







文章:Semantic Annotation of Mobility Data using Social Media
作者:F Wu, Z Li, WC Lee, H Wang, Z Huang.
来源:ACM WWW 2015.
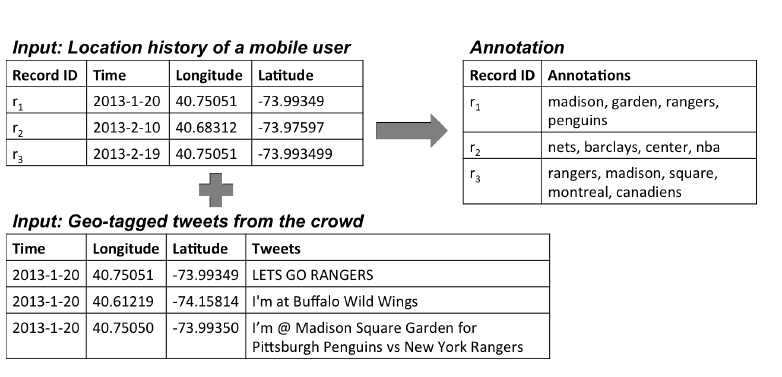
本文利用LBSN数据来标注轨迹数据,来发现用户旅行的目的,关键问题是得到和用户移动相关的词汇,为此定义了相关函数来描述,利用频率方法、高斯混合模型方法和KDE方法对相关词汇的密度进行建模,实验证明KDE最有效。
工作特点:
以前的方法是ststic方法,丢失了动态的时间信息,比如纽约的麦迪逊花园广场,可能举办各种比赛和演唱会,不同的时间有不同的活动。
LBSN数据的挑战之一是其中的文本是noisy的,含有大量不相关的信息;挑战之二是邻近区域的词频可能被少数的landmark所占据。
词频方法的不足:不能找到与位置相关的词。
高斯混合模型的不足:GMM的component数目在不同的词上面会不同;词真正的分布不一定是GMM,如受路网、经典等的影响。
KDE包含了词的局部性和相关性。
未来工作:
考虑时间的作用:
作者:F Wu, Z Li, WC Lee, H Wang, Z Huang.
来源:ACM WWW 2015.
本文利用LBSN数据来标注轨迹数据,来发现用户旅行的目的,关键问题是得到和用户移动相关的词汇,为此定义了相关函数来描述,利用频率方法、高斯混合模型方法和KDE方法对相关词汇的密度进行建模,实验证明KDE最有效。
工作特点:
以前的方法是ststic方法,丢失了动态的时间信息,比如纽约的麦迪逊花园广场,可能举办各种比赛和演唱会,不同的时间有不同的活动。
LBSN数据的挑战之一是其中的文本是noisy的,含有大量不相关的信息;挑战之二是邻近区域的词频可能被少数的landmark所占据。
词频方法的不足:不能找到与位置相关的词。
高斯混合模型的不足:GMM的component数目在不同的词上面会不同;词真正的分布不一定是GMM,如受路网、经典等的影响。
KDE包含了词的局部性和相关性。
未来工作:
考虑时间的作用:
landmark和event有区别,landmark密度一直很高,但event的密度在一定时间范围内很高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









