









文章目录
0. 前言
目前的文本分类任务很多是需要基于大量标签数据进行分类模型训练,特别是在类别数目很大的情况下,人工进行数据打标就显得费时费力。
《 Text Classification Using Label Names Only: A Language Model Self-Training Approach》(code)论文中给出了一种不需要标签数据,仅仅需要标签名称就能进行文本分类的方法LOTClass。
1. LOTClass分类方法整体流程
该弱监督文本分类的大致流程如下:
- Category Understanding via Label Name:将标签名称与语义相关的词进行关联;
- Masked Category Prediction:找到类别指示词并训练能够预测其隐含类别的模型;
- Self-Training:通过self-training进行泛化;
而在这个过程中,有一个预训练模型贯穿始终。论文中使用的预训练模型是bert。
2. LOTClass分类方法
2.1 Category Understanding via Label Name
在这一步中,主要将标签名称关联到一些语义相关的词。
当人看到一个标签的时候,我们能够基于人已有的知识,从这个标签联想到与之意思相近的其他词汇。而论文中的第一步,就是基于一个预训练模型,去学习每一个类别的标签名称相关联的词汇。
我们直观上会觉得,如果一次词出现的位置,可以被另一个词替换,那么这两个词的意思应该是相近或者同一类别的。而刚好,bert的mlm训练方式就是将语料中的句子mask掉某一个词,来预测这个词。因此,论文中就是按照mlm训练时的输入方式,通过标签名称词出现的上下文,来预测标签名称词所在的位置在词表中的概率分布,从而也就表示了词表中的词在标签名称所在位置可能出现的概率。
p
(
w
∣
h
)
=
s
o
f
t
m
a
x
(
W
1
σ
(
W
2
h
+
b
)
)
p(w|h)=softmax(W_{1} \sigma(W_2h+b))
p(w∣h)=softmax(W1σ(W2h+b))
这个过程非常简单,跟mlm训练时基本一样。如上面这个公式中,
h
h
h就是预训练bert模型输出的标签名称词对应的隐向量,后面接的全连接和softmax层,对应的
W
1
,
W
2
W_1, W_2
W1,W2和
b
b
b参数也都是在MLM训练中已经训练好了的。

上面表格中,就是通过这个方式得到的分别在两个句子的sports位置的,经过预训练语言模型得到的可以放在对应位置的词。论文中根据经验,对每个句子上的标签词位置的预测结果选取top50个词作为可以采纳的替换词。但是我们从上面这两个句子可以看到,在语料中,同样一个词的含义不同,出现的上下文所要表达的意思也不同,对于同一个标签词在有些句子中最终的预测结果跟我们期望的不太符合。因此论文中对每一个标签词的所有可替换词进行统计,选取预测出现次数最高的100个词作为每一个标签词最终的可替换词,也就是我们在这一步中所需要的与标签名称的语义相关词
2.2 Masked Category Prediction
在这一步中,主要是找类别指示词和训练模型。
在没有打标数据,而仅仅有类别名称的时候,我们直观想到的简单粗暴的文本分类方法就是,如果文本中出现哪个类别名称,那就判为哪个类别。但是这样做有两个问题。
- 文本中出现类别名称但不一定表示这个类别,比如我们前面讲的sport的第二个句子就是这样;
- 很多文本并没有出现类别名称。
为了解决这两个问题,论文中引出了masked category prediction(MCP)任务, 流程如图。这个MCP任务是通过寻找类别指示词来建立监督任务训练分类模型的。
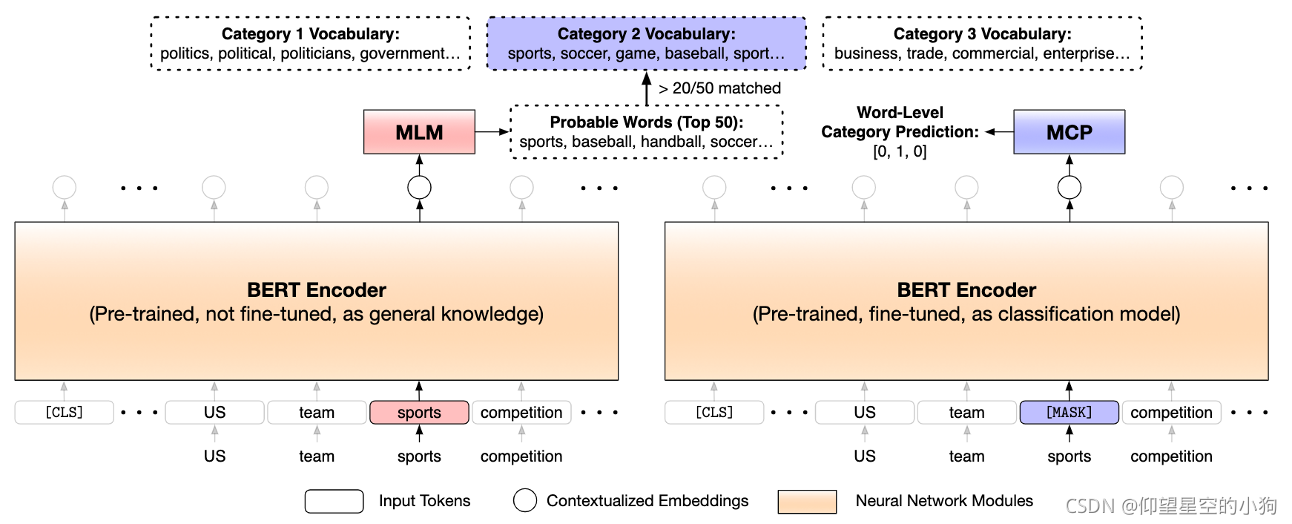
上图中左边首先还是使用上一步中使用到的预训练模型,来对文本中的每一个词,而不是仅仅针对类别名称词,来预测每一个词可能的替换词。这个过程也是先通过bert编码器得到对应输出的向量,然后输入到做MLM训练中接的分类器进行分类预测,也是选取top50个词作为对应位置的可替换词。
我们在上一步Category Understanding via Label Name中已经获得了所有类别词的关联词汇的词表了。如果我们对于文本中的某一个词的50个可替换词种有20个以上的词跟某一个类别的关联词汇表匹配,则认为文本中的这个词就是类别指示词,指示的就是相匹配的这个类别。比如,图中的这个sports,在这个上下文文本场景中得到的可替换词跟类别2有20个词以上的匹配,则sports就是这个类别指示词,类别2就是指示的类别。经过对语料中的每一个词进行这样的操作,我们就能得到一堆类别指示词和对应的类别。然后我们就可以做有监督训练了。
这里的有监督训练就是将类别指示词进行mask,作为被预测对象,预测的标签就是对应的类别。在上图的右侧,将被预测的词对应位置的bert编码器输出输入到一个MCP的分类器,这个分类器论文中使用的是一个线性分类器,使用的损失函数就是交叉熵。比如,刚才例子中提到的类别指示词sports对应的是类别2,总共有3个类别,那么对应的标签就是[0,1,0]
2.3 Self-Training
这一步是进行自训练。
其实在完成第二步之后就已经得到了一个在新语料集上训练过的模型,可以进行文本分类。但是论文中又进一步提出进行自训练的方式来优化模型。主要是有两个原因:
- 在MCP任务中,有很多文本可能找不到类别指示词,因此没有被充分利用;
- MCP任务中仅仅使用被预测词位置对应的输出向量来进行模型训练,而没有使用
[cls]这个能够表示整个文本序列信息的输出向量。
论文中所提出的自训练方法,是通过迭代的方式使用每一次当前模型的预测结果分布P和目标分别Q,来对模型进行优化。这里使用的目标函数就是KL散度。
L
S
T
=
K
L
(
Q
∣
∣
P
)
=
∑
i
=
1
N
∑
j
=
i
k
q
i
j
l
o
g
q
i
j
p
i
j
L_{ST}=KL(Q||P)=\sum^{N}_{i=1}\sum^{k}_{j=i}q_{ij}log\frac{q_{ij}}{p_{ij}}
LST=KL(Q∣∣P)=i=1∑Nj=i∑kqijlogpijqij
q
i
j
=
p
i
j
2
/
f
j
∑
j
′
(
p
i
j
′
2
/
f
j
′
)
,
f
j
=
∑
i
p
i
j
q_{ij}=\frac{p^2_{ij}/f_j}{\sum_{j'}(p^2_{ij'}/f_{j'})}, f_j=\sum_ip_{ij}
qij=∑j′(pij′2/fj′)pij2/fj,fj=i∑pij
p
i
j
=
p
(
c
j
∣
h
d
i
:
[
C
L
S
]
)
p_{ij}=p(c_j|h_{d_i:[CLS]})
pij=p(cj∣hdi:[CLS])
公式中的
P
P
P就是刚才说的[CLS]处的预测结果分布,Q是目标分布,N就是样本个数,K就是类别个数。公式中的
p
p
p我们是能够通过模型预测得到的,那么
q
q
q是从哪里来的呢?因为这里是无监督训练,没有标签,这里的目标分布
Q
Q
Q是通过
P
P
P来计算得到的。论文中提到的计算
q
q
q的方法有两个,hard labeling 和soft labeling。但是由于hard labeling是直接将预测概率大于某一阈值的位置设置为1,作为groud truth,这样容易引入干扰。因此论文中采用的是soft labeling方法。Soft labeling的方法是将高置信度度的方法进行平方和归一化。
由上面几个公式得到Loss之后,就可以按照这种方式来进行模型训练和迭代了。
3. result and analyse
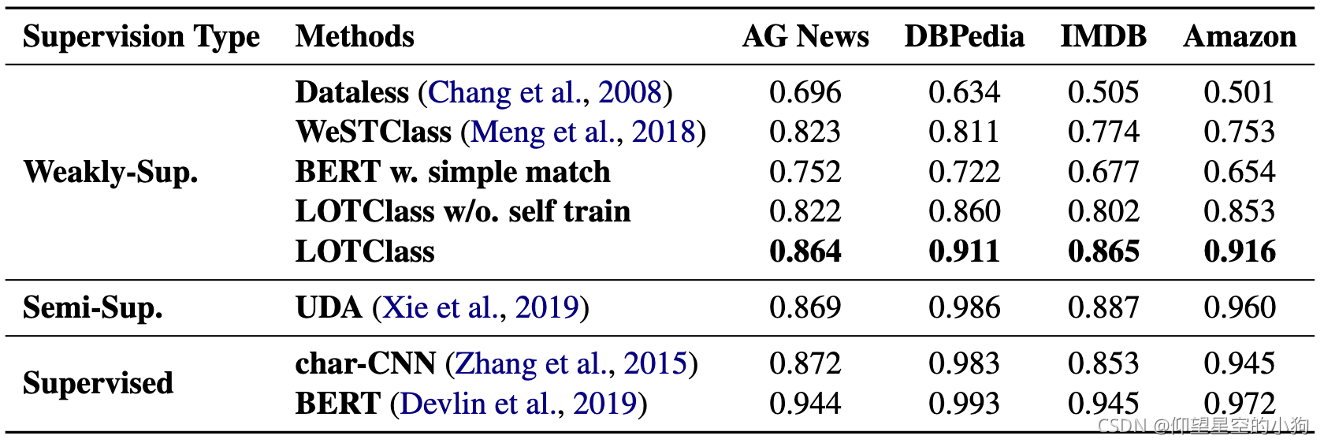
最后介绍一下这个模型的运行结果。论文中在AG News, DB pedia, IMDB, Amazon这四个数据集上进行测试,结果中,LOTClass比其他一些弱监督方法都要好,即使是没有self-train,LOTClass也比其他模型效果要好。
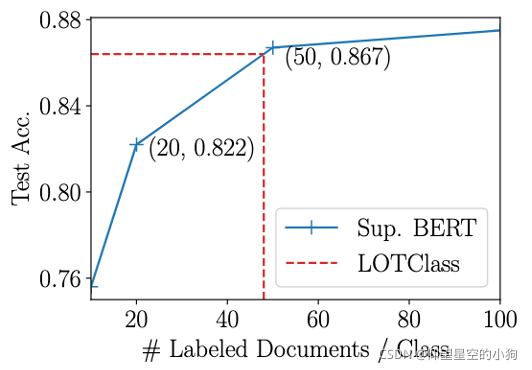
然后,作者还进一步探究了使用这种弱监督方式,能够相当于有多少标签数据的情况下的有监督学习。作者将LOTClass方法和具有不同标签数据量的有监督bert方法进行比较。在上图中可以看出,LOTClass方法大约相当于每一类别有48个标签数据的情况下的bert的效果。如此看来,我们在分类中,如果类别数目比较少,手动打标签的成本不高的情况下,还是通过手动打标然后使用Bert分类会比较合适。但是当类别数目比较多的情况下,手动打标成本比较高时,可以尝试使用LOTClass方法。

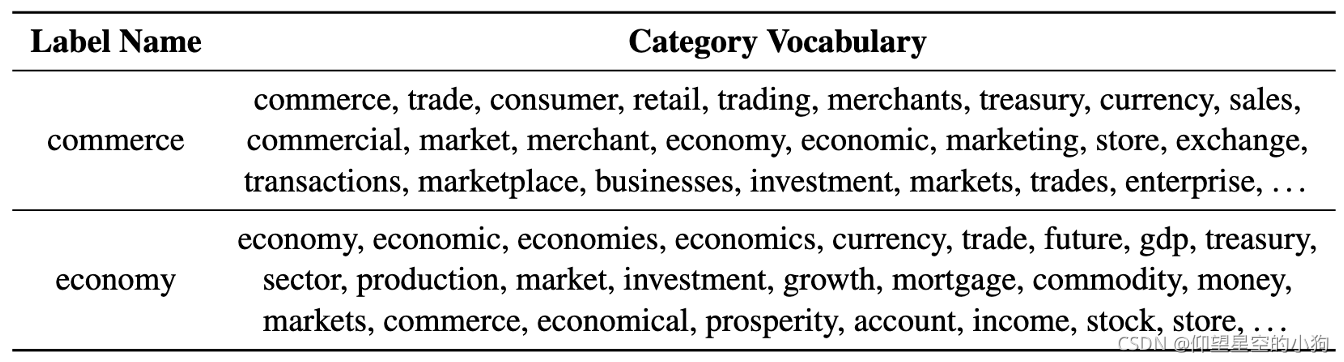
然后,作者还对该方法对标签变化的鲁棒性进行的分析。作者将AG news数据集中business标签名称替换为commerce和econmy,同样进行这两个标签名称和语义相关词的关联计算,得到的新的标签名称对应的语义相关词。结果发现有一半跟原来business时候的是一样的,另外一半也是也是含有相似的意思。从而证明了,这个方法对标签名称变化的敏感性不高,因为这个方法不是单单使用标签名称这个词来做语义相关词的关联,而是通过上下文来进行相关词的查找和关联。
小结
- bert等训练模型不仅可以用于做分类,还可以提供文本中某一位置的候选词(也可以称之为可替换词,关联词等),以及根据label name来获取seed word(相当于该篇文章中的类别指示词)。
- 在无标签的情况下,通过本文self-training方法中提到的生成soft labeling,计算KL散度,可以一定程度上对模型进行训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









