






Attacks on Machine Learning
文章目录
- Attacks on Machine Learning
- 1. The first one of attacks categories
- 2.The second one of attacks categories
- 3.The third one of attacks categories
- 3.1 Attacks on supervised learning (classification)
- 3.2 Attacks on supervised learning (regression)
- 3.3 Attacks on semi-supervised learning (generative models)
- 3.4 Attacks on unsupervised learning (clustering)
- 3.5 Attacks on unsupervised learning (dimensionality reduction)
- 3.6 Attacks on reinforcement learning
- 更多详细的资料:https://github.com/Billy1900/Privacy-and-Security-issues-in-machine-learning
Though AI brings great power, like any technology, is not immune to attacks.There are different categories of attacks on ML models depending on the actual goals of an attacker (Espionage, Sabotage, Fraud) and the stages of machine learning pipeline (training and production), or also can be called attacks on algorithm and attacks on a model respectively. They are Evasion, Poisoning, Trojaning, Backdooring, Reprogramming, and Inference attacks. Evasion, poisoning and inference are the most widespread now.
1. The first one of attacks categories
| Stage\Goal | Espionage | Sabotage | Fraud |
|---|---|---|---|
| Training | Inference by poisoning | Poisoning, Trojian, Backdooring | Poisoning |
| Production | Inference attack | Advesarial Reprogramming, Evasion(False negative evasion) | Evasion (False positive evasion) |
1.1 Espionage
Objective: The objective is to glean insights about the system and utilize the received information for his or her own profit or plot more advanced attacks.
real-life incident: A real-life privacy incident happened when Netflix published their dataset. While the data was anonymized, hackers were able to identify the authors of particular reviews. In the world of systems and proprietary algorithms, one of the goals will be to capitalize on a system’s algorithm, the information about the structure of the system, the neural network, the type of this network, a number of layers, etc.
1.2 Sabotage
Objective: The objective is to disable functionality of an AI system.
There are some ways of sabotaging:
- Flooding AI with requests, which require more computation time than an average example.
- Flooding with incorrectly classified objects to increase manual work on false positives. In case this misclassification takes place, or there is a need to erode trust in this system. For example, an attacker can make the system of video recommendation recommend horror movies to comedy lovers.
- Modifying a model by retraining it with wrong examples so that the model outcome will let down. It only works if the model is trained online.
- Using computing power of an AI model for solving your own tasks. This attack is called adversarial reprogramming.
1.3 Fraud
Objective: The objective is to misclassify tasks.
Attackers has two ways to do it–by interacting with a system at learning stage (Poisoning-to poison data) or production stage (Evasion-to exploit vulnerabilities to misoperation). It is the most common attack on machine learning model. It refers to design an input, which seems normal for a human but is wrongly classified by ML models.
2.The second one of attacks categories
Evasion, Poisoning, Trojaning, Backdooring, Reprogramming, and Inference attacks
2.1 Evasion (Adversarial Examples)
Evasion is a most common attack on machine learning model performed during production. It refers to designing an input, which seems normal for a human but is wrongly classified by ML models. A typical example is to change some pixels in a picture before uploading, so that image recognition system fails to classify the result. In fact, this adversarial example can fool humans. See an image below.

Some restrictions should be taken into account before choosing the right attack method: goal, knowledge, and method restrictions.
- Goal restriction (Targeted vs Non-targeted vs Universal)
- Confidence reduction — we don’t change a class but highly impact the confidence
- Misclassification — we change a class without any specific target
- Targeted misclassification — we change a class to a particular target
- Source/target misclassification — we change a particular source to a particular target
- Universal misclassification — we can change any source to particular target
- Knowledge restriction (White-box, Black-box, Grey-box)
- Black-box method — an attacker can only send information to the system and obtain a simple result about a class.
- Grey-box methods — an attacker may know details about dataset or a type of neural network, its structure, the number of layers, etc.
- White-box methods — everything about the network is known including all weights and all data on which this network was trained.
- Method restriction (L-0, L-1, L-2, L-infinity — norms):pixel difference
Research Work
- The first work in 2004. Adversarial classification
- white-box mode
- Grey-box mode
- Black-box mode
2.2 Poisoning:Widespread.
There are four broad attack strategies for altering the model based on the adversarial capabilities:
- Label modification: Those attacks allows adversary to modify solely the labels in supervised learning datasets but for arbitrary data points. Typically subject to a constraint on total modification cost.
- Data Injection: The adversary does not have any access to the training data as well as to the learning algorithm but has the ability to augment a new data to the training set. It’s possible to corrupt the target model by inserting adversarial samples into the training dataset.
- Data Modification: The adversary does not have access to the learning algorithm but has full access to the training data. The training data can be poisoned directly by modifying the data before it is used for training the target model.
- Logic Corruption: The adversary has the ability to meddle with the learning algorithm. These attacks are referred as logic corruption.
2.3 Trojianing
While Poisoning, attackers don’t have access to the model and initial dataset, they only can add new data to the existing dataset or modify it. As to Trojaning, an attacker still don’t have access to the initial dataset but have access to the model and its parameters and can retrain this model.
Research Work
2.4 Backdooring
The main goal is not only inject some additional behavior but to do it in such a way that backdoor will operate after retraining the system.
Research Work
- BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
- Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks
2.5 Reprogramming (adversarial reprogramming)
This is the most realistic scenario of a sabotage attack on the AI model. As the name implies, the mechanism is based on remote reprogramming of the neural network algorithms.
2.6 Inference attack (Privacy attack)
Most studies currently cover inference attacks at the production stage, but there are still some during training.
-
Model inversion attack (most common)
This attack method USES some APIS provided by the machine learning system to obtain some preliminary information of the model, and reverse analyze the model with such preliminary information to obtain some private data inside the model. The difference between this kind of attack and the member inference attack is that the member inference attack is aimed at a single training data, while the model reverse attack tends to obtain a certain degree of statistical information.
-
Model extraction attack (less common)
Model extraction attack is an attack method in which an attacker can infer the parameters or functions of a machine learning model by circulating data and viewing the corresponding response results, so as to copy a machine learning model with similar or even identical functions.
-
Membership inference attack (less frequent)
It refers to the given black box access rights of the data record and model to determine whether the record is in the training data set of the model. This Attack is based on the observation that for a machine learning model, there is a significant difference in uncertainty between the training set and the non-training set, so an Attack model can be trained to guess if a sample exists in the training set.
-
Attribute inference: guessing a type of data
Research Work
- Model Inversion attack
- Model extraction
- Membership inference attack
- Membership Inference Attacks Against Machine Learning Models
- Demystifying Membership Inference Attacks in Machine Learning as a Service
- ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models
- Machine Learning with Membership Privacy using Adversarial Regularization
Reference
3.The third one of attacks categories
This map illustrates high-level categories of ML tasks and methods.

3.1 Attacks on supervised learning (classification)
The supervised learning approach is usually used for classification which was also the first and most popular machine learning task targeted by security research.
Research Work
- The first attacks on classification dated 2004 – Advesarial Classification
3.2 Attacks on supervised learning (regression)
Regression is equaivalent to prediction in ML, and all technical aspects of regression can be divided into two categories: deep learning and machine learning.
Research Work
3.3 Attacks on semi-supervised learning (generative models)
Objective: Generative models are designed to simulate the actual data based on the previous decisions.
The following picture illustrates that G is Generator which taks examples from latent space and add some noise and D is discriminator which can tell if generated fake images look like real samples.
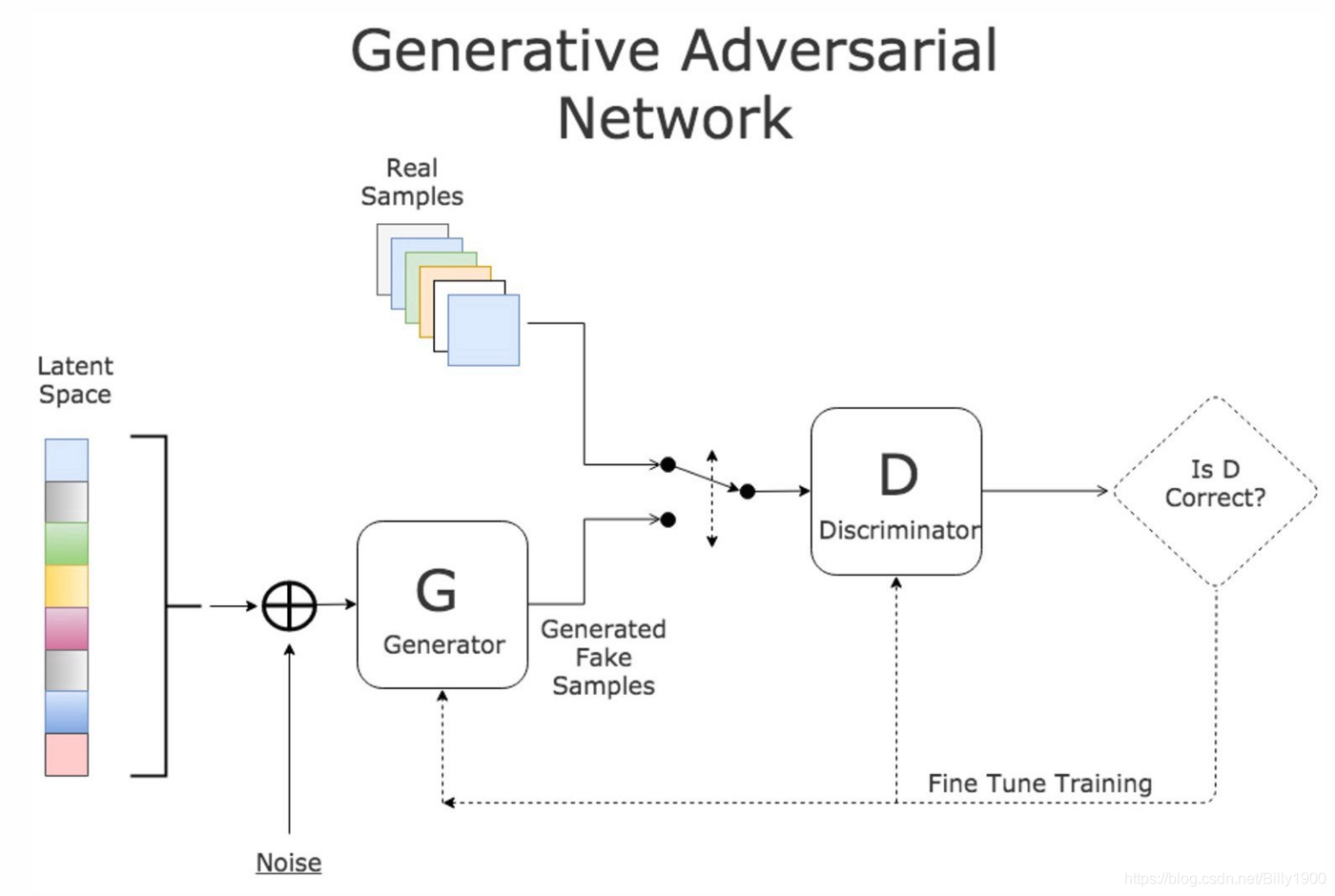
Research Work
- An example was mentioned in the article titled Adversarial examples for generative models
3.4 Attacks on unsupervised learning (clustering)
The most common unsupervised learning example is Clustering which is similar to classification with the only but major difference. For the information about the class of the data is unknown, and there is no idea whether this data can be classified.
However, there are fewer articles considering attacks on clustering algorithms. Clustering can be used for malware detection, and usually new training data comes from the wild, so an attacker can manipulate training data for malware classifiers and this clustering model.
Research Work
- A pratical attack on K-nearest neighbors–On the Robustness of Deep K-Nearest Neighbors
3.5 Attacks on unsupervised learning (dimensionality reduction)
Dimensionality reduction or generalization is necessary if you have complex systems with unlabeled data and many potential features. Although this machine learning category is less popular than others, there is an example where researchers performed attack on PCA-based classifier for detecting anomalies in the network traffic. They demonstrated that PCA sensitivity to outliers can be exploited by contaminating training data that allows adversary to dramatically decrease the detection rate for DOS attacks along a particular target flow.
Dimensionality reduction example is seen from the third space on the left to the second space on the right

Research Work
3.6 Attacks on reinforcement learning
Comparing to supervised or unsupervised learning, there is no data to feed into our model before it starts.
Research Work
- Vulnerability of Deep Reinforcement Learning to Policy Induction Attack: This paper has shown that adding adversarial perturbation to each frame of the game can mislead reinforcement learning policies arbitrarily.














 2772
2772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









