






1 目标检测
目标检测(Object Dectection)的任务是找出图像中所有感兴趣的目标(物体),确定他们的类别和位置,通俗的来说就是:识别图片中有哪些物体并且找到物体的存在位置。

而在实际操作中,我们主要的问题如下:
多任务:位置+类别
目标种类与数量繁多的问题
目标尺度不均的问题
遮挡、噪声等外部环境的干扰
2 目标检测常用的开源数据集
2.1 COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以场景理解为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止目标检测的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
图像示例:
2.2 PASCAL VOC数据集
PASCAL VOC是目标检测领域的经典数据集。PASCAL VOC包含约10,000张带有边界框的图片用于训练和验证。PASCAL VOC数据集是目标检测问题的一个基准数据集,很多模型都是在此数据集上得到的,常用的是VOC2007和VOC2012两个版本数据,共20个类别,分别是:
1.人: 人
2.动物: 鸟,猫,牛,狗,马,羊
3.交通工具: 飞机,自行车,船,公共汽车,汽车,摩托车,火车
4.室内: 瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
3 常用的评价指标
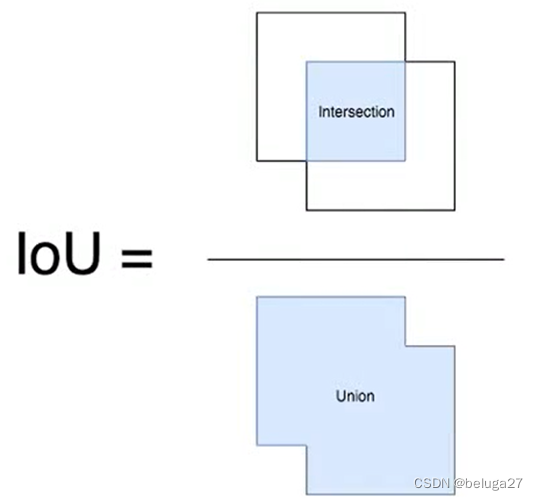
3.1 IOU
在目标检测算法中,IoU(intersection over union,交并比)是目标检测算法中用来评价2个矩形框之间相似度的指标:
IoU = 两个矩形框相交的面积 / 两个矩形框相并的面积
3.2 mAP(Mean Average Precision)
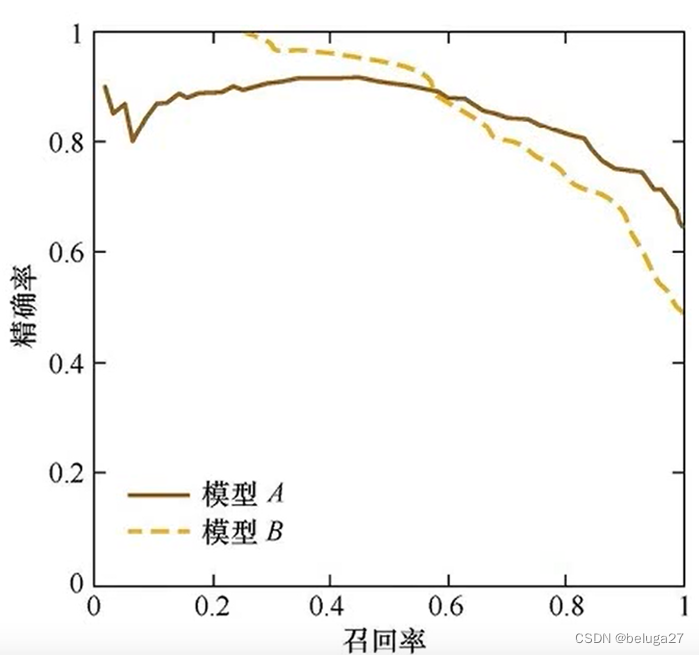
目标检测问题中的每个图片都可能包含一些不同类别的物体,需要评估模型的物体分类和定位性能。因此,用于图像分类问题的标准指标precision不能直接应用于此。 在目标检测中,mAP是主要的衡量指标。
mAP是多个分类任务的AP的平均值,而AP(average precision)是PR曲线下的面积,所以在介绍mAP之前我们要先得到PR曲线。
TP、FP、FN、TN
| 评价指标 | 解释 | Ground Truth | 预测结果 | 目标检测中的解释 |
| TP | 真的正样本 | 正样本 | 正样本 | IoU>阈值 |
| FP | 假的正样本 | 负样本 | 正样本 | IoU<阈值 |
| TN | 真的负样本 | 负样本 | 负样本 | |
| FN | 假的负样本 | 正样本 | 负样本 | 漏检目标 |
- True Positive (TP): IoU> ( 一般取 0.5 ) 的检测框数量(同一 Ground Truth 只计算一次)
- False Positive (FP): IoU<= 的检测框数量,或者是检测到同一个 GT 的多余检测框的数量
- False Negative (FN): 没有检测到的 GT 的数量
- True Negative (TN): 在 mAP 评价指标中不会使用到
查准率、查全率
- 查准率(Precision): TP/(TP + FP)
- 查全率(Recall): TP/(TP + FN)

3.3 准确率accuracy
表示所有预测结果中预测正确的结果占比。该指标适合数据均衡的情况下使用,在数据不均衡的情况下,该指标并不合适,此时应考虑精确率和召回率。
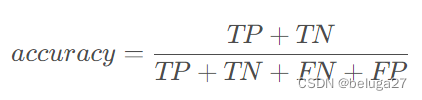
3.4 召回率recall
表示模型找到正例的能力,正样本被预测为正样本的数量 与 真实所有正样本的数量之比。

3.5 精确率precision
表示模型对于正例的判断能力,正样本被预测为正样本的数量 与 分类器认为是正样本的数量 之比。
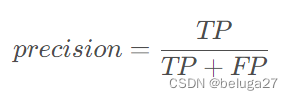
3.6 F值
F值综合了P和R,可用于综合评价分类结果的质量,当 α = 1 \alpha=1α=1时,被称为F1值。
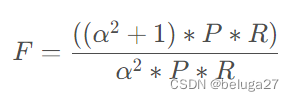
4 目标检测模型
目标检测分为两大系列——RCNN系列和YOLO系列,RCNN系列是基于区域检测的代表性算法,YOLO是基于区域提取的代表性算法,另外还有著名的SSD是基于前两个系列的改进。
4.1 RNN
R-CNN(全称Regions with CNN features) ,是R-CNN系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如R-CNN pipeline中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用selective search提取region proposals,使用SVM实现分类。
4.2 YOLO
YOLO(You Only Look Once )是继RCNN,fast-RCNN和faster-RCNN之后,Ross Girshick针对DL目标检测速度问题提出的另一种框架,其核心思想是生成RoI+目标检测两阶段(two-stage)算法用一套网络的一阶段(one-stage)算法替代,直接在输出层回归bounding box的位置和所属类别。
之前的物体检测方法首先需要产生大量可能包含待检测物体的先验框, 然后用分类器判断每个先验框对应的边界框里是否包含待检测物体,以及物体所属类别的概率或者置信度,同时需要后处理修正边界框,最后基于一些准则过滤掉置信度不高和重叠度较高的边界框,进而得到检测结果。这种基于先产生候选区再检测的方法虽然有相对较高的检测准确率,但运行速度较慢。
YOLO创造性的将物体检测任务直接当作回归问题(regression problem)来处理,将候选区和检测两个阶段合二为一。只需一眼就能知道每张图像中有哪些物体以及物体的位置。下图展示了各物体检测系统的流程图。

实际上,YOLO并没有真正去掉候选区,而是采用了预定义候选区的方法,也就是将图片划分为7*7个网格,每个网格允许预测出2个边框,总共49*2个bounding box,可以理解为98个候选区域,它们很粗略地覆盖了图片的整个区域。YOLO以降低mAP为代价,大幅提升了时间效率。
5 常用图像标注工具
5.1 LabelImg
1)LabelImg 是一款开源的图像标注工具,标签可用于分类和目标检测,它是用 Python 编写的,并使用Qt作为其图形界面,简单好用。注释以 PASCAL VOC 格式保存为 XML 文件,这是 ImageNet 使用的格式。 此外,它还支持 COCO 数据集格式。
2)安装方法:
前置条件:安装Python3以上版本,安装pyqt5
第一步:下载安装包
第二步:使用Pycharm打开项目,运行labelImg.py文件;或直接运行labelImg.py文件
3)常见错误处理:
① 报错:ModuleNotFoundError: No module named ‘libs.resources’
- 处理方式:
- 将python下scripts添加到环境变量path中
- 在labelImg目录下执行命令:pyrcc5 -o resources.py resources.qrc
- 将生成的resources.py拷贝到labelImg/libs/下
- 执行labelImg.py程序
5.2 Labelme
labelme 是一款开源的图像/视频标注工具,标签可用于目标检测、分割和分类。灵感是来自于 MIT 开源的一款标注工具 Labelme。Labelme具有的特点是:
- 支持图像的标注的组件有:矩形框,多边形,圆,线,点(rectangle, polygons, circle, lines, points)
- 支持视频标注
- GUI 自定义
- 支持导出 VOC 格式用于 semantic/instance segmentation
- 支出导出 COCO 格式用于 instance segmentation
5.3 Labelbox
Labelbox 是一家为机器学习应用程序创建、管理和维护数据集的服务提供商,其中包含一款部分免费的数据标签工具,包含图像分类和分割,文本,音频和视频注释的接口,其中图像视频标注具有的功能如下:
- 可用于标注的组件有:矩形框,多边形,线,点,画笔,超像素等(bounding box, polygons, lines, points,brush, subpixels)
- 标签可用于分类,分割,目标检测等
- 以 JSON / CSV / WKT / COCO / Pascal VOC 等格式导出数据
- 支持 Tiled Imagery (Maps)
- 支持视频标注 (快要更新)
5.4 RectLabel
RectLabel 是一款在线免费图像标注工具,标签可用于目标检测、分割和分类。具有的功能或特点:
- 可用的组件:矩形框,多边形,三次贝塞尔曲线,直线和点,画笔,超像素
- 可只标记整张图像而不绘制
- 可使用画笔和超像素
- 导出为YOLO,KITTI,COCO JSON和CSV格式
- 以PASCAL VOC XML格式读写
- 使用Core ML模型自动标记图像
- 将视频转换为图像帧
5.5 CVAT
CVAT 是一款开源的基于网络的交互式视频/图像标注工具,是对加州视频标注工具(Video Annotation Tool) 项目的重新设计和实现。OpenCV团队正在使用该工具来标注不同属性的数百万个对象,许多 UI 和 UX 的决策都基于专业数据标注团队的反馈。具有的功能
- 关键帧之间的边界框插值
- 自动标注(使用TensorFlow OD API 和 Intel OpenVINO IR格式的深度学习模型)
5.6 VIA
VGG Image Annotator(VIA)是一款简单独立的手动注释软件,适用于图像,音频和视频。 VIA 在 Web 浏览器中运行,不需要任何安装或设置。 页面可在大多数现代Web浏览器中作为离线应用程序运行。
- 支持标注的区域组件有:矩形,圆形,椭圆形,多边形,点和折线
















 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











