







网易云音乐用户行为归因数据体系建设
导读:本次分享将介绍网易云音乐数仓归因体系建设所面临的问题和解决方案。
1.面临的问题

云音乐的数据接入包括 客户端日志、服务端日志、算法标签 以及 业务库 的数据。数仓核心资产的建设采用标准的 DIM-DWD-DWS 层次架构。首先对客户端日志、服务端日志进行整合,构建统一的公共流量模型和异常数据清洗机制,随后将流量数据细分为不同 流量场景 和 流量事件 的 DWD 层;基于算法标签构建 oneID、oneIP 等 新资产 的 DWD 层;基于业务库接入 业务事件 构成 DWD 层。然后按照用户、内容、创作者等等主题域划分形成 DWS 层,这里的数据类型包含 关系型 和 标签型 两大类。最后基于核心资产构建应用层,以服务云音乐的各个业务场景。用户行为归因 是数据基建的重要组成部分,而且归因数据贯穿于整个核心资产的建设以及数据应用过程中,是整个数据资产建设的核心。

图示为用户使用 APP 的一个操作链路。用户行为归因的核心目标在于解析用户在复杂 APP 操作链路中发生 转化 行为(如 播放、收藏、评论 和 下单)的原因,包括产品模块、关联资源、业务场景、分发策略等多个方面,以便优化产品功能、算法策略及运营策略,从而提升用户转化率、增强用户粘性和增加营收。
1.1 归因的业务背景

在云音乐特定的播放场景中,我们将 播放 视为一个特殊事件。在云音乐的 APP 页面下面有个播放器 mini 条,用户的歌单内容被批量加入或者替换到这个播放列表当中。在很多情况下,播放事件的触发或者执行,并不是由当前用户的一个直接操作来触发的,首先,播放列表中的内容可以连续播放,第二,当 APP 重启之后,播放列表的数据依然保持上一次退出的状态。此外,用户可以基于点击播放器进入播放页,进一步实现 收藏、评论、分享、购买 等其它行为。由于播放列表具有 连续性、可恢复并伴随状态,归因分析聚焦于 内容如何被添加至播放列表 而非具体用户页面跳转路径。为此,网易云音乐采用了 末次触点 归因策略,并不去定义用户从哪个页面打开的这个黑胶页,而是关注于内容是如何被分发的,也就是 如何被加入到播放列表的,即认定 待归因事件中最接近转化事件的因素 为决定性因素。
1.2 归因策略的选择

业界对于归因策略的方式不一,基本策略类型如上图所示。网易云音乐采用的策略是 末次触点归因 这一策略,即 待归因事件中最近发生的事件会被认为是导致这个转化事件的唯一因素。该策略因其全局一致性、逻辑直观且贴合实际业务场景而被采纳。在云音乐 APP 里面,页面跳转是非常复杂多样的,业务通常关注的重点在于直接入口引导的导流情况,以及整体的流量分布情况,因此我们最终的选择以末次触点归因作为一个基本策略。
1.3 上一阶段的实施方式和问题

常规归因的模式是通过时间序列排序做关联,其中主要包括四个方面,待归因的事件、目标事件、归因时间段 和 归因策略。基于这个常规的 ETL 模式,我们还做了三方面的额外处理:
- 第一个是核心的播放事件,我们会在埋点日志携带内容分发做直接归因(如来源于歌单);
- 当直接归因无法满足业务需求场景情况时(如继续追踪歌单的来源),我们会继续根据业务关心的目标事件做进一步的时间排序关联,做间接播放的间接归因;
- 第三层就是与播放相关的一些伴随状态事件的归因,如果播放的时候进一步进行了评论或分享,那么会将播放作为一个待归因事件,这些事件作为目标事件来继续基于时间序列的排序做关联。

上一个阶段的基本模式是围绕播放来触发,其问题也比较明显。
- 首先是 稳定性 方面,在每天几十亿条的日志中做排序和关联是非常耗时、耗资源的,因此实现成本非常高,在实时或者准实时场景基本是不可用的,所以实时或准实时都是粗放地根据日志做直接归因。
- 第二是 准确性 方面,归因结果含义不清晰(哪个产品模块、哪个关联资源,哪种业务场景,哪种分发策略),没有统一规范,并且受到归因时间段的限制,跨天无法完成归因,另外归因时间序列不一定能反映内容分发来源的真实情况。
- 第三是 扩展性 方面,大多数情况下无法支持更多的层级,另外因为产品功能不断迭代,无法去预知待归因事件类型,导致归因代码可能会需要频繁更新。
这三个方面的问题促使我们对整个归因体系进行了升级。
2.解决方案
2.1 上一阶段的实施方式和问题

要解决归因的稳定性、准确性、扩展性的核心问题,主要在于两个方面:
- 第一是归因过程要避免大量的数据排序关联;
- 第二是归因结果需要包含足够的信息支持业务的分析诉求。
最终我们是从 埋点体系升级、归因模型升级 和 埋点管理平台 三个方面联合去支持和达成整个归因体系建设的目标:
- 通过埋点体系的升级,标准化记录用户的行为链路,从而无需在 ETL 时做大量数据的关联和排序;
- 进行归因模型的升级,基于埋点的行为链路去产出业务角度的归因数据;
- 建设埋点管理平台,标准化埋点的管理流程,搭建埋点需求和埋点使用的一个桥梁,管控整个数据体系的建设。
2.2 举措一:埋点体系升级

埋点体系升级的前提是 数据仓库团队 与 大前端团队 联合发起了一个技术共建的项目,由大前端实现埋点框架的 SDK 实践,然后由数据仓库完成埋点内容的设计,实现了标准化的对象化管理,以便在 ETL 过程中无需大规模数据关联。
首先数仓团队按照位置和内容梳理出标准对象化管理的信息:
- 对象的 位置信息 包括 对象的 ID、对象的排序位置;
- 对象的 内容信息 包括 内容类型、内容 ID 以及 内容的分发策略,分发策略实际上可同时包含不同业务场景下的算法和运营策略。
页面中每个元素,包括页面本身,都会定义成不同对象,并通过层级关系去组装成为 SPM 和 SCM,分别对应的就是位置和内容的信息。
SPM(
Super Position Model,超级位置模型),是大数据中 Web 端和 APP 端采集用户在界面具体位置上的行为日志数据。同时,由 SCM(Super Content Model,超级内容模型)配合来获取位置中的内容,它们一起来完成用户行为细节的数据收集。SPM 和 SCM 范式最早由阿里巴巴提出并应用,现已成为大数据采集中数据埋点的重要规范。
基于标准化对象管理,我们标准化定义了归因参数。归因参数主要分三大要素,除了 SPM 和 SCM 外,还有 归因对象的类型标志,主要有 APP 启动、APP 页面元素的操作触点 和 外部唤起播放。我们将归因参数分为三大类型:
- 第一个是 PS refer,记录页面对象生成时的触点来源,通过 PS refer 的记录去屏蔽用户回退操作,避免链路过长;
- Multi refer 指的是页面往前的多级 PS refer 的组合,通过权衡需求场景和成本,保留了 5 级 refer 的信息;
- 最后 add refer 指的是对重点关注事件的归因对象。
有了这些基本的定义,最后按照 伴随态 和 非伴随态 两个状态去划分伴随态的归因。
- 伴随态里面,以播放事件为例,我们会持久化记录歌曲或者其他内容被单首或批量加入到播放器播放列表时的 add refer 和 Multi refer;对其他评论、分享等相关事件的归因信息,我们会将持久化的播放 refer 信息随着这些事件一起提交并记录。
- 对于非伴随态的归因,直接以触发这个事件时的 add refer 和 Multi refer 进行提交和记录,确保有效跟踪和过滤用户行为。
2.3 举措二:归因模型升级

归因模型升级需要完成的目标是重点解决埋点日志本身解决不了的问题。在归因链路上主要包括两类问题:
- 第一个是埋点本身技术实现与业务诉求不一致,APP 端开发组件可以实现复用,但是业务场景不一致,所以会出现 SPM 定义一致,但是业务含义不同的问题。
- 另一方面,末次触点不一定反映真实的业务诉求,在歌单详情页里面点歌曲或者点全部播放按钮都能触发播放,但是这两个触发播放的归因结果并不是业务想看到的,业务想要看到的是这个歌单最外层的分发场景。

有了埋点的链路数据,有效组织数据以支持多维归因分析的诉求是归因体系建设的另一个核心目标。业务上的多维分析场景主要有以下几个方面。
- 第一个是 来源的页面位置,记录符合业务诉求的一个末次触点,包括末次触点本身和该触点所归属的模块和页面。
- 第二个是 来源的媒介内容,歌曲可以在歌单、专辑、播单等场景中分发,相应这些归因数据会服务于歌单、专辑、播单主题域的建设。
- 第三个是 来源的业务场景,不同元素可能会归属于同一个业务场景,同一个业务场景在不同端或者不同版本上的 SPM 定义不一样,在业务归因场景需要解决位置和场景中间的信息差。
- 第四类是 来源的流量(分发策略)分类,可以按推荐类型、付费类型等来分类,以支持整体的流量分析和评估。

归因模型升级旨在弥补埋点数据与业务需求间的差距,通过定义媒介内容、确定有效触点以及业务唯一的 SPM 来解决特定场景下归因的精准度问题,并通过 UDF 解析归因字段生成适应多维分析的归因模型。
- 第一个是 定义媒介内容,也就是如何识别在待归因事件的触点对象中最近一个触点事件与目标事件关联的内容类型不同的内容。
- 第二个是 定义有效的末次触点,原始的末次触点并不一定能反映业务的诉求,需要根据实际的业务场景忽略业务认为无效的一些触点场景之后,再取得最后一次触点做有效的末次触点。
- 第三方面就是 定义业务唯一的 SPM,通常服务端去分发内容的时候,如果组件一致,取特殊的 SCM 标识组件,作为业务位置的唯一定义。

定义了归因的各个埋点标准之后,我们基于最底层事件的 DWD 层实现多维模型设计,来保证下游在所有使用场景中所有归因口径的一致性。
这里罗列了归因模型设计时的几个主要字段,包括常规业务字段、埋点日志中用于个性化的归因场景分析,以及数据查验的 addrefer 和 multirefer 字段、有效末次触点的 bizrefer 字段、描述来源媒介内容的字段,以及经过规则解析生成的有关业务场景和流量分类的字段,从而支持更深入的多维归因分析。
2.4 举措三:埋点管理平台

在整个模型设计或者是定义的过程中会涉及到很多配置信息,相关配置信息可以通过埋点管理平台来实现。埋点管理平台提供了包括需求管理、对象管理、事件管理等各种能力,辅助实现埋点登记、稽查索引的一体化。进一步我们可以通过这个埋点平台得到埋点信息的维度表,来支持下游所有跟埋点相关的,包括归因场景的一些数据的使用。
2.5 当前方案总结
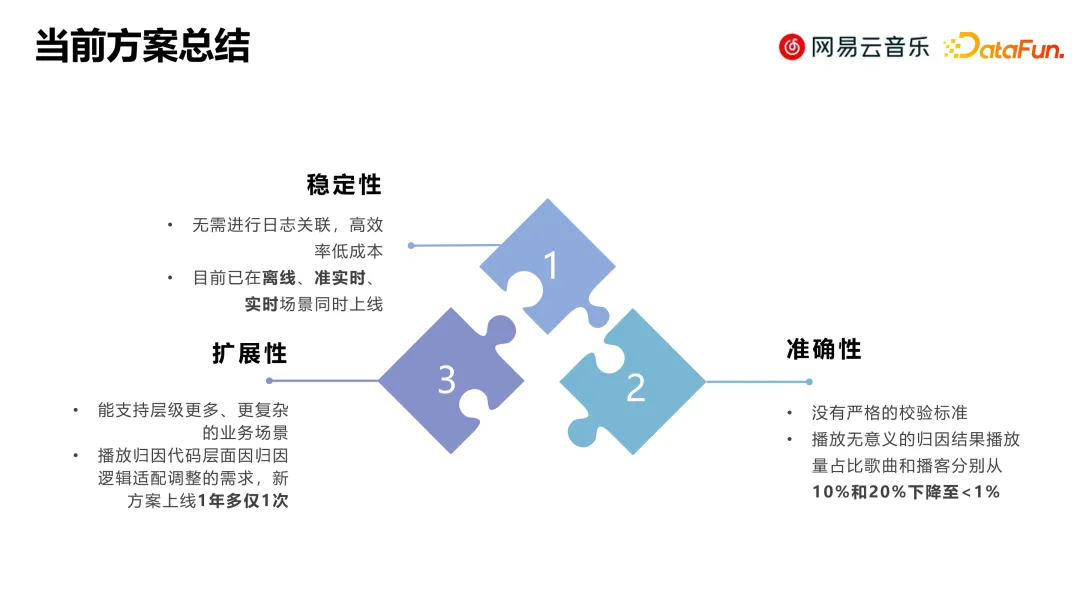
回顾之前提出的问题:
- 在稳定性方面,当前方案通过埋点去获取路径信息,无需做日志关联,效率高、成本低,且支持离线、准实时和实时场景。
- 在准确性方面,归因数据的覆盖和准确率都有了比较大的提升。
- 在扩展性方面,可以支持层级更多、更加复杂的业务场景,绝大部分需求都在埋点设计阶段和维表配置解决,无需去修改底层归因模型。
目前来看我们的整体方案对归因数据分析的准确性、扩展性、稳定性都有比较大的提升。
3.未来规划

最后分享一下对归因体系建设的规划。
- 首先是归因埋点。需要提高不同客户端类型的覆盖率,和归因场景的覆盖率,通过归因结果的监控识别归因异常,反推埋点层面进行修正。
- 第二方面就是归因模型,需要提高归因数据的覆盖率,比如目前也会有入口归因的分析需求,对应的可通过首次触点归因策略以类似的实现方式进行补充。此外,由于不同业务线的数据分支较多,在归因的实现上会有略微的差异,因此下一步目标是将整个归因体系的统一标准落地。
- 第三个方面是埋点管理平台,我们会通过埋点管理平台把归因 ETL 过程中使用到的所有配置信息进行统一化的管理,包括前文提到的业务唯一的 SPM 配置规则、有效末次触点的配置规则、业务场景归属的配置规则、流量分类归属的配置规则,最终实现整个归因数据生产和使用效率的大幅提升。
分享嘉宾|宋志毅 网易云音乐 资深数据开发工程师
编辑整理|程思琪
内容校对|李瑶
出品社区|DataFun



















 1594
1594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











