







继上次做的简易的神经网络后,我们使用全连接层进行新的网络的构建(用于学会如何使用全连接层)
写在前面:本篇文章所使用的数据集是作者自己构造的一个数据集,所以训练的效果比较好,在现实具体的例子中可能会存在垃圾数据,所以本篇模型仅做参考
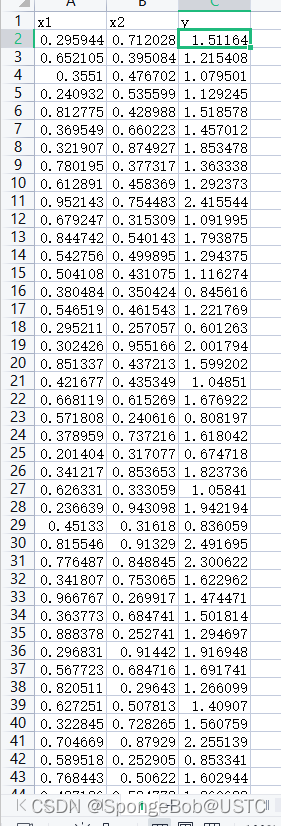
1.构造我们的数据集(CSV)
首先我们使用excel随机的生成x1,x2(我们生成了380条数据),然后我们套用公式计算出正确的y的结果,本篇文章我们的y=pow(x1,2)+2*x2[x1的平方加上两倍的x2]。此excel中的数据皆为标准答案,使用txt进行训练数据的构造也是可以的,只要能把数据读入到内存中来,就可以进行网络的训练。注意:尽量将x1,x2的数据弄小一点,如果数据取得比较大或者跨度比较大的话,可能会导致模型不回归,即出现loss函数不下降的情况,损失函数保持在一个非常高的位置。学习率设置的过小,数据不下降,学习率过大,数据下降过头,远离最优解,约等于不下降。
2.构造我们的模型
2.1进行数据的读取
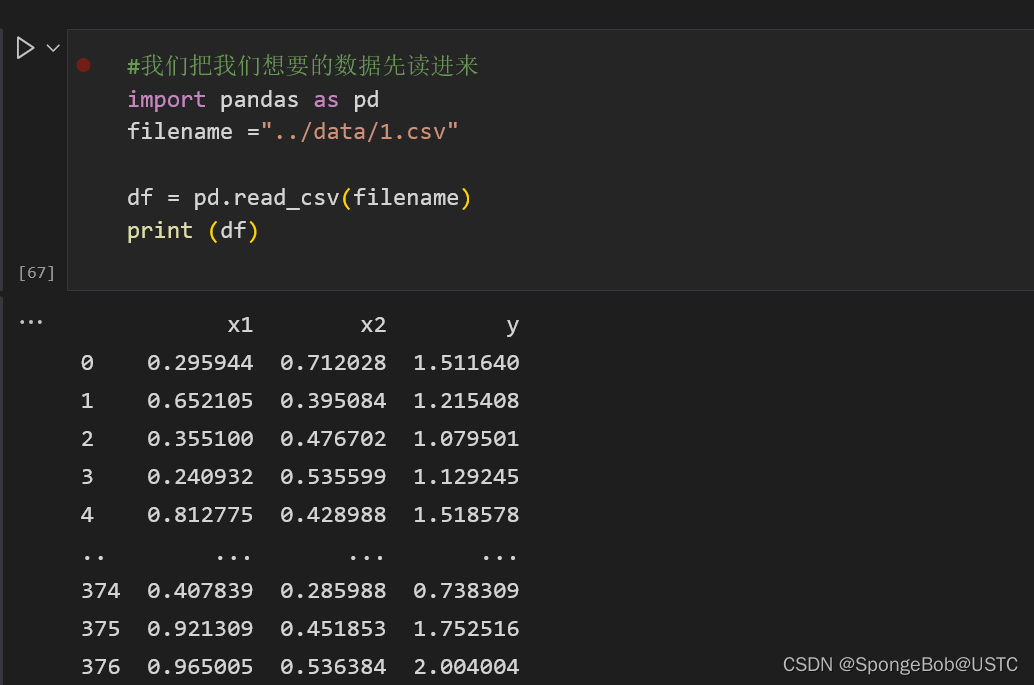
#我们把我们想要的数据先读进来
import pandas as pd
filename ="../data/1.csv"
df = pd.read_csv(filename)
print (df)
我们使用panda库进行数据的读取,注意,此时读进来的数据不是tensor的数据类型,是不能够直接放到网络中进行训练的,需要进行数据的转换。然后我们在filename里面选择的是相对路径,注意进行替换。
执行效果如下:
2.2对我们的数据进行处理,处理成我们模型能够接受的类型
print(type(df))
import numpy as np
import torch
x1=df["x1"]
#print (x1)
x2=df["x2"]
y=df["y"]
#print (x2)
#print (y)
x1 = np.array(x1)
x2 = np.array(x2)
y = np.array(y)
x1 = torch.unsqueeze(torch.FloatTensor(x1), dim=1)
x2 = torch.unsqueeze(torch.FloatTensor(x2), dim=1)
y = torch.unsqueeze(torch.FloatTensor(y), dim=1)
#print (y)
2.3自定义构建我们的网络层
#这个地方是我们要使用的网络
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Linear(2, 5), nn.Sigmoid(),
nn.Linear(5, 1))
print ("网络读入成功")
在这里我们构建了一个输入通道为2,输出通道为1,中间有5个隐藏神经元的网络。我们使用的激活函数是Sigmoid函数。
执行效果如下:

2.4查看一下我们的网络(在面对大且复杂的模型的时候,可以很良好的查看我们模型的样式,如果只是为了求结果,这段代码可不加)
X = torch.rand(size=(1,2), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
执行效果如下:

2.5将x1,x2进行张量的合并,合并之后一起作为输出
u =torch.cat([x1,x2],dim=1)
#print (u)
#print (type(u))
#net(u)
#print (y)
2.6 然后,进入炼丹环节(此环节有坑有坑,仔细看)
list1=[]
import matplotlib.pyplot as plt
optimizer = torch.optim.Adam(net.parameters(),lr=1e-2)
loss_func = torch.nn.MSELoss() # 均方差
#print(y)
#print (u)
epochs=2000
for i in range(epochs):
prediction = net(u)
loss =loss_func(prediction,y)
#print (loss)
list1.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(range(2000),list1)
plt.xlabel("epochs")
plt.ylabel("loss")
plt.show()
#print (i)
执行效果如下(有坑有坑!!)
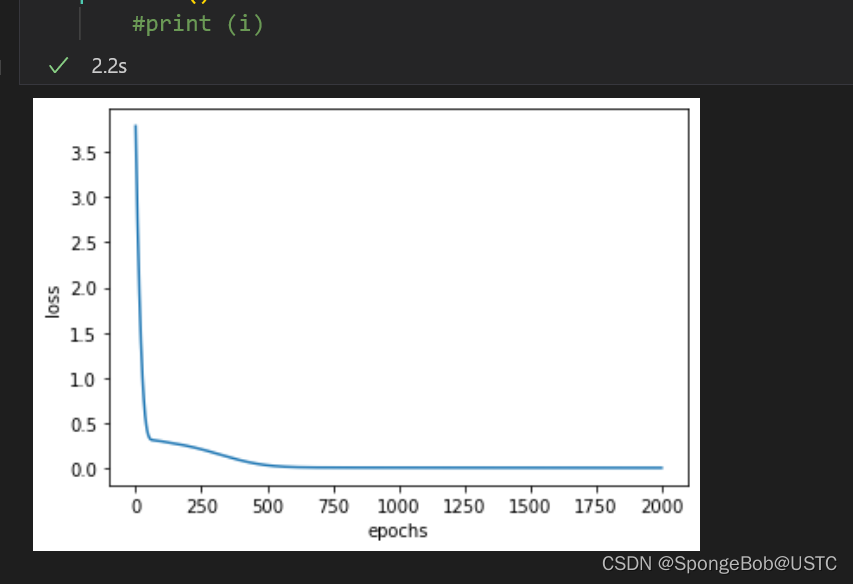
注意在这里我们可以看到,随着训练次数的增加,loss函数逐渐平滑,约等于我们的模型已经训练完毕,可以进行测试集进行测试了。但是,其实还没有训练好,我们再次启动训练函数!
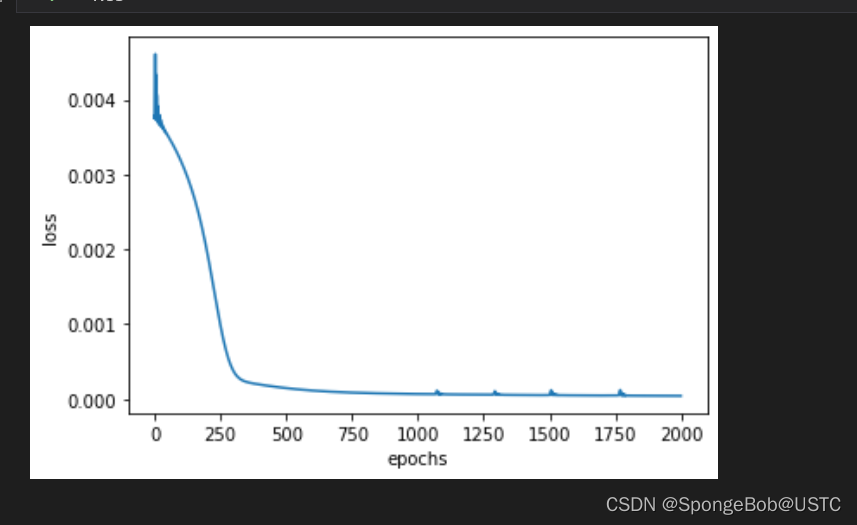
我们可以看到,loss函数仍然在下降,即训练完2000次之后,我们的神经网络仍然没有训练好,只是因为loss变化太小了,而在第一张图中,loss的y值一开始太大了,导致我们的图在1500次以后的loss下降显示不明显。但是从第二张图可以看出,大概到2250次我们的数据才收敛。
2.7测试我们的网络
test=torch.tensor([[0.4,0.6]])
print (net(test))
test2=torch.tensor([[0.437136137,0.584772431]])
print (net(test2))
test3=torch.tensor([[0.2,0.3]])
print (net(test3))
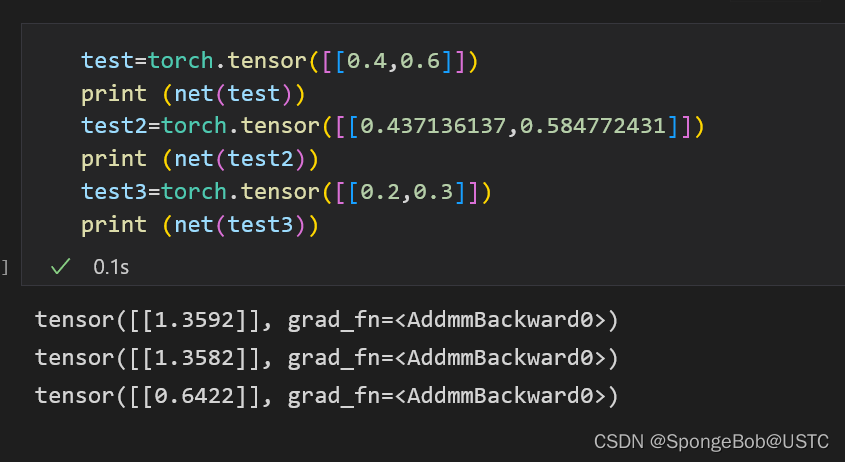
这里面的tensor的值即为我们测试的所预测值,我们使用一个简单的c语言代码来看,实际值为多少:
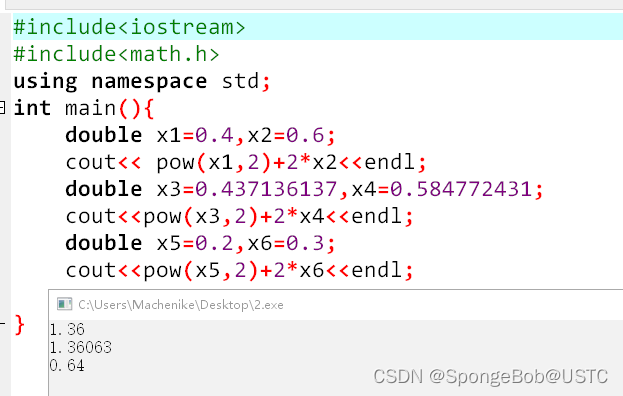
我们可以看到,我们的模型所预测的值和数据真实值十分的相近,可以默认为已经是一个训练好的模型了。















 3887
3887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









