.1 波利亚罐子模型和SI模型传播的等价构造(重点)
而等价构造的过程,是锻炼我们寻找理论支持的能力。在这个等价构造的过程中,大牛也是通过阅读专业书籍《分支过程》,发现分支过程与SI模型(指数分布,参数为1的假设下)是可以等价构造的,进而使用,我现在能做的就是模仿,将该方向所有的基础书籍通过阅读论文的方式找齐,打基础。

将上述语句简单一点阐述就是:
规则树中SI模型参数为1的指数分布传播与波利亚罐子模型抽球过程等价构造。
1 罐子中:
- 初始化:初始有bi =1个颜色为ci的球,
- 抽取过程 :每次从罐子均匀抽取一个球后,将这个球和额外的
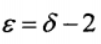 个相同颜色球放入罐子,
个相同颜色球放入罐子, - 终止:重复q=n-1次抽取过程,颜色为ci的球被抽取的次数用随机变量Xi表示。
2 规则树中:
- 初始化:初始源点s有有bi =1个颜色为ci的邻居节点为谣言边界。
- 感染过程 :每次从谣言边界中(罐子中球)均匀抽取一个点感染后,引入
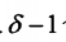 个节点加入到谣言边界(罐子中球)中。
个节点加入到谣言边界(罐子中球)中。 - 终止:重复q=n-1次感染过程,颜色为ci的分支树节点数目(以s为源,bi为根的子树节点数目)用随机变量Xi表示。
上述的谣言边界总结点数目就是当时罐子中所有节点的数目,所以就是罐子中每次抽取到的概率都是和规则树中一致的。
利用它就可以得到规则树中每个分支树的节点数目的联合分布
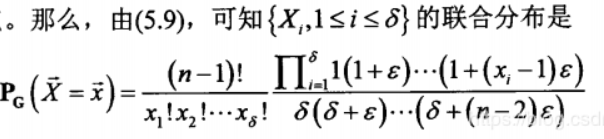

上述简单化一下,就是我们仅仅对规则树中某个分支节点数目所占总感染节点的比例边缘分布感兴趣,它符合参数为![]() 的贝塔分布。
的贝塔分布。
3.2 附录(个人研究笔记,可略看讨论)
3.2.1 分支占比分布的利用
上述我们对于分支占比分布已经有了了解,对我来说,我的目的是为了了解论文[1]做了什么工作,怎么做的。
利用上述分支占比分布,该论文[1]提出一种局部谣言中心概念,该局部谣言中心的定义表明其具有一个性质。谣言中心在某个树型传播网络最多有两个,对一个局部谣言中心性来说。其每个分支树所占比例都会小于等于n/2,n为总感染结点数目。
所以可得 
上述就是说这种局部谣言中心在规则树(SI模型指数分布传播参数为1)上的正确检测概率,利用占比分布的贝塔分布我们有

上述,利用分支占比分布直接得到对于度为2,度为3的规则树时候,局部谣言中心的正确检测概率与n的函数关系。
在这里为止,这篇论文将论文[2]的谣言中心一般化了,然后一般化之后,在有限域中得到其正确检测概率。整个的一个流程就是研究网络模型和传播过程,加上某些假设等价于波利亚罐子模型,对于问题提出一个算法找谣言中心点,发现其具有某种性质,这种性质又可以和波利亚罐子模型的占比分布联系一起。自然就可以得到这种算法的准确率了。
3.2.2 研究该正确率函数性质(数学分析)
那么很自然的,我们得到了一个关于度和感染总结点和正确检测概率的函数关系式,那么研究其函数的性质也是自然地,比如什么时候取极值或者收敛等等。论文[1]有

但是对于
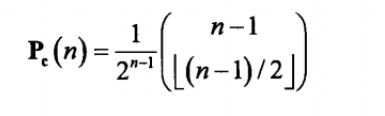
这种类型的函数,推导Pc(n)和自变量(度数和n)之间的变化关系不好推,因为它不符合正常的函数。我们可以使用递推式的方法,
3.2.3 渐进域正确检测概率
虽然之前都在说这个函数单调增,单调减,但是其收敛值我们不知道,我们可以研究下

上述,告诉我们当n趋于无穷大的时候,局部谣言中心所点源点的正确检测概率近似值为0.307。
这个地方他的表达式推导是可以考虑的,考虑beta公式,我们做定积分运算。
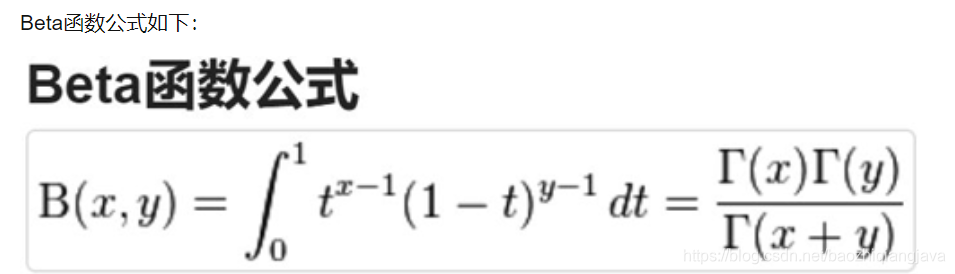
3.2.3 能更改的东西有
3.2.4 有先验知识的信息源检测
【1】论文作者在这里研究了有先验知识下的信息源检测,在标准理论下的不同情况中,可以套理论。

上述就是在说:
论文【1】第6章,会分析在已经有嫌疑节点的先验知识下,观察到某些被感染点情况。如何构造源估计从而使得检测概率最大化?这是一个MAP问题,作者通过构造问题形式化定义,利用波利亚关系模型等价构造。得到了三种情形下的局部谣言中心的正确检测概率的性能变化。
1 问题从新定义

2 正确概率分析
2.1 当嫌疑节点构成连通子图时


上述就是说:
在嫌疑节点构成连通子图情况下,我们有先验知识了,并且每个嫌疑节点为源点概率是平均的,那么所有的嫌疑节点先验乘以其条件概率,再统一求和就是正确检测概率。相当于对n个节点做了一个精简化。正确检测概率Pc(n)就为6.6式。
利用公式6.6,再结合只关注嫌疑节点,那么每个嫌疑节点的条件概率为

综合可得

这个过程就是说,现在有波利亚标准理论了,可不可以做一些情况下的直接套标准理论的分析呢?比如有先验情况的?
关注其检测性能

2.2两个嫌疑节点的情况
1 正确检测概率分析

上述的意思是说:
错误检测概率事件为以s*为源,距离为d的s2的子树数目满足6.42的式子,所以才定源错误,想要知道这种情况发生的可能性。
隐隐感觉这里用到了论文【3】中检测到感染第k个点为源的可能性。因为zh表示的是具有n个节点的Gn中以s*为源,以距离它d远的节点为根的子树Tn的节点数目。
隐隐感觉这里用到了论文【3】中检测到感染第k个点为源的可能性。似乎可以和论文[4]中样本路径关联在一起,比如你有一个算法,该算法找到一个点,是的该点任意一个分支长度小于等于该树中最长路径的1/2,那不就可以套了吗? 套马尔科夫级联。那么每个分支的长度不就是一条马尔科夫链吗?在度为2的时候的线形图中,这种算法找到点和局部谣言中心是等价的,所以检测概率相同,但是在度大于等于3的规则树中就不一定了,我们可以根据其分支数目确定其长度?分支在m到n区间内(这是有贝塔分布的),是这个长度,那么这种算法达到这种长度的话,其检测概率为多少呢?直觉上比谣言中心性高,因为其包含的事件更多一些。



上述在说:
定源错误,那么其实就是s2的RC>s*的RC,进而得到z1满足的关系式子。那为什么只考虑z1的分布呢?因为第度为2,所以只需要考虑边缘分布就可以了,参考5.12公式。
5 另一篇论文的改进方案
2020Root Estimation in Galton-Watson Trees
它直接用孩子分布D作为估计源点的一个参数,这样做的好处就是针对任何生成树,你的溯源算法都有准确率分析。但是缺点就是准确率不高,或者说可能还有别的溯源算法能够更高的准确率定位源点。
4 参考
【1】董文祥. 网络中信息传播:信息源选择与检测的若干关键问题研究[D]. 中国科学技术大学, 2014.
【2】2011Rumors in a Network Who's the Culprit
【3】 2011Finding Rumor Sources on Random Graphs
【4】 Zhu K, Ying L. Information source detection in the SIR model: a sample path based approach. IEEE/ACM Transactions on Networking, 2016, 24(1): 408-421.
【5】 2020Root Estimation in Galton-Watson Trees

















 3421
3421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









