







0.简史
1.激活函数
2.数据预处理
3.权值初始化
4.Batch Normalization
5.训练流程
6.超参数优化
0.简史
Frank Rosenblatt, ~1957: Perceptron 硬件实现
Widrow and Hoff, ~1960: Adaline/Madaline 硬件实现
Rumelhart et al. 1986: First time back-propagation became popular 反向传播的提出
Hinton and Salakhutdinov, 2006: Reinvigorated research in Deep Learning 逐层预训练+整体微调
George Dahl, Dong Yu, Li Deng, Alex Acero, 2010:《ontext-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition》 语音领域突破
Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, 2012: 《Imagenet classification with deep convolutional neural networks》图像领域突破
1.激活函数(Activation Functions)
上一节中已经粗略介绍过常用的激活函数,现在详细考察每个激活函数的优缺点。
(1)Sigmoid函数
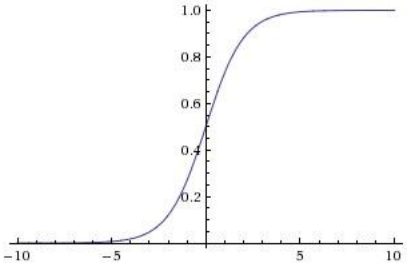
将数值挤压到[0,1]区间
契合生物神经元的饱和激活率形式,早期得到广泛应用
缺点
饱和区域的导数几乎为零,造成反向传播中的梯度消失现象
输出不是关于原点对称的,影响收敛速度
指数运算exp()稍微耗时
(2)双曲正切函数tanh
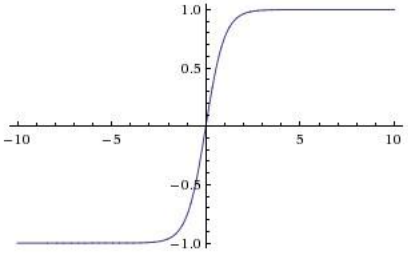
将数值挤压到[-1,1]区间
优点
输出关于原点对称
缺点
饱和区域导数几乎为零,造成反向传播中的梯度消失现象
(3)修正线性单元(Rectified Linear Unit,ReLU)
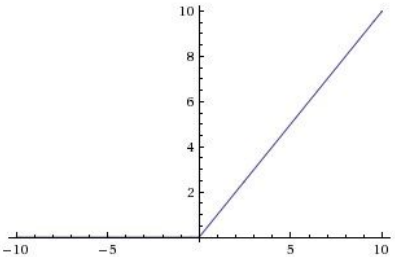
优点
在输出为正时不存在饱和区域
计算复杂性低
收敛速度比sigmoid/tanh快很多,约6倍
缺点
不是关于原点对称的
在输出为负时梯度为零,反向传播不会更新梯度值
另
dead ReLU现象,主要有两种原因:一是初始化时即使得ReLU进入未激活状态,所以一般初始化ReLU神经元的偏置为小的正值(如0.01);二是由于学习率太大,参数更新使得函数值进入负值区域,这样的失活一般不可逆。
(4)Leaky ReLU
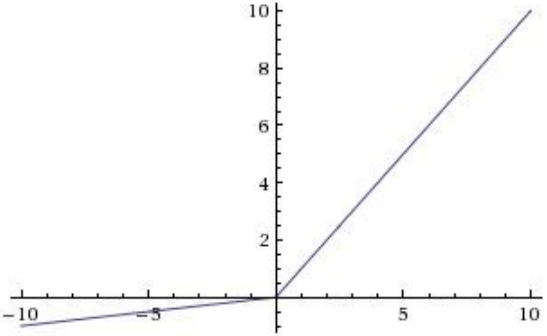
优点
没有饱和区域
计算快速
收敛速度快
不会失活
(5)Parametric Rectifier (PReLU)
f(x) = max(ax, x)
(6)Exponential Linear Units (ELU)
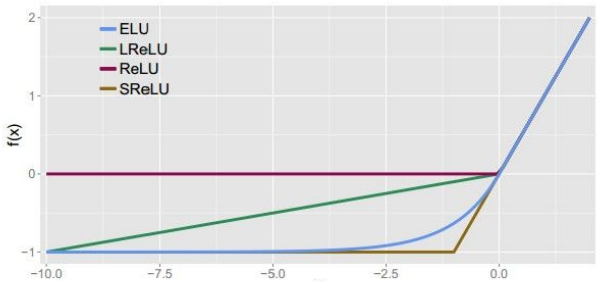
优点
具有ReLU函数的所有优点
不会失活
输出近似零均值
缺点
需要指数计算
(7)Maxout “Neuron”
计算方式不同于以往
优点
没有ReLU的缺点,仍然是分段线性,但不会饱和,不会失活。
缺点
参数/神经元的数量翻倍
实际应用建议:
— 使用ReLU,但是要注意学习率
— 尝试使用Leaky ReLU / Maxout / ELU
— 尝试使用双曲正切(tanh),但不一定会有好的效果
— 不要使用Sigmoid
2.数据预处理
常用的预处理有:均值减除、归一化、PCA、白化(whitening),处理后效果如下图所示:
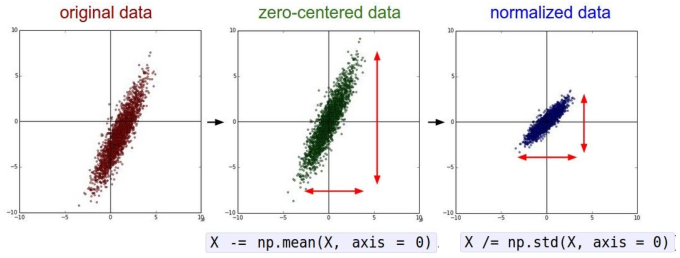
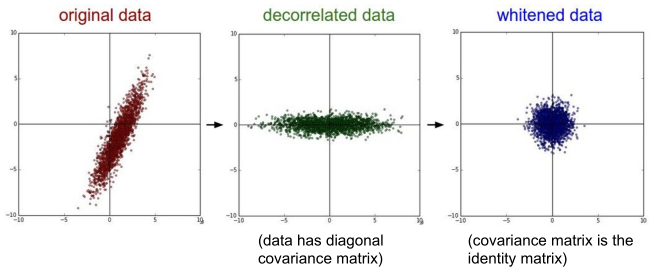
实际应用建议:
对于图像来说,只进行中心化处理就可以
— 减去均值图像,例如AlexNet
均值图像为[H,W,C]的数组
— 减去每个通道的均值,例如VGGNet
均值在每个通道上对应一个数值,共三个
一般不会做标准化,而是使用PCA或者白化处理。
3.权值初始化
Q:如果所有权值初始化为零会怎样?
A:所有权值初始化为零,那么所用神经元的前向-反向传播计算全部一样,所以不可用。
那么考虑用很小的随机数来进行权值初始化。一般是使用从均值为零,标准差很小的高斯函数中随机选取。
这种初始化方法是可行的,但是随着网络层数的增加,这种简单的初始化方法会导致激活函数非均匀分布。
通过一个程序来考察激活函数统计情况,10层神经网络,每层500个神经元,使用不同初始化方法和激活函数。
(1)初始化W = np.random.randn(fan_in, fan_out) * 0.01
激活函数tanh
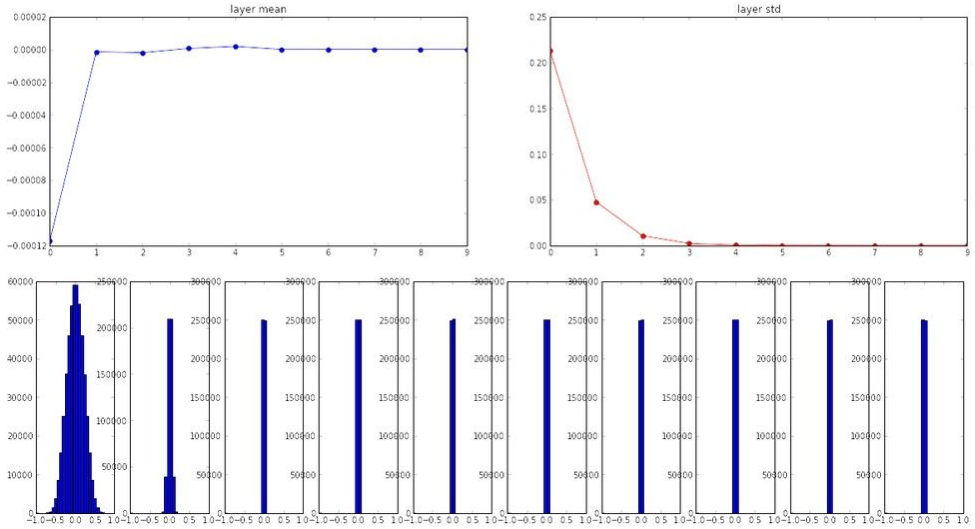
(2)初始化W = np.random.randn(fan_in, fan_out) * 1.0
激活函数tanh
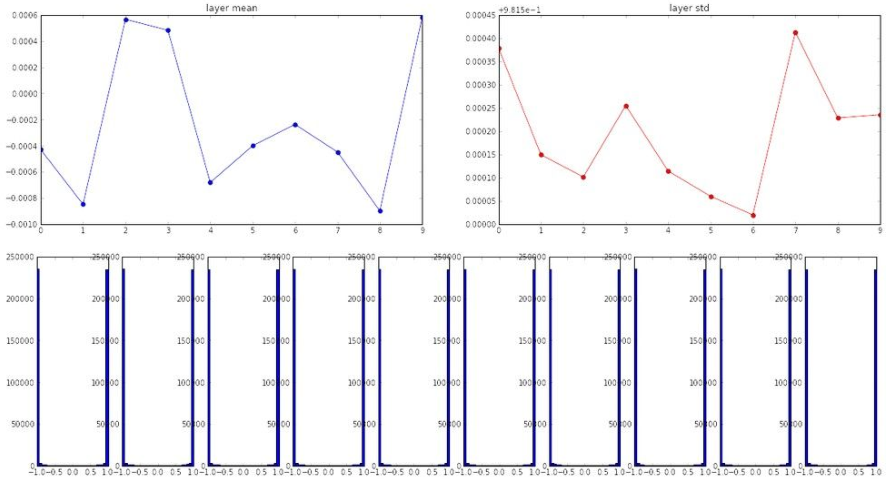
(3)初始化Xavier W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)
激活函数tanh
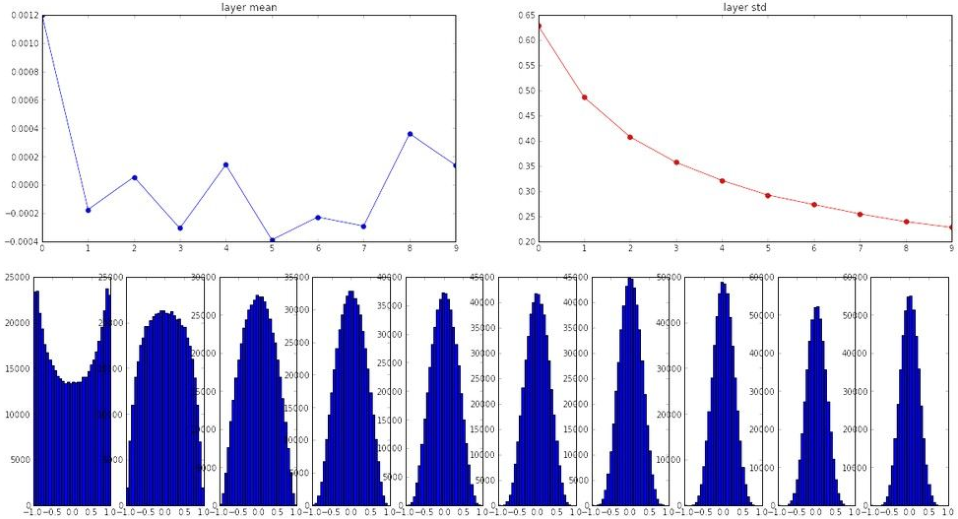
(4)初始化Xavier W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)
激活函数ReLU
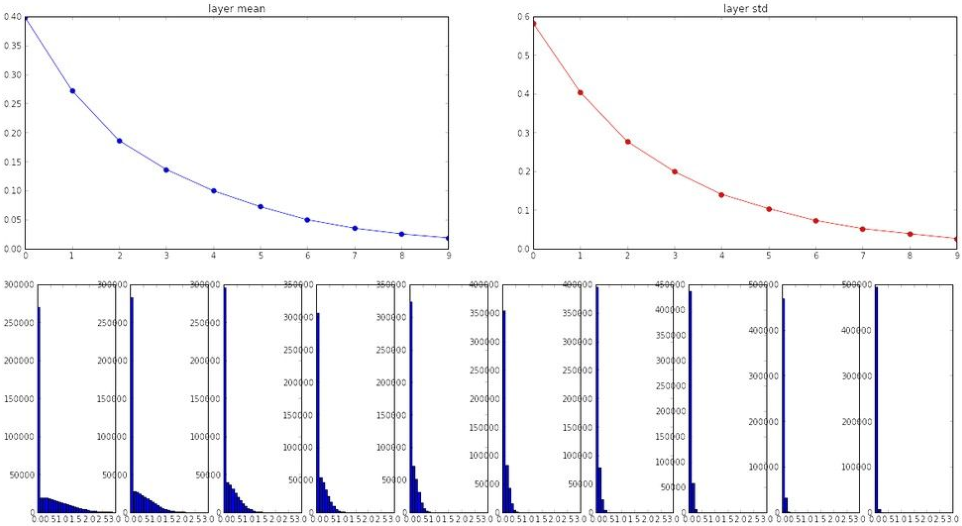
(5)初始化W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2)
激活函数ReLU
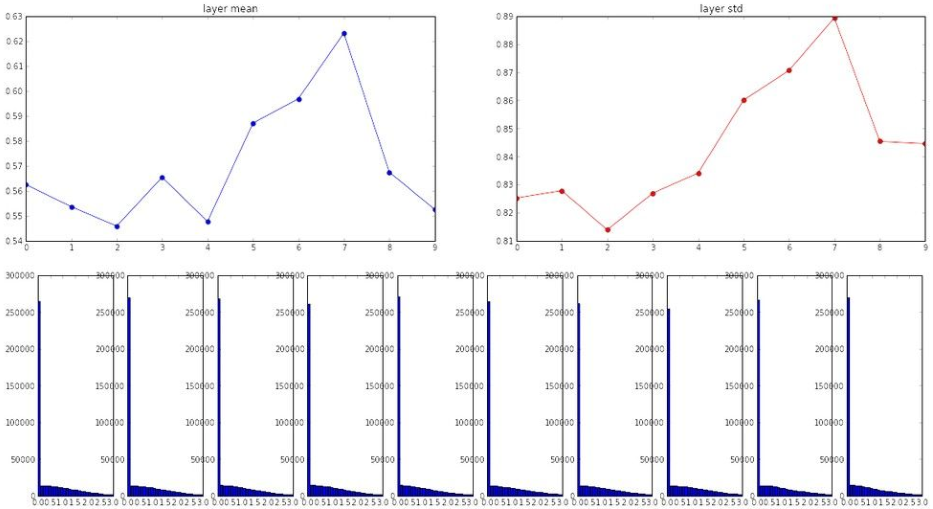
与Xavier对比
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2)
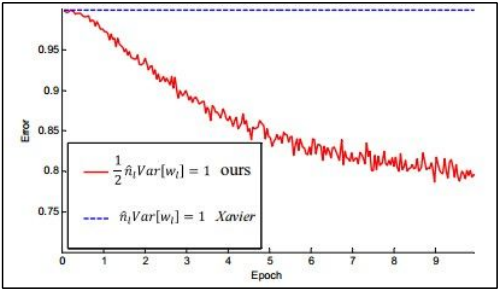
研究初始化问题的相关论文:
Understanding the difficulty of training deep feedforward neural networks
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Random walk initialization for training very deep feedforward networks
Delving deep into rectifiers: Surpassing human-level performance on ImageNet Classification
Data-dependent Initializations of Convolutional Neural Networks
All you need is a good init
…
4.Batch Normalization
“you want unit gaussian activations? just make them so.”
对于某些层的一个批次的激活函数值,可以通过下面计算使得每个维度都符合单元高斯分布:
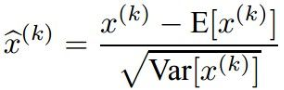
i)计算每个维度上的均值和方差
ii)归一化
一般是置于全连接层或卷积层之后,非线性激活函数之前。
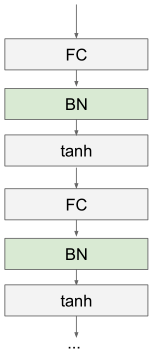
Normalize可以调整网络的输出范围
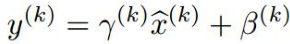
其中γ和β是可训练的,可以恢复到恒等映射。
处理步骤:

优点
— 提升梯度
— 可以允许较大的学习率
— 减轻对初始化的依赖
— 具有正则化的效果,可以不再使用dropout
注意
在测试阶段BatchNorm层与训练阶段不一致
均值和标准差的计算并不基于该批次中的数据,而是使用训练阶段的均值和标准差的平均值。
5.训练流程
(1)数据预处理
(2)确定网络架构
注:可以通过两次检查损失函数来判断架构是否正确。
a)不使用正则项,loss≈log(#classes)
b)调高正则项系数,loss应该会增大
现在可以开始训练。
先确保模型在小部分的训练数据上可以过拟合。
i)选取少量训练数据
ii)不使用正则项
iii)使用简单的SGD优化方法
最终loss极小,准确率为1。
一般可以选择较小的正则项系数,并选择可以让loss变小的学习率。
如果loss不变小,则可能是因为学习率太小。
学习率也不能太大,否则loss会变成NaN。
一般的学习率的合理范围是[1e-3,…,1e-5]
6.超参数优化
(1)交叉验证策略(Cross-validation strategy)
可以采用从粗略到精细的交叉验证策略。
i)只运行几个epoch,得到对超参数的粗略认识
ii)运行更长时间,更加精细的搜索
…可重复进行该过程
如果损失大于原损失三倍以上,终止训练。
随机搜索 vs. 网格搜索 (Random Search vs. Grid Search)
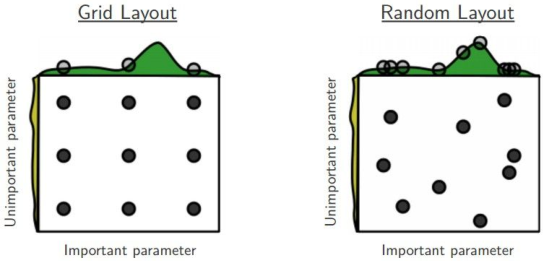
一般所需设置的超参数:
— 网络架构
— 学习率,以及其衰减进度和更新方式
— 正则化方法,以及其强度,例如L2的系数,Dropout的丢弃率
损失曲线可视化
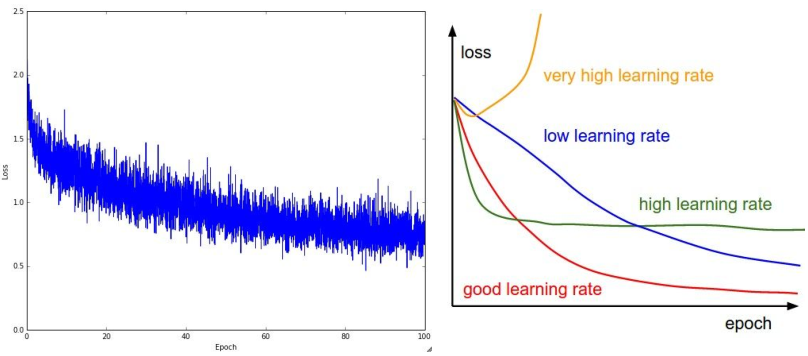
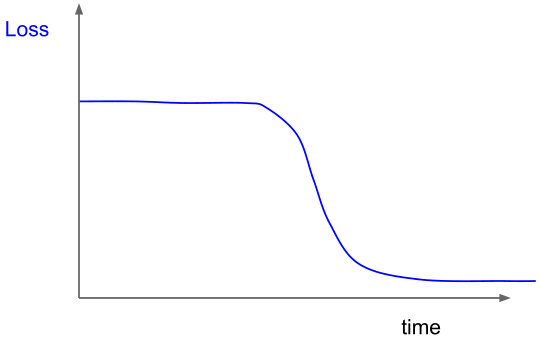
主要怀疑是由初始化差造成的损失曲线的表现
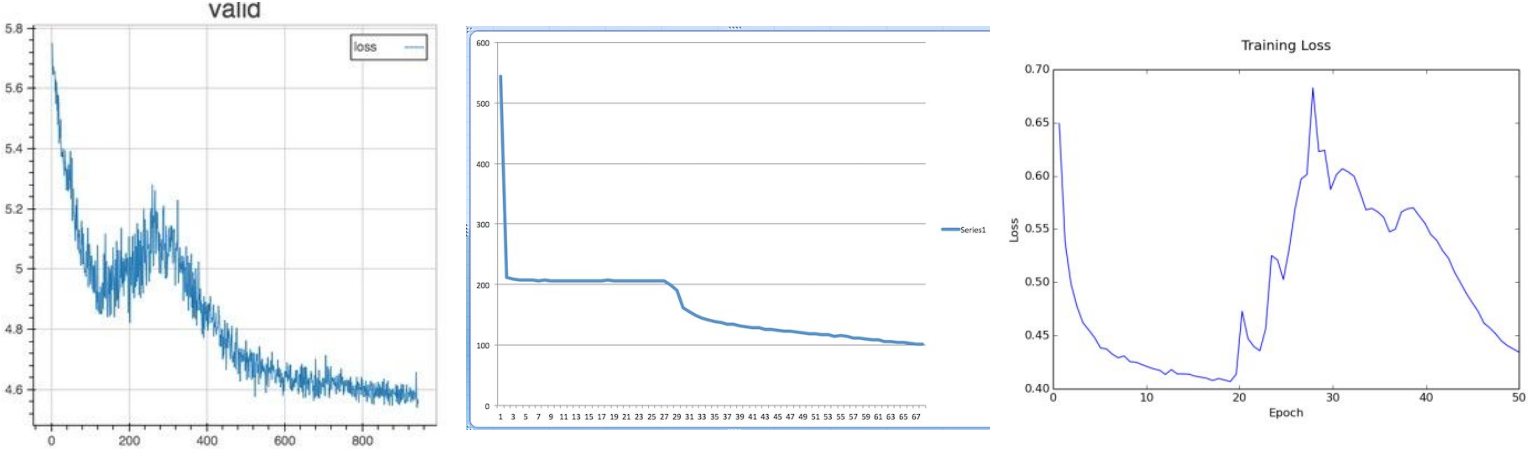
各种不同的损失函数变化趋势 lossfunctions.tumblr.com
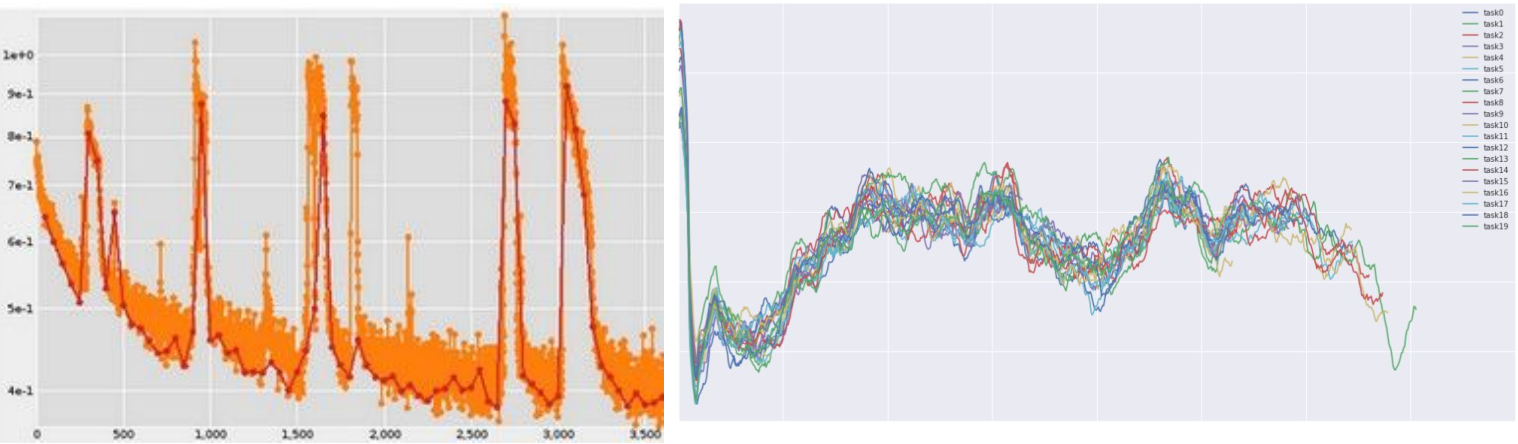
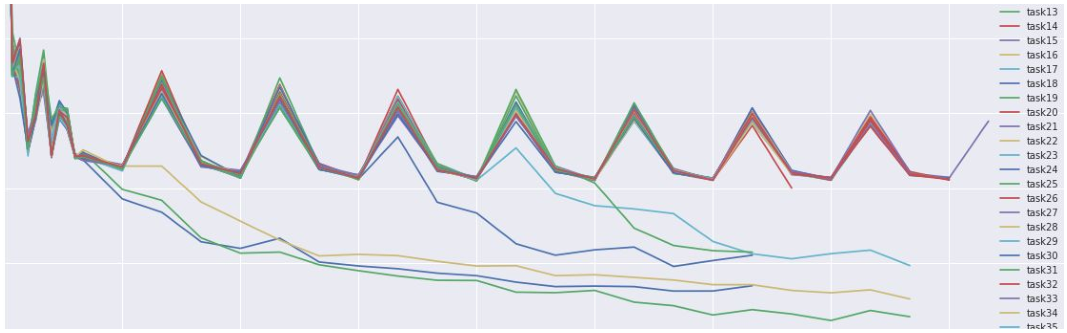
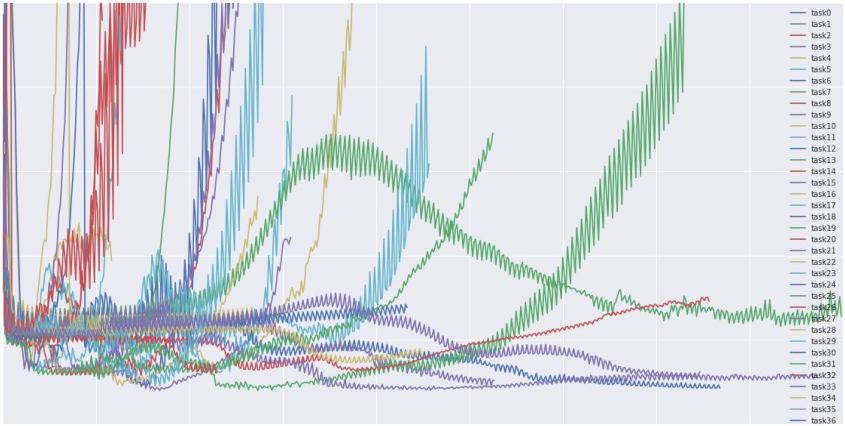
准确率趋势可视化
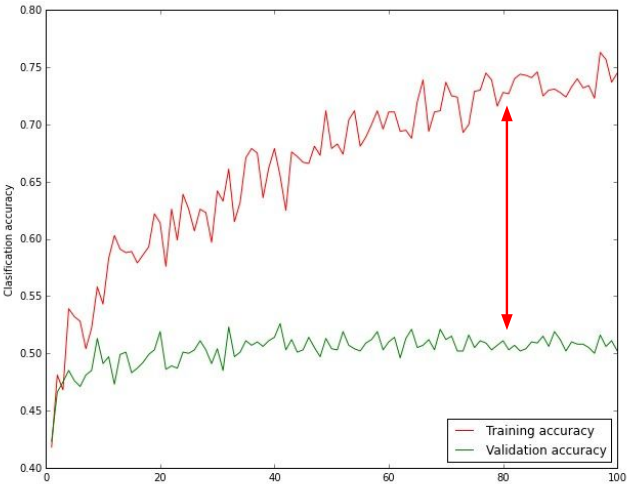
如果训练集上的准确率和测试集上的准确率相差太大,则说明是过拟合(overfitting),可以增加正则化强度;如果没有差距,则可能需要增加模型容量。
追踪权值更新值与权值大小的比例 update_scale / param_scale,一般来说0.001左右为好。
概要
— 激活函数(使用ReLU)
— 数据预处理(对于图像进行减除均值处理即可)
— 权值初始化(使用Xavier)
— Batch Normalization(使用)
— 训练流程
— 超参数优化(在合适的对数空间随机选取)















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









