







0 语音识别技术路线大致框图

如上图所示,语音识别的大致过程可以分为以下几步:
1、语音输入——这个过程可以通过电脑上的声卡来获取麦克风中输入的音频信号,或者直接读取电脑中已经存在的音频文件;
2、音频信号特征提取——在得到音频信号之后,需要对音频信号进行预处理,然后对预处理之后的音频信号进程特征提取,MFCC是最常用的声学特征;
3、声学模型处理——把语音的声学特征分类对应到音素或字词这样的单元;
4、语言模型处理——用语言模型接着把字词解码成一个完整的句子,于是就得到了最终的语音识别结果。
1 语音输入
语音信号的输入方法可以有两种:
1、通过电脑上的声卡读取麦克风中输入的语音信号,实现实时语音信号采集;
2、读取电脑本地中的.wav或.mp4文件获取语音信号。
2 音频信号特征提取
2.1 语音信号分帧处理
本节内容详细请参考 语音信号处理中怎么理解分帧
语音信号处理常常要达到的一个目标,就是弄清楚语音中各个频率成分的分布。做这件事情的数学工具是傅里叶变换,而傅里叶变换要求输入信号是平稳的。语音在宏观上来看是不平稳的——你的嘴巴一动,信号的特征就变了。但是从微观上来看,在比较短的时间内,嘴巴动得是没有那么快的,语音信号就可以看成平稳的,就可以截取出来做傅里叶变换了。因此,我们需要对语音信号进行分帧处理,截取出来的一小段信号就叫一帧。
那么一帧有多长呢?帧长要满足两个条件:
1、从宏观上看,它必须足够短来保证帧内信号是平稳的。前面说过,口型的变化是导致信号不平稳的原因,所以在一帧的期间内口型不能有明显变化,即一帧的长度应当小于一个音素的长度。正常语速下,音素的持续时间大约是 50~200 毫秒,所以帧长一般取为小于 50 毫秒。
2、从微观上来看,它又必须包括足够多的振动周期,因为傅里叶变换是要分析频率的,只有重复足够多次才能分析频率。语音的基频,男声在 100 赫兹左右,女声在 200 赫兹左右,换算成周期就是 10 毫秒和 5 毫秒。既然一帧要包含多个周期,所以一般取至少 20 毫秒。
一帧音频信号在经过傅里叶变换之后,信号两端的部分被削弱了,没有像中央的部分那样得到重视。弥补的办法是,帧不要背靠背地截取,而是相互重叠一部分。相邻两帧的起始位置的时间差叫做帧移,常见的取法是取为帧长的一半,或者固定取为 10 毫秒。
2.2 声学特征MFCC
本节内容详细请参考 MFCC特征原理
2.2.1 梅尔频率
梅尔刻度是一种基于人耳对等距的音高(pitch)变化的感官判断而定的非线性频率刻度。和频率的赫兹的关系如下:
所以当在梅尔刻度上面上是均匀分度的话,对于的赫兹之间的距离将会越来越大,所以梅尔刻度的滤波器组的尺度变化如下:
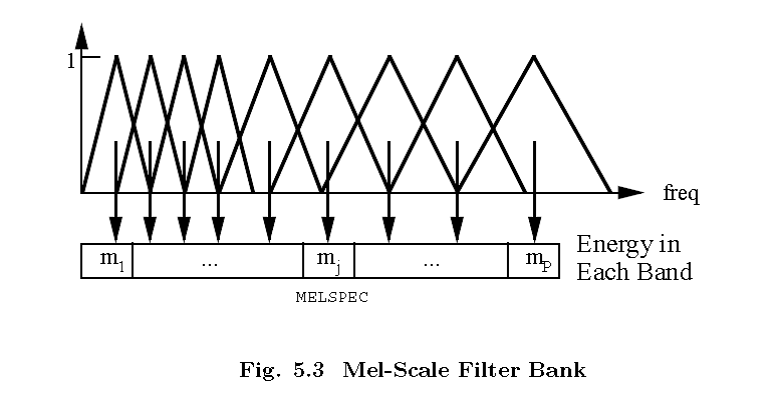
梅尔刻度的滤波器组在低频部分的分辨率高,跟人耳的听觉特性是相符的,这也是梅尔刻度的物理意义所在。
2.2.2 倒谱分析
倒谱的含义是:对时域信号做傅里叶变换,然后取log,然后再进行反傅里叶变换。可以分为复倒谱、实倒谱和功率倒谱,我们用的是功率倒谱。
倒谱分析可用于将信号分解,两个信号的卷积转化为两个信号的相加。

假设上面的频率谱X(k),时域信号为x(n)那么满足
考虑将频域X(k)拆分为两部分的乘积:
假设两部分对应的时域信号分别是h(n)和e(n),那么满足:
此时我们是无法区分开h(n)和e(n)。
对频域两边取log:
然后进行反傅里叶变换:
假设此时得到的时域信号如下:
声学模型
语音识别中的声学模型将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入,生成声学模型得分。个人理解是,将前面得到的声学特征转化为发音中的音符。目前使用比较多的声学模型是具有记忆功能的RNN或LSTM网络。
本文将简要介绍LSTM网络。
由于语音是有顺序性的,也就是前面说的字跟后面说的字之间,或者前面发的音与后面发的音之间是有联系的,因此,使用有记忆行的网络模型比较符合语音的特点。

如上图所示,图中为LSTM中的神经元结构,其神经元的输出会反过来在下一轮重新作为输入,从而是神经元能够记住上一轮情况,从而实现记忆功能。将该图按时间序列展开得下图:

实际上,LSTM网络的神经元比较复杂,其中含有输入们,输出门,遗忘门(如下图),通过这些门能够控制网络想要记忆的内容以及其时间的长短。

语音模型
语言模型是用来计算一个句子出现概率的概率模型。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的情况下预测下一个即将出现的词语的内容。换一个说法说,语言模型是用来约束单词搜索的。它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
语言模型分为三个层次:字典知识,语法知识,句法知识。
经过上述步骤处理之后,便能够得到输入语音的内容。















 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









