







此篇博客来自这篇论文One-Shot Neural Architecture Search Through A Posteriori Distribution Guided Sampling
一.介绍NAS
NAS全称是Neural Architecture Search, 就是神经网络架构搜索。这一思想主要是从迁移学习的方向引伸出来。我主要介绍它的优化问题,在NAS中,解决就是两个问题,一个是权重优化,一个是网络结构的优化。
最原始的NAS优化问题如下
w a ∗ = a r g m i n w a L t ( M ( a , w a ) ) w_a^{*} = argmin_{w_a}L_t(M(a, w_a)) wa∗=argminwaLt(M(a,wa))
a ∗ = a r g m i n a ∈ G L v ( M ( a , w a ∗ ) ) a^* = argmin_{a\in G}L_v(M(a, w_a^{*})) a∗=argmina∈GLv(M(a,wa∗))
其中G代表的是一些网络预先定义网络结构,比如3x3卷积核等,t代表训练集,v代表验证集, M ( a , w a ) M(a,w_a) M(a,wa)代表网络结构和权重的网络。
结构如下:(图片居中不了抱歉)
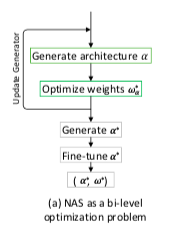
由于这种结构优化起来很慢,计算复杂度高,因而有了很多改进,近几年就出现one-shot model 可以有效提高优化速度,但存在权重和网络结构的无匹配问题。现在讲讲关于基于后验分布的one-shot model可以有效提高效率并且不需要Fine-tune,利用权重共享就能达到较高性能和准确率,由于以往的NAS很少能适应大型数据集,而这种方法能较好适应。
二. 关于基于后验分布的NAS的思想
NAS的问题是如何从训练集中得到网络并且具有泛化性能,泛化性能我们是通过验证集来进行做的。基于后验分布的NAS思想就是这样,我们就是要从一个训练集中去得到网络结构和权重参数,那我们可以用贝叶斯的方法求解。
p ( φ ∣ X , Y ) = p ( Y ∣ X , φ ) p ( φ ) ∫ φ p ( Y ∣ X , φ ) p(\varphi|X, Y) = \frac{p(Y|X, \varphi)p(\varphi)}{\int_{\varphi}p(Y|X, \varphi)} p(φ∣X,Y)=∫φp(Y∣X,φ)p(Y∣X,φ)p(φ)
这里的 φ = { φ l , k s } ( \varphi=\{\varphi_{l,k}^s\}( φ={
φl,ks}(这里的 s s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









