







文章目录
0. 前言
最近在看王昊奋老师的《知识图谱》,打算做一下学习笔记,当作是知识梳理。
这篇文档主要梳理知识图谱中的知识抽取方面的内容。在知识抽取中,有面向非结构化数据,半结构化数据,以及结构化数据的知识抽取。非结构化数据指的是平时看到的文本,比如新闻文稿;结构化数据是指整理过的具有比较严格的结构关系的数据,比如企业中关系数据库中的数据;半结构化数据是指具有一定的结构化形式,但仍然需要进行自然语言处理的数据,比如百度百科中整理过的词条信息。
这篇文章中,主要是围绕面向非结构化数据的知识抽取进行介绍。在非结构化数据的知识抽取中,主要一下有三个子任务:
- 实体抽取
- 关系抽取
- 事件抽取
下面主要针对这三个子任务进行介绍。
1. 实体抽取
实体抽取,也就是平时所说是明明实体识别(NER),主要是从文本中抽取实体信息元素,包括人名、机构名、地名、时间等等。比如
鸣人成了木叶忍者村的火影。
上面这个句子中鸣人是人名,木叶忍者村是组织,火影是职业。
实体抽取的方法主要有:
- 基于规则的方法
- 基于统计模型的方法
- 基于深度学习的方法
1.1 基于规则的方法
基于规则的方法主要是根据领域专家的知识,构建实体抽取规则,再将这些规则与文本进行匹配,识别命名实体。这中方法的优点是在小数据集上可以达到很高的准确率和召回率,但缺点是在大数据集上规则的构建成本比较大,且迁移成本高。
1.2 基于统计模型的方法
除了基于规则之外,还可以使用统计学习模型的方法对文本进行序列标注,实现实体抽取。在实体抽取中,比较常用的统计模型有隐马尔可夫模型(HMM),条件随机场模型(CRF)等。在使用以上统计模型进行实体抽取的方法主要涉及训练语料标注,特征定义和模型训练。
1.2.1 训练语料标注
在这种序列标注任务的训练中,一般第一步是获取标注数据,而书中介绍了BIESO、IOB和IO等方法。就是在每个word上标注对应的标记,表示与实体的关系。以下给出BIESO的各个标记的含义,IOB和IO也是对应含义:
B,即Begin,表示开始
I,即Intermediate,表示中间
E,即End,表示结尾
S,即Single,表示单个字符
O,即Other,表示其他,用于标记无关字符
下面给出一个标注的例子。
| 标注体系 | 鸣 | 人 | 成 | 了 | 木 | 叶 | 忍 | 者 | 村 | 的 | 火 | 影 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BIESO | B-PER | E-PER | O | O | B-ORG | I-ORG | I-ORG | I-ORG | E-ORG | O | B-JOB | E-JOB |
| IOB | B-PER | I-PER | O | O | B-ORG | I-ORG | I-ORG | I-ORG | I-ORG | O | B-JOB | I-JOB |
| IO | I-PER | I-PER | O | O | I-ORG | I-ORG | I-ORG | I-ORG | I-ORG | O | I-JOB | I-JOB |
1.2.2 特征定义
在进行模型训练之前,我们需要计算每一个词的一组特征作为模型的输入。可以使用的特征包括词级别特征,词典特征和文档级别特征。词级别特征有首字母是否大写、是否含数字、词性等;词典特征依赖外部词典定义,比如预定义的词典、地名列表、商品列表等;文档级别特征是基于整个语料文档计算得到的,比如词频等。
定义什么特征对于命名实体识别结果有较大的影响,因此需要根据业务场景的不同选择合适的特征。
1.2.3 训练模型
前面已经提到过,使用的模型可以有HMM或CRF之类的模型进行训练。关于这两个模型这里就不进行详细的介绍,本篇文章主要对知识抽取进行总体介绍,否则每个模型都可以写一大堆,请见谅(主要还是我懒……)。
1.3 基于深度学习的方法
上一节中提到的统计方法做的实体识别非常依赖于特征的定义,而基于神经网络的深度学习方法则可以自动提取合适的特征。一般我们会使用不同是神经网络在命名实体识别中扮演编码器的角色,通过神经网络对输入进行编码得到每一个词的向量表示,然后再通过CRF模型输出每一个词的标注结果。
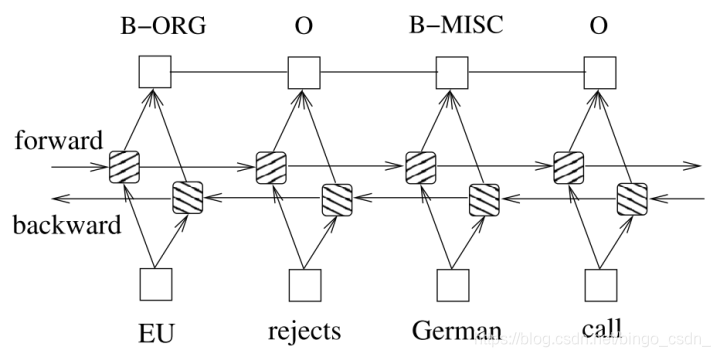
比如,BiLSTM-CRF模型,如下图。首先会对输入的词进行embedding,然后将词向量输入到双向LSTM,将正向和反向的LSTM进行拼接之后,再将拼接后的词向量喂入CRF进行命名实体识别的序列标注。
2. 关系抽取
在非结构化数据中,关系抽取主要是从文本中抽取两个或多个实体之间的语义关系。关系抽取和实体抽取密切相关,一般是在实体识别之后,在抽取实体之间可能存在的关系。关系抽取的方法可以分为:
- 基于模板的关系抽取方法
- 基于监督学习的关系抽取方法
- 基于弱监督学习的关系抽取方法
2.1 基于模板的关系抽取方法
与基于规则的实体抽取类似,基于模板的关系抽取方法同样也是依赖于领域专家的知识进行模板编写,从文本中匹配具有特定关系的实体。
比如,当我们想抽取“父子(女)”关系的实体的时候,我们可以观察到一些包含“父子(女)”关系的例句:
鸣人与父亲波风水门一起对抗带土。
路飞与父亲蒙奇·D·龙很少在一起。
于是我们可以抽象出模板
[X]与父亲[Y]…
可以用上述模板来抽取“父子(女)”关系。
2.2 基于监督学习的关系抽取方法
基于监督学习的关系抽取的一般步骤有:
- 预定义关系的类型
- 人工标注数据
- 设计关系识别所需的特征
- 选择分类模型并训练评估
其中,特征的设计与定义对关系抽取的结果非常重要。根据不同场景可以设计不同的特征。比如,对于句子
鸣人经过艰苦的训练,终于学会使用九尾查克拉,并在忍界大战中建立战功。
我们可以使用实体鸣人和九尾查克拉,以及实体之间的词[经过艰苦的训练,终于学会使用]作为特征,也可以使用依存树中的路径作为特征。
传统的方法需要通过人工构建特征来进行关系抽取,而基于深度学习的方法则不需要人工构建特征,神经网络能够自动进行特征构建。目前,基于深度学习的关系抽取方法主要包括流水线方法和联合抽取方法。流水线方法是将实体抽取和关系抽取分开处理,但是流水线方法的缺点是关系抽取依赖实体抽取效果,可能存在错误累积。而另一种联合抽取方法是将实体抽取和关系抽取结合,两者在模型中共同优化。
2.3 基于弱监督学习的关系抽取方法
在实际使用中,很多情况都是缺少有标注的数据,此时,就只能利用少量的标注数据进行弱监督学习。关系抽取中,常用的弱监督学习方法有远程监督和Bootstrapping。
- 远程监督方法
远程监督的基本假设是:
如果两个实体在知识图谱中存在某种关系,那么包含这两个实体的句子均表达来这种关系。
比如,在知识图谱中存在“师徒”的实体关系(自来也, 鸣人),那么包含实体自来也和鸣人的句子都被用作“师徒”实体关系的正例(有点简单粗暴)。该方法的一般步骤为:
- 从知识图谱中抽取存在目标关系的实体对
- 从非结构化文本中抽取含实体对的句子作为训练样本
- 训练监督学习模型进行关系抽取
远程监督方法可以大量节省人工标注的工作量。但是,基于远程监督的假设,也会有大量的噪声引入,造成语义漂移。
- Bootstrapping
Bootstrapping方法是一种迭代的方法。该方法利用少量的实例作为初始种子集合,然后在种子集合上学习获得关系抽取的模板,再利用模板抽取更多的实例,加入到种子集合中,如此不断迭代,从文本中抽取关系的大量实例。
3. 事件抽取
事件抽取指从自然语言文本中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,如事件发生的时间、地点、原因、参与者等。一般事件抽取包含的子任务有:
- 识别事件触发词及事件类型
- 抽取事件元素的同时判断其角色
- 抽取描述事件的词组或句子
- 事件属性标注
- 事件共指消解
跟前面关系抽取类似,事件抽取也是分流水线方法和联合抽取方法,两种方法之间的利弊也是差不多。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









