







官网: https://docs.dgl.ai/tutorials/blitz/1_introduction.html#sphx-glr-tutorials-blitz-1-introduction-py
论文地址
点击跳转
参考文章:https://aistudio.baidu.com/projectdetail/2246479?shared=1
Cora 数据集介绍
Cora数据集包含2708篇科学出版物, 5429条边,总共7种类别。数据集中的每个出版物都由一个 0/1 值的词向量描述,表示字典中相应词的缺失/存在。 该词典由 1433 个独特的词组成。意思就是说每一个出版物都由1433个特征构成,每个特征仅由0/1表示。
- NumNodes: 2708。表示图中有2708个节点
- NumEdges: 10556。图中有10556条边。看其他说有5429条边但是dgl官网这个例子上显示10556。
- NumFeats: 1433。每个节点具有1433个特征。
- NumClasses: 7。数据集中的目标分类数为7。
- NumTrainingSamples: 140。训练样本数量为140。
- NumValidationSamples: 500。验证样本数量为500。
- NumTestSamples: 1000。测试样本数量为1000。
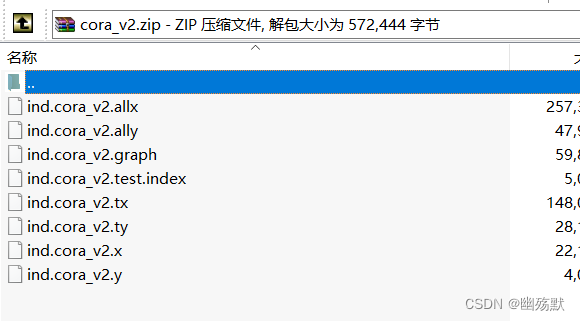
- ind.cora.x : 训练集节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为: (140, 1433)
- ind.cora.tx : 测试集节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为: (1000, 1433)
- ind.cora.allx : 包含有标签和无标签的训练节点特征向量,保存对象为:scipy.sparse.csr.csr_matrix,实际展开后大小为:(1708, 1433),可以理解为除测试集以外的其他节点特征集合,训练集是它的子集
- ind.cora.y : one-hot表示的训练节点的标签,保存对象为:numpy.ndarray
- ind.cora.ty : one-hot表示的测试节点的标签,保存对象为:numpy.ndarray
- ind.cora.ally : one-hot表示的ind.cora.allx对应的标签,保存对象为:numpy.ndarray
- ind.cora.graph : 保存节点之间边的信息,保存格式为:{ index : [ index_of_neighbor_nodes ] }
- ind.cora.test.index : 保存测试集节点的索引,保存对象为:List,用于后面的归纳学习设置。
一些细节解释
import os
os.environ["DGLBACKEND"] = "pytorch"#设置环境变量以选择后端框架为PyTorch的方式
import dgl
import dgl.data
import torch
import torch.nn as nn
import torch.nn.functional as F
dataset = dgl.data.CoraGraphDataset()
#用于加载Cora数据集。CoraGraphDataset函数会自动下载并处理Cora数据集,使其转换成适合图神经网络处理的格式。
#这个还会自动的输出关于该数据库的描述例如:点的数量,边的数量等等
print(f"Number of categories: {dataset.num_classes}")#输出Cora数据集中类别的总数。
g = dataset[0]
#一个DGL数据集对象可能包含一个或多个图表。本教程中使用的Cora数据集仅包含一个图表。
print("Node features")
print(g.ndata)
print(len(g.ndata))
for i in g.ndata.keys():
print(i)
for i in g.ndata.values():
print(i,len(i))
输出结果:
NumNodes: 2708
NumEdges: 10556
NumFeats: 1433
NumClasses: 7
NumTrainingSamples: 140
NumValidationSamples: 500
NumTestSamples: 1000
Done loading data from cached files.
Number of categories: 7
Node features
{'train_mask': tensor([ True, True, True, ..., False, False, False]), 'label': tensor([3, 4, 4, ..., 3, 3, 3]), 'val_mask': tensor([False, False, False, ..., False, False, False]), 'test_mask': tensor([False, False, False, ..., True, True, True]), 'feat': tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])}
5
train_mask
label
val_mask
test_mask
feat
tensor([ True, True, True, ..., False, False, False]) 2708
tensor([3, 4, 4, ..., 3, 3, 3]) 2708
tensor([False, False, False, ..., False, False, False]) 2708
tensor([False, False, False, ..., True, True, True]) 2708
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]) 2708
进程已结束,退出代码为 0
从上面可以看到该数据集的点的特征名称有5个。
需要注意的是,当运行数据集加载代码的时候会自动生成两个文件。
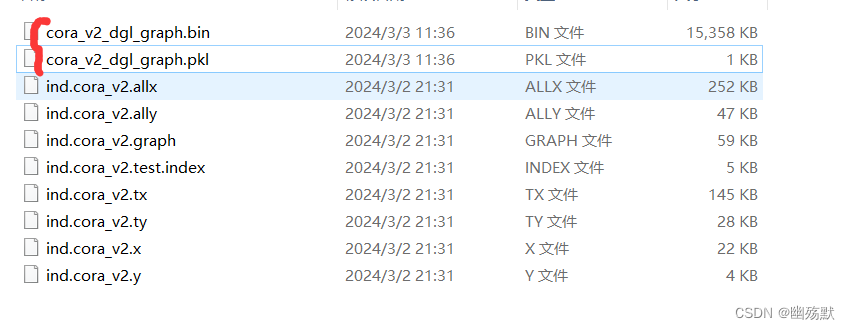
当您运行上述代码,加载Cora数据集时,DGL会自动下载原始数据文件,并在本地处理这些数据以构建图结构。处理完成后,为了提高未来加载数据的效率,DGL会将处理后的图数据保存到本地文件系统中。这就是cora_v2_dgl_graph.bin和cora_v2_dgl_graph.pkl文件的作用。
- cora_v2_dgl_graph.bin: 这个文件包含了处理后的Cora图数据的二进制表示。具体来说,它保存了图的结构(节点和边的信息)以及节点和边的特征数据。使用二进制格式可以有效地压缩数据大小,并加快数据的加载速度。
- cora_v2_dgl_graph.pkl: 这个文件是一个Pickle格式的文件,通常用于保存Python对象。在这个上下文中,它可能被用来存储与图相关的额外信息,例如数据集的元数据(如类别标签的映射)。然而,具体存储哪些信息可能取决于DGL的版本和数据集的实现细节。
这两个文件使得在您下次需要加载Cora数据集时,DGL可以直接从这些本地文件中读取处理好的图数据,而无需重新执行下载和处理的步骤。这大大减少了数据准备的时间,特别是在进行多次实验或模型训练时。
import os
os.environ["DGLBACKEND"] = "pytorch"#设置环境变量以选择后端框架为PyTorch的方式
import dgl
import dgl.data
import torch
import torch.nn as nn
import torch.nn.functional as F
dataset = dgl.data.CoraGraphDataset()
#用于加载Cora数据集。CoraGraphDataset函数会自动下载并处理Cora数据集,使其转换成适合图神经网络处理的格式。
#这个还会自动的输出关于该数据库的描述例如:点的数量,边的数量等等
print(f"Number of categories: {dataset.num_classes}")#输出Cora数据集中类别的总数。
g = dataset[0]
#一个DGL数据集对象可能包含一个或多个图表。本教程中使用的Cora数据集仅包含一个图表。
print("Edge features")
print(g.edata)

上图说明了边没有特征。
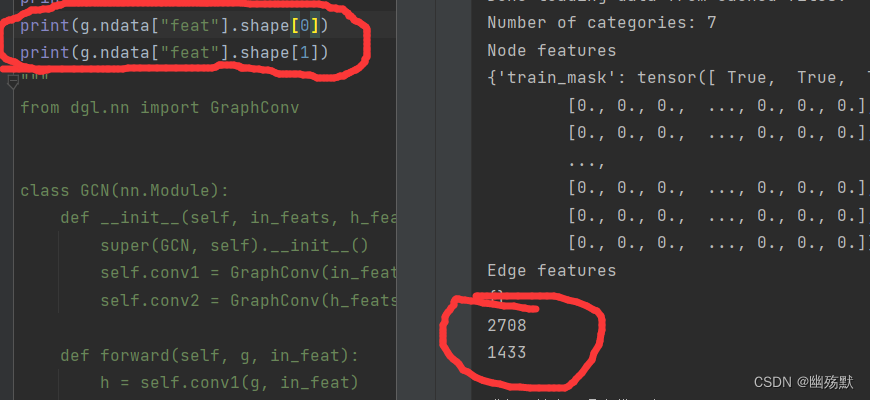
可以看到一共2708个点每一个点的特征维度是1433。
总代码
import os
os.environ["DGLBACKEND"] = "pytorch"#设置环境变量以选择后端框架为PyTorch的方式
import dgl
import dgl.data
import torch
import torch.nn as nn
import torch.nn.functional as F
dataset = dgl.data.CoraGraphDataset()
#用于加载Cora数据集。CoraGraphDataset函数会自动下载并处理Cora数据集,使其转换成适合图神经网络处理的格式。
#这个还会自动的输出关于该数据库的描述例如:点的数量,边的数量等等
print(f"Number of categories: {dataset.num_classes}")#输出Cora数据集中类别的总数。
g = dataset[0]
#一个DGL数据集对象可能包含一个或多个图表。本教程中使用的Cora数据集仅包含一个图表。
print("Node features")
print(g.ndata)
print("Edge features")
print(g.edata)
from dgl.nn import GraphConv
class GCN(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(GCN, self).__init__()
self.conv1 = GraphConv(in_feats, h_feats)
self.conv2 = GraphConv(h_feats, num_classes)
def forward(self, g, in_feat):#刚开始的in_feat是(2708,1433)
h = self.conv1(g, in_feat)#(2708,16)
h = F.relu(h)
h = self.conv2(g, h)#(2708,7)
return h
model = GCN(g.ndata["feat"].shape[1], 16, dataset.num_classes)#1433,16,7
def train(g, model):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_val_acc = 0
best_test_acc = 0
features = g.ndata["feat"]#(2708,1433)
labels = g.ndata["label"]#(2708),其中labels的每一个值在[0-6]之间代表其所属的类
train_mask = g.ndata["train_mask"]#(2708)
val_mask = g.ndata["val_mask"]#(2708)
test_mask = g.ndata["test_mask"]#(2708)
for e in range(100):
# Forward
logits = model(g, features)#logits的维度(2708,7)
# Compute prediction
pred = logits.argmax(1)#每一行找到最大值的索引.(2708)
# Compute loss
# Note that you should only compute the losses of the nodes in the training set.
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
#根据train_mask和train_mask取出训练好的预测标签和其真正对应的标签计算交叉熵损失
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
#将预测标签和真的标签对比一样就是True,否则就是False,将其转换成浮点数,计算均值其实就是其准确率
#需要注意的是这里训练是所有的点都进入网络,但是只有训练集才更新其参数
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print(
f"In epoch {e}, loss: {loss:.3f}, val acc: {val_acc:.3f} (best {best_val_acc:.3f}), test acc: {test_acc:.3f} (best {best_test_acc:.3f})"
)
model = GCN(g.ndata["feat"].shape[1], 16, dataset.num_classes)
train(g, model)
print(dgl.backend.backend_name) # 应该输出 'pytorch'
######################################################################
# Training on GPU
# ---------------
#
# Training on GPU requires to put both the model and the graph onto GPU
# with the ``to`` method, similar to what you will do in PyTorch.
#
# .. code:: python
#
# g = g.to('cuda')
# model = GCN(g.ndata['feat'].shape[1], 16, dataset.num_classes).to('cuda')
# train(g, model)
#
需要注意的一个点:
在图神经网络(GNN)中,确保只有训练集参与反向传播的关键在于损失函数的计算。具体来说,虽然整个图的所有节点都参与前向传播过程,以便节点可以接收来自其邻居的信息,但在计算损失和进行反向传播时,只考虑训练集中的节点。这是通过使用所谓的“掩码”(mask)操作来实现的。
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
这里只是用训练集来计算损失,计算得到的损失仅基于训练集,反向传播过程(loss.backward())也因此只会更新这部分数据对应的模型参数梯度。
可以打印参数看一下
















 6630
6630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









