







Motion Aware Double Attention Network for Dynamic Scene Deblurring
前言:CVPR workshop2022基于事件单帧运动去糊的方法,设计了两个阶段的attention
论文:【here】
补充材料:【here】
引言
通常图片的运动模糊来自:物体运动、相机抖动,图像中物体的深度
图像的模糊程度,称作模糊水平, blurring level,是局部变化的,比如,哪怕相机只是抖动而物体不动,离得近的物体模糊程度也更大
用同一退化模型作用于全局容易造成伪影,因此我们考虑用一个attention衡量模糊程度,更好的区分不同模糊程度的去糊模型
仅使用普通相机的局限性在于:曝光时间也决定着图像的模糊程度,通常曝光时长越长,图像越容易糊,但是颜色信息都保存得比较好;而曝光时间短,图像不易模糊,但容易出现噪点
事件相机的成像机制能很好的克服这一缺点,因此采用事件相机辅助进行图像运动去糊
方法
pipeline
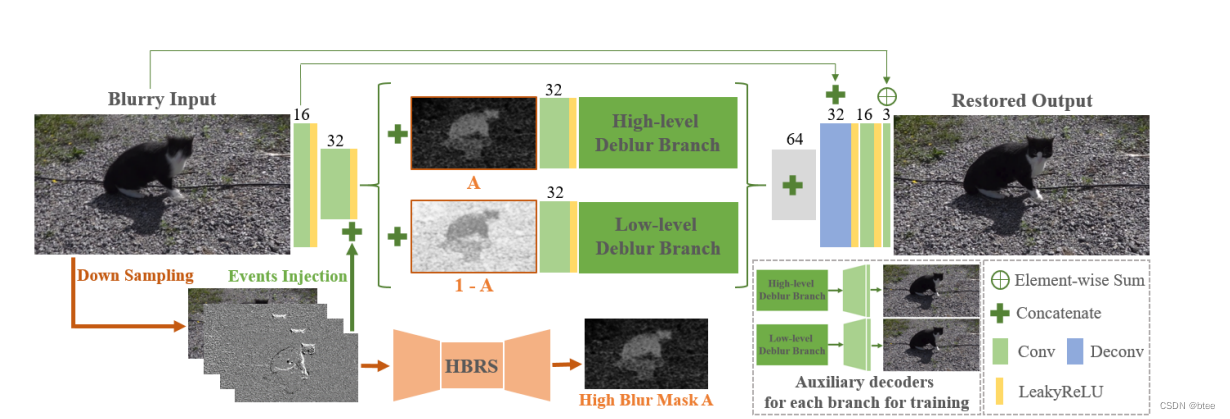
事件帧的堆叠
其中,一段时间内的事件被分成6个chunks,这个chunk内事件帧的堆叠方法为: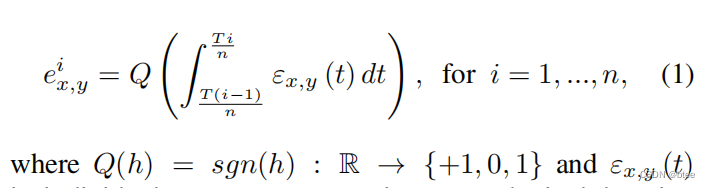
(这里的堆叠方式与其他方法不同,最后得到的帧只保留了符号,丢弃了这段时间内事件个数信息)
HBRS模块的设计(High Blur Region Segmentation (HBRS) sub-network)
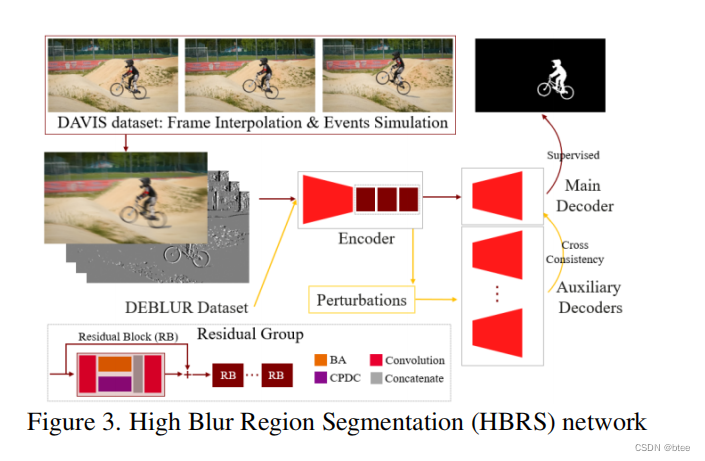
HBRS模块的输入:下采样后的模糊帧和堆叠的事件帧、
HBRS模块的输出:图像模糊的mask权重
这里的attention的BA模块设计来自另一篇论文,作者没有对此进行详细介绍,因此这里就跳过了
网络的设计:普通的encoder decoder设计
这里值得注意的是,这里的训练作者采用的是半监督学习训练方式,即 Cross-Consistency Training,大致思想是,对于无标签的数据,通过增加不同扰动,使结果尽量保持一致
因此得到的模糊水平Mask被加入了原模糊图像的特征图中,如下
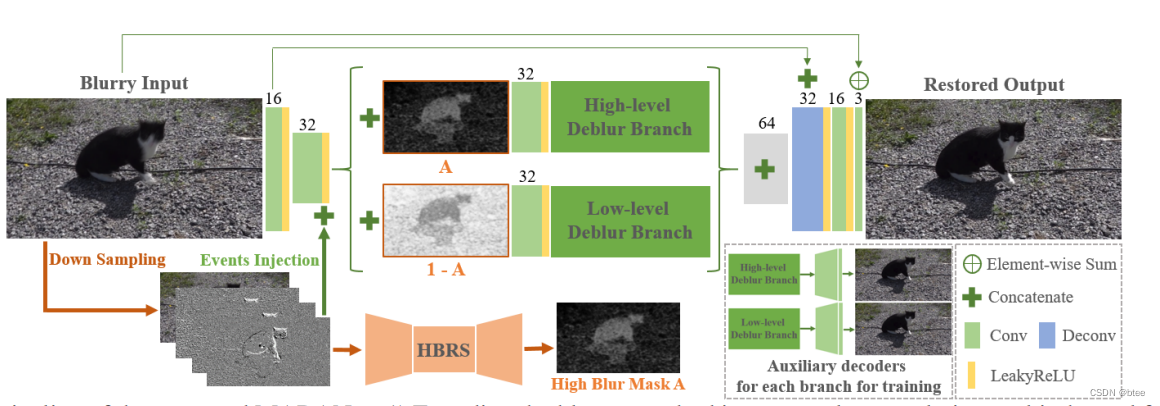
通过concat高模糊图,进行高模糊部分的去糊branch设计
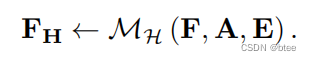
和低模糊图的去糊branch设计
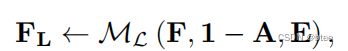
最后将两部分结果融合,得到最终结果
实验
对比实验
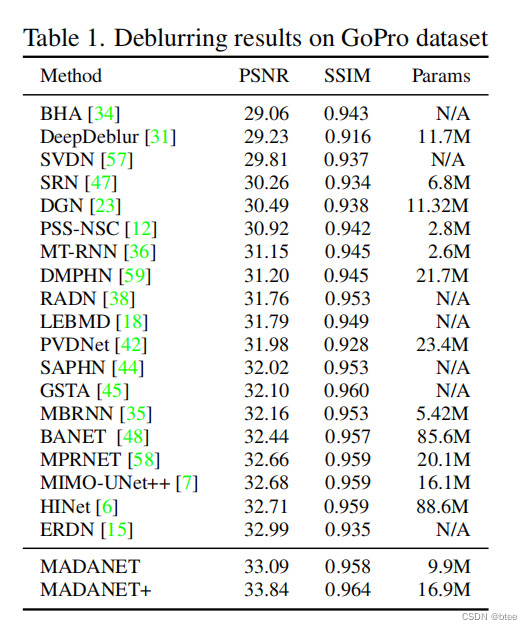
可以看到超过了当前基于事件和纯图像去糊方法
其中消融实验也很有趣
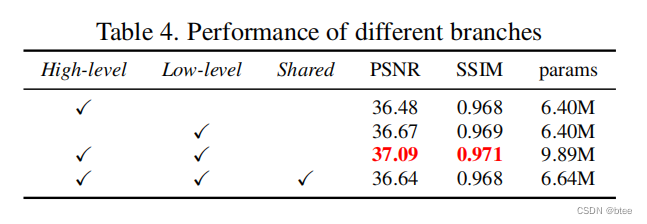
更关注不模糊的区域,效果居然比shared模型会更好。想不明白,作者也没有给出解释
总结
基于attention将模糊区域和非模糊区域分开,是个可以借鉴的想法,消融实验也证明效果不错














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









