







文章目录
CPU中常见并行技术
加法器:多个全加器/半加器并行执行
乘法器:多个加法器并行
流水线: 好几个指令并行执行
cache: 并行搜索/比较tag
virtual memory: virtual index与physical tag生成并行执行
并行计算的缘由
晶体管的尺寸变小,但阈值电压并没有跟随持续变小,这种情况下不能减电压,意味着频率越高,功耗越大,提频这条路堵死,因此方向转到多核。
1 提频是为了降压么?
并行计算的基础问题
并行计算的任务划分
1 那些代码串行执行,那些代码并行执行?
2 并行任务分配到那些资源上去执行?
3 有那些任务同步点?
并行计算的性能加速理论计算
- 加速的极限是多少?
假如一个任务由P(并行)和S(串行)组成
假如并行计算能力无限强,并行部分时间等于零。
加速后的时间等于S的时间。
即: P->0, S->S - Amdal’s law ?
同步
有那些需要同步的场景?
1 【先生产后消费】任务本身有先后顺序,比如生产者消费者模型中,先生产后消费,这个场景必须同步。
2 【生产/消费过程不可中断】两个消费者,消费同样的共享区域,由于read-modify-write的中断,有可能造成竞争的问题,这种场景需要同步。
- 同步的常用解决办法?
Lock的实现方法
- Lock的实现方法?
指令层面: atomic swap
总线层面:locked access, exclusive access
此外,compare and swap? test and set? 搞清楚这些事项? - Lock本身会不会出现竞争问题?
1 读写lock都是原子操作,将总线锁住? 以此来保证操作lock唯一性。
资源共享
cache coherency问题
snooping方法简述
- 当cache1(CPU1)修改了LineX,发现cache2(CPU2)想要读取LineX,怎么办?
1 将Linex写入DRAM
2 清楚LineX的dirty状态
3 通知cache2从DRAM中读取LineX的状态 - 当多个CPU同时更新一块值时? 怎么办?
理论上是加一把锁?但各个处理器程序的锁地址是否是同一块地址? 怎么 保证? 由编译器保证? 因为对程序员来说就是一个变量。
指令并行
指令并行与mem读写并行的区别
指令并行: register层面无数据依赖/资源依赖
mem并行: memory层面无数据依赖/资源依赖
指令并行时,并不考虑mem的依赖,这个是由后面环节考虑的。
怎么判断哪些指令可以并行?
register层面的数据依赖
register层面的资源依赖
从硬件资源角度,怎么安排可并行的指令执行?
1 有那些指令可以并行?
2 有那些资源可以使用? (ALU等)
ALU等硬件的资源
Implementating Synchronization
有哪些同步原语?(synchronization primitives)
- 互斥访问类
1 Locks
2 atomic primitives (e.g. atomic add)
3 Transactions - 事件通知类
1 Barriers
2 flags
【备注】
1 事件通知—【先生产后消费】任务本身有先后顺序,比如生产者消费者模型中,先生产后消费,这个场景必须同步。
2 互斥访问—【生产/消费过程不可中断】两个消费者,消费同样的共享区域,由于read-modify-write的中断,有可能造成竞争的问题,
同步事件
同步事件的三个阶段?
- Acquire method
如何申请? - waiting algorithm
blocking or non-blocking ? 阻塞 or 非阻塞? - release method
如何释放并通知其他候选人使用?
阻塞or非阻塞?
Implementating Locks
概述
lock在哪里实现?
- lock的本质是一个状态标志,这个标志可以是内存中的一个变量,是总线上的一个状态,或者cache的一个状态。
- lock标志必须被所有使用者看得到,其一定要处在汇聚点上
- lock本质是一个标志,所有使用者都必须遵守该标志的使用规则,才能正缺的实现锁功能
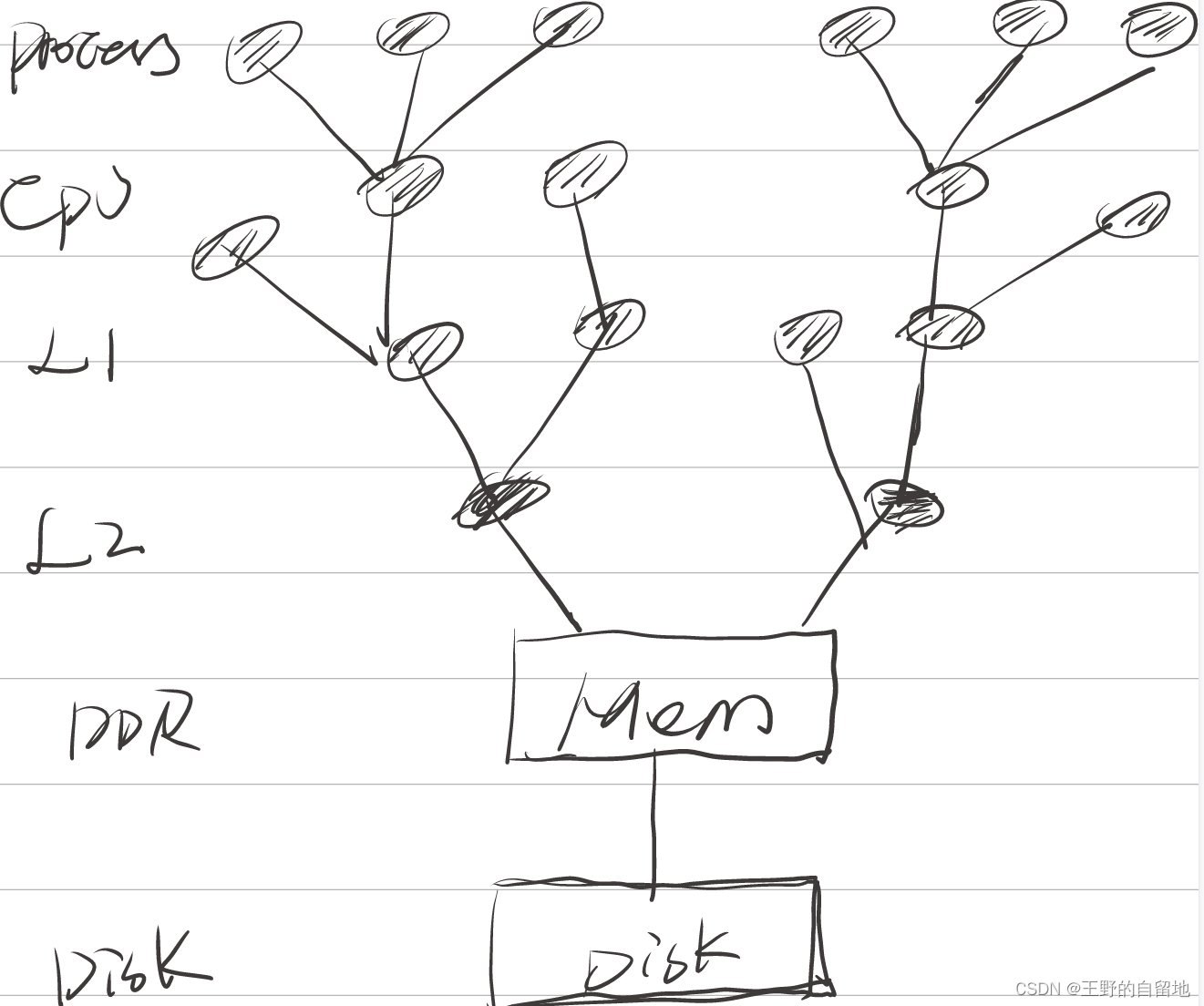
lock的本身操作怎么保证原子性?
lock机制,可以保证程序员的代码实现原子操作,但lock本身操作怎么保证原子性?
指令保证,如test-and-set, atomicSwap等等
层次化lock:
内存中数据的竞争,可以依靠内存的一个lock标志。
内存中lock标志的竞争,可以依靠原子指令(test_and_set,CAS)。
原子指令,可以依靠锁总线/指令外包给小包工头来实现。
lock实现的好不好?
不要多锁,锁多了,影响性能。比如,只需要锁一个内存变量,但锁了整个总线,就影响了别人的性能。
不要少锁,锁少了,影响功能。
指令层面
-
指令层面怎么能保证锁的原子性?
-
怎么保证在锁的时候不会被别人中断?
一种方法是,将该指令整体外包给小包公头(L1/L2/DDR),由小包工头实现拆分后任务的原子性和顺序性,但这对总线和小包工头提出了更高的要求,总线要具备传输这种特殊任务的能力,小包工头要具备这种任务拆解和执行能力。
另一种方法是,指令层面将该事件拆成子任务,并保证执行的原子性和顺序性。要保证原子性和顺序性,需要总线和cache的配合,如整个执行期间锁住总线/memory的数据,不要让别人操作等。
test-and-set
test-and-set 实现
下面是test-and-set的伪代码,该函数中的3条指令必须要一次执行完毕,不可中断。
硬件设计中,test-and-set指令可以外包给memory一侧,处理器和总线只看到test-and-set一条指令,在memory侧将该指令拆成3条子指令,memory测能保证这3条子指令顺序且原子执行,不被任何其他指令中断。
如果处理器将test_and_set指令拆成3条子指令,分发给总线和memory,且需要总线和memory保证其atomic和sequential特性,难度更大,需要锁总线/锁内存来支撑。
//注意 test-and-set是原语操作,3条指令必须一次执行完毕
//输入: *lock是该锁的内存地址
//输出:0:表示获取锁成功; 1: 表示获取锁失败
boolean test_and_set(*lock)
{
boolean old=*lock;
*lock=true;
return old;
}
test-and-set 使用
void Lock(int* lock) {
while (1) {
while (*lock != 0); // while another processor has the lock...
if (test_and_set(*lock) == 0) // when lock is released, try to acquire it
return;
}
}
void Unlock(volatile int* lock) {
*lock = 0;
}
test-and-set with backoff
test-and-set是原子的,当多个核同时执行test-and-set时,会碰到冲突,只有一个候选人能拿到锁,其他候选人不可能拿到锁。
没有拿到锁的候选人,如果钻牛角,持续不断执行test-and-set,会造成交通拥堵。解决这个问题的一个策略就是拿不到锁时,随机的延时一段时间,再尝试申请锁。
void Lock(volatile int* l) {
int amount = 1;
while (1) {
if (test_and_set(*l) == 0)
return;
delay(amount);
amount *= 2;
}
}
compare and exchange
// atomicCAS:
// atomic compare and swap performs this logic atomically
int atomicCAS(int* addr, int compare, int val) {
int old = *addr;
*addr = (old == compare) ? val : old;
return old;
}
同样,硬件设计中,CAS指令可以外包给memory一侧,处理器和总线只看到CAS一条指令,在memory侧将该指令拆成3条子指令,memory测能保证这3条子指令顺序且原子执行,不被任何其他指令中断。
如果处理器将CAS指令拆成3条子指令,分发给总线和memory,且需要总线和memory保证其atomic和sequential特性,难度更大,需要锁总线/锁内存来支撑。
Load-Link/Store-Conditional
lock前缀修饰的指令
Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令。
X86的lock前缀
如果memory数据在cache中,cache要持有数据直到操作完成。
如果数据不在cache,处理器要锁定总线,直到操作完成。
cache层面
lock与cache
lock访问对cacheline的基本要求
- lock访问对缓存/总线加锁,然后执行后面的指令,最后释放锁后会把高速缓存中的脏数据全部刷新回主内存。
- 在Lock锁住总线的时候,其他CPU的读写请求都会被阻塞,直到锁释放。Lock后的写操作会让其他CPU相关的cache line失效,从而从新从内存加载最新的数据。这个是通过缓存一致性协议做的。
【提问】
1 上述的脏数据全部刷会主内存,是指lock期间所生产的数据以及lock锁标志位本身,全部刷回内存么?
这里的lock标志应该是总线状态,没有内存的状态,不涉及将lock标志写入内存。
2 释放锁应该在flush完成之后才能释放么?
解锁前,必须将数据全部刷入内存中,理由是不同的进程,其ASID不一样,在cache中是无法复用的,该进程生产的数据,其他进程若要使用,必须先flush到内存中,其他进程才能使用。
锁定前,必须要保证cache拿到内存最新的数据,而且总线也被锁定了,保证其他进程无法拿到内存中的该数据。
锁定中,保证总线(内存中该地址)也被锁定了,其他进程无法拿到内存中的该数据。
利用MESI协议实现原子操作
我们依然假设只有2个CPU的系统。当CPU0试图执行原子递增操作时。a) CPU0发出"Read Invalidate"消息,其他CPU将原子变量所在的缓存无效,并从Cache返回数据。CPU0将Cache line置成Exclusive状态。然后将该cache line标记locked。b) 然后CPU0读取原子变量,修改,最后写入cache line。c) 将cache line置位unlocked。
在步骤a)和c)之间,如果其他CPU(例如CPU1)尝试执行一个原子递增操作,CPU1会发送一个"Read Invalidate"消息,CPU0收到消息后,检查对应的cache line的状态是locked,暂时不回复消息(CPU1会一直等待CPU0回复Invalidate Acknowledge消息)。直到cache line变成unlocked。这样就可以实现原子操作。我们称这种方式为锁cache line。这种实现方式必须要求操作的变量位于一个cache line。
总线层面
锁总线 — 乐观
AXI3的exclusive access
一个exclusive访问的基本过程如下:
1. 主机对slave的一个地址执行独占读操作。从机中的monitor会记录下该master的 ARID和 要访问的地址位置
2. 一段时间之后,主机对相同的地址执行独占写操作,从机同样要记录该操作的主机的 AWID 和 要访问的地址位置。
如果AWID == ARID 并且 该地址内容没有改变(没有被其他的master访问过),则独占写操作成功,同时slave会返回EXOKEY,否则slave会返回OKEY。
3. 主机独占写访问的结果表示为:
•如果自独占读访问到写访问以来没有其他主机写入该位置,则独占访问成功。在这种情况下,独占写更新内存地址。
•如果在独占读访问之后,有任何另外一个主机写入了该位置,则独占访问失败。
对于exclusive操作,总线不会被锁定,所以总线事实上允许其他master同时来请求总线。不过,当一个主机在执行独占访问时,其他master要同时通过总线访问其他的slave,该独占访问就失败了
————————————————
版权声明:本文为CSDN博主「restart0」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zmfmfking/article/details/120081488
独占访问限制:
•指定ID的独占写的burst size和burst length必须与前一个具有相同ID的独占读的burst size和burst length相同。
•独占访问的地址必须与事务中的总字节数(burst size * burst length)对齐。
•独占读和独占写的地址必须相同。
•独占访问中,独占读的ARID值必须与独占写AWID值匹配,即AWID==ARID
•独占访问中,独占读和独占写事务的控制信号必须相同。
•一个独占访问突发中,要被传输的字节数必须是2的幂,即1、2、4、8、16、32、64或128 bytes。
•一个独占访问突发中,可以传输的最大字节数是128。
•在AXI4中,独占访问的burst length不能超过16个transfers。
•AxCACHE信号的值必须保证监视独占访问的从机能看到事务。例如,一个独占访问不能具有表明该事务是可缓存的AxCACHE值。
————————————————
版权声明:本文为CSDN博主「restart0」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zmfmfking/article/details/120081488
锁总线 — 悲观
当CPU发出一个原子操作时,可以先锁住Bus(总线)。这样就可以防止其他CPU的内存操作。等原子操作结束,释放Bus。这样后续的内存操作就可以进行。这个方法可以实现原子操作,但是锁住Bus会导致后续无关内存操作都不能继续。实际上,我们只关心我们操作的地址数据。只要我们操作的地址锁住即可,而其他无关的地址数据访问依然可以继续。因此这种方法是一种悲观的锁总线策略。
AXI3的locked access
当一个主机使用AxLOCK信号表示一个事务是锁定事务时,互联(interconnect)必须确保只有该主机可以访问目标从机区域,直到同一个主机的一个非锁定传输的事务完成。互连中的仲裁程序用来执行该限制,并且必须强制执行此限制。
锁定访问要求在锁定序列进行时,互连(interconnect)阻止任何其他事务发生,即某个master 可以锁定总线来实现独占,只有当该master完成传输后才释放出bus,因此可能会对互连性能产生影响。相比之下,exclusive访问不需要将bus锁定给某个master。
AXI3的实现必须要支持锁定事务,而AXI4移除了对LOCK访问的支持,因为:
•大多数组件不需要锁定事务
•锁定事务的实现对互连(interconnect)的复杂性、保证QoS的能力有显著影响:
所以AXI4建议锁定访问仅用于支持legacy设备。
————————————————
版权声明:本文为CSDN博主「restart0」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zmfmfking/article/details/120081488
【提问】
1 如果一个访问锁总线失败,是直接返回求锁失败?还是让申请者等一等?
2
https://blog.csdn.net/zmfmfking/article/details/120081488
https://zhuanlan.zhihu.com/p/115355303
https://zhuanlan.zhihu.com/p/456233702
Implementating Barriers
Fine-grained synchronization & lock-free programming
以操作链表/树为例,如何理解以下几种情况
- 怎么理解粗粒度锁?
链表: per-link list一把锁,锁住整个链表
树: per-tree一把锁,锁住整个树 - 怎么理解细粒度锁?
链表: per-node一把锁,每次锁住一个node
树: per-node一把锁,锁住一个node - 怎么理解无锁?
CAS可以实现无锁,但可能出现ABA问题。















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









