







1 Batch Normalization(BN)的作用
1.1 特征分布对神经网络训练的作用
在神经网络的训练过程中,我们一般会将输入样本特征进行归一化处理,使数据变为均值为0,标准差为1的分布或者范围在0~1的分布。因为当我们没有将数据进行归一化的话,由于样本特征分布较散,可能会导致神经网络学习速度缓慢甚至难以学习。
用2维特征的样本做例子。如下两个图
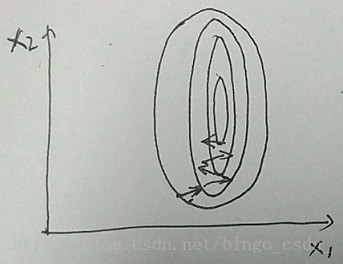
上图中样本特征的分布为椭圆,当用梯度下降法进行优化学习时,其优化过程将会比较曲折,需要经过好久才能到达最优点。
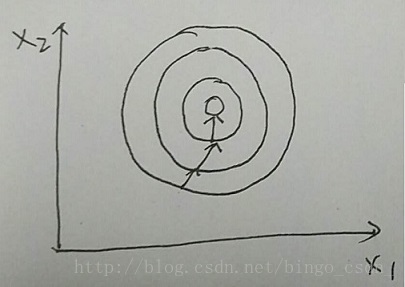
上图中样本特征的分布为比较正的圆,当用梯度下降法进行优化学习时,其有过的梯度方向将往比较正确的方向走,训练比较快就到达最优点。
因此一个比较好的特征分布将会使神经网络训练速度加快,甚至训练效果更好
1.2 BN的作用
但是我们以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过
σ(WX+b)
σ
(
W
X
+
b
)
这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。BN在神经网络训练中会有以下一些作用:
- 加快训练速度
- 可以省去dropout,L1, L2等正则化处理方法
- 提高模型训练精度
2. BN的原理
既然BN这么厉害,那么BN究竟是怎么样的呢?
BN可以作为神经网络的一层,放在激活函数(如Relu)之前。BN的算法流程如下图:

1. 求上一层输出数据的均值
μβ
μ
β
2. 求上一层输出数据的标准差 σ2β σ β 2
3. 归一化处理,得到 xi^ x i ^
4. 对经过上面归一化处理得到的数据进行重构,得到 yi y i
上述是BN训练时的过程,但是当在投入使用时,往往只是输入一个样本,没有所谓的均值 μβ μ β 和标准差 σ2β σ β 2 ,那该怎么办呢?此时,网络中使用的均值 μβ μ β 是计算所有batch μβ μ β 值的平均值得到,标准差 σ2β σ β 2 采用每个batch σ2β σ β 2 的无偏估计得到。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









