







模型窃取攻击防御《A Comprehensive Defense Framework Against Model Extraction Attacks》 来自 IEEE TDSC 2023
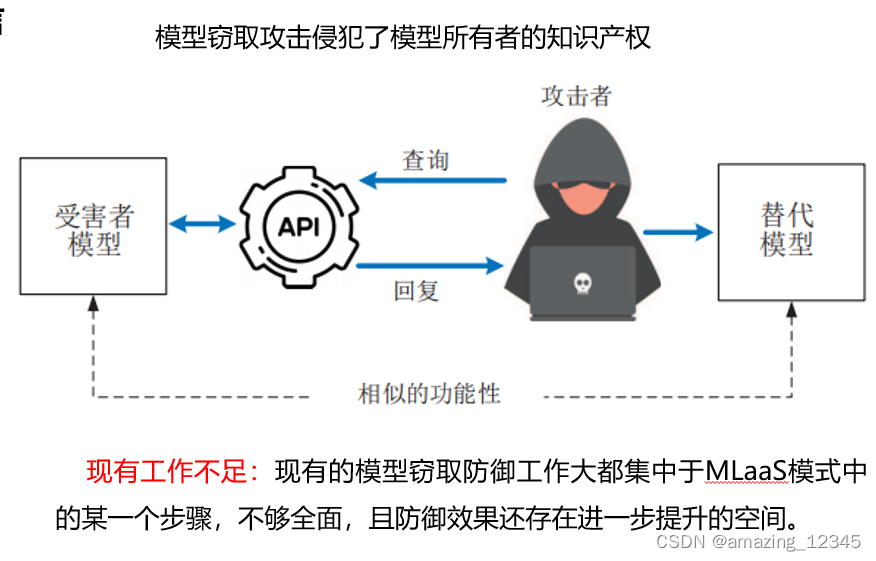
最近的研究表明,机器学习即服务中的预训练模型很容易受到模型窃取攻击的威胁。如图所示,攻击者使用恶意构造的查询样本来不断查询受害者模型,以获得回复的结果。然后利用这些(查询-回复)集合作为训练集来重建一个与原始模型(也称为受害者模型)功能相似的替代模型
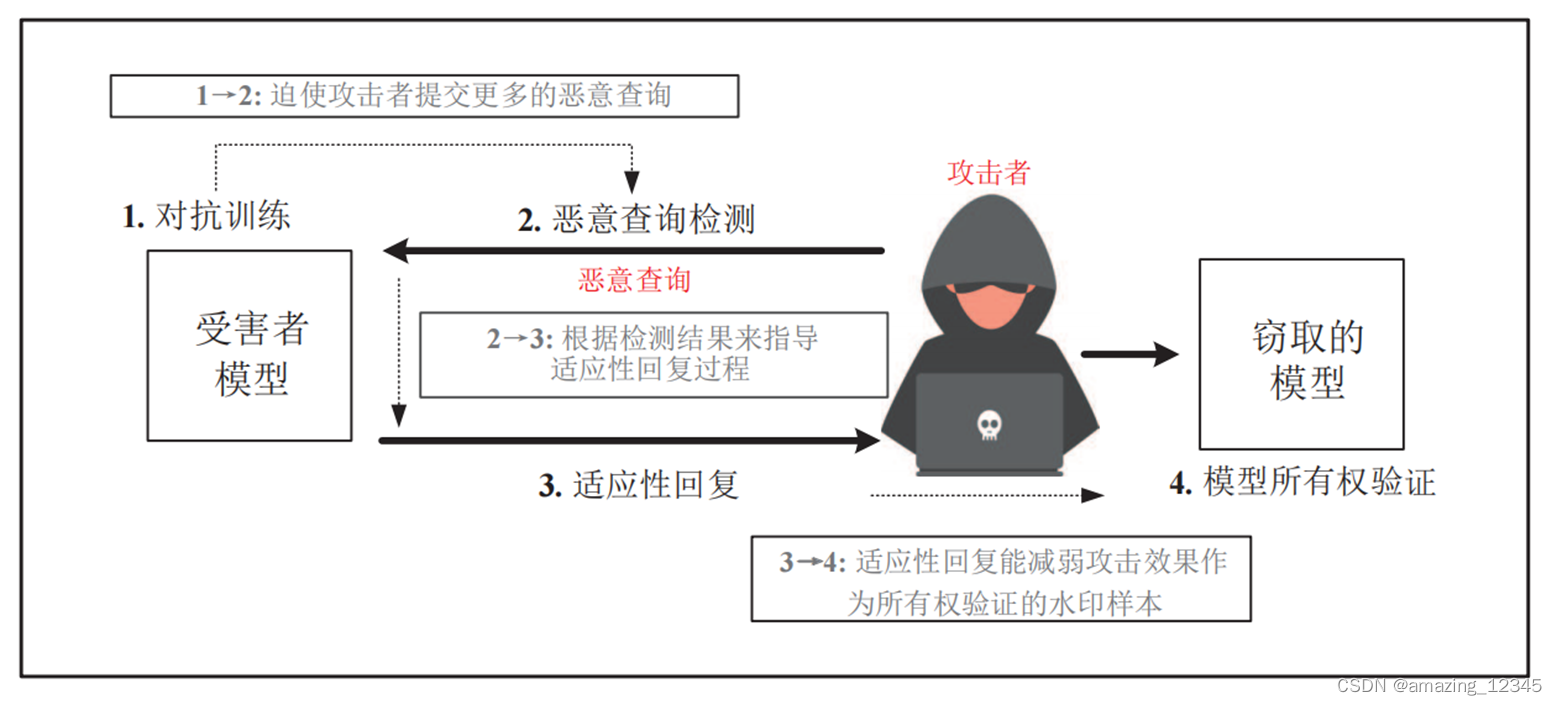
提出了全面高效的模型窃取攻击防御框架AMAO:在训练阶段施加对抗训练以获得更鲁棒的模型,并削弱模型窃取攻击的效果,导致攻击者需要提交更多的恶意查询才能达到预期的攻击目标。在这之后,恶意查询检测用来检测和识别恶意查询并标记恶意用户。然后,针对恶意用户,防御者采用自适应回复策略,用添加了扰动的结果回复恶意用户。这些扰动的结果不仅可以减弱模型窃取攻击的效果,还可以为后续的模型所有权验证步骤做准备。最后,模型所有权验证可以通过(扰动的样本-标签)集合进行验证。AMAO在模型的每个阶段都有相应的防御措施,各个阶段能够相互促进,并达到最佳的整体防御能力。
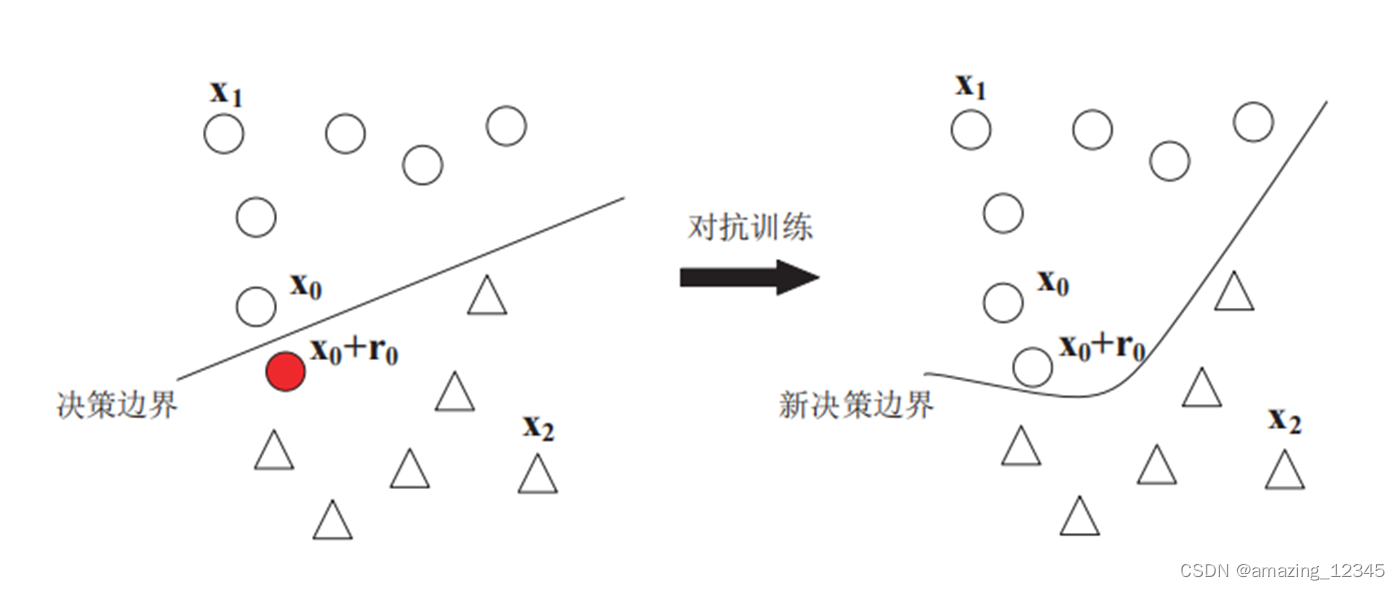

基于最优停止理论的标签翻转攻击来指导适应性回复: 防御者可以被视为标签翻转攻击的敌手,其目标是选择最佳的中毒样本来翻转标签,从而降低替代模型的性能。具体策略:首先观察前𝑀/𝑒−1个查询,并不选择它们。在接下来的𝑀−𝑀/𝑒+1个查询中。如果任何一个查询的置信度差距大于前𝑀/𝑒−1个查询的最大置信度差距,则该查询被选中进行标签翻转
最后就是模型所有权验证步骤
对于每个恶意用户,防御者维护一个扰动的结果集𝑊𝑖 (𝑖=1,2,…,𝑛)W_i (i=1,2,…,n),也称为水印集。以存储查询及对应的扰动的预测结果。对于可疑模型𝑓𝑠f_s,对每一个水印集𝑊𝑖W_i,防御者计算已验证的水印结果占该水印集总数的比例,其中水印的结果𝑥𝑗𝑖,𝑦𝑗𝑖(x_j^i,y_j^i )被验证是指𝑓𝑠𝑥𝑗𝑖=𝑦𝑗𝑖f_s (x_j^i )=y_j^i。如果验证比例高于设定的阈值𝜏τ,则该模型被认定为是通过模型窃取而得的非法模型。

实验部分略

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









