






点击标题下「蓝色微信名」可快速关注
大模型的时代,经常可能听到GPU这个名词,什么是GPU?技术社群的这篇文章《一文读懂 GPU 技术》给我们进行了一些讲解,可以学习了解。
众所周知,人工智能的迅猛发展对计算能力提出了前所未有的挑战。传统的冯·诺依曼架构CPU,由于其串行执行方式和内存访问瓶颈,在处理复杂的深度学习模型时逐渐力不从心。摩尔定律的放缓进一步加剧了这一问题,使得CPU难以满足人工智能应用对算力的指数级增长需求。
为了应对这一挑战,GPU(图形处理器)凭借其高度并行的架构和强大的浮点运算能力,成为了加速深度学习的首选。GPU的并行计算特性与神经网络的并行计算本质高度契合,使其在处理大规模矩阵运算和神经网络模型时表现出卓越的性能。随着深度学习算法的不断发展,GPU在图像识别、自然语言处理、计算机视觉等领域得到了广泛应用,为人工智能的发展提供了强有力的算力支撑。
1. 什么是GPU?
GPU(图形处理单元)是一种专用的高度并行化处理器,最初被设计用于快速高效地渲染图形图像和视频内容。与传统的通用CPU不同,GPU采用了大规模并行的硬件架构,能够同时执行成千上万个线程,从而极大地提升了图形渲染和数据并行计算的能力。
通常,GPU作为计算机系统的关键硬件部件之一,可以嵌入式集成于芯片组(SoC)中,也可以作为独立的独立显卡单元与主板相连。无论哪种方式,GPU都能为系统提供强大的图形渲染和视觉计算支持。具备GPU加速功能的电子设备,不仅能够流畅地渲染3D图形、动画和视频内容,还可广泛应用于游戏、专业绘图、视频编辑等视觉密集型场景。
最初,GPU的功能相对单一,主要着眼于图形图像的渲染工作。但随着时间推移,GPU硬件和软件生态不断发展,其可编程性和灵活性越来越强,应用领域也在不断扩展。如今,除了图形渲染之外,GPU还被广泛用于创意内容制作、视频转码、科学模拟、密码学运算等多个领域。
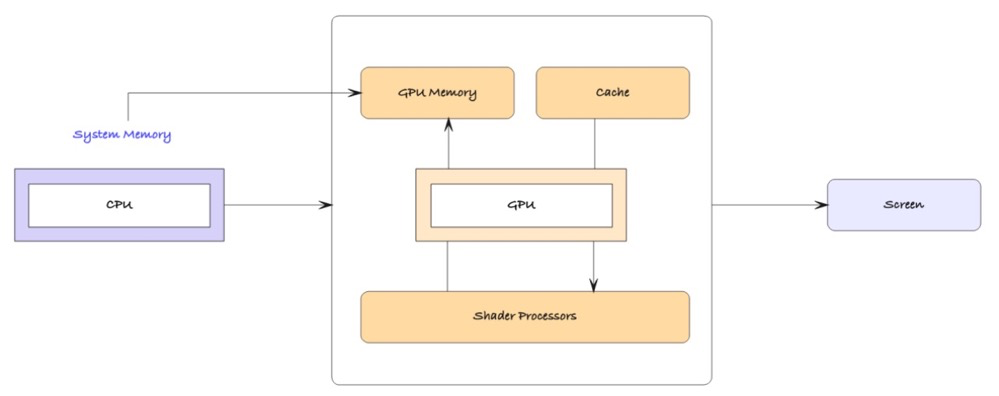
特别值得一提的是,GPU在人工智能和高性能计算(HPC)领域发挥着越来越重要的作用。深度神经网络模型训练过程中的大规模矩阵和向量运算,恰恰契合了GPU的并行计算架构,GPU能够比CPU提供数倍的加速效果。此外,GPU还被广泛用于科学计算、流体动力学模拟等HPC应用,成为了廉价但极具并行运算能力的加速硬件。
2. 为什么GPU适合图像处理?
GPU(图形处理器)之所以在图像处理领域独占鳌头,得益于其高度并行的架构设计。GPU内部集成了大量的小型处理单元,能够同时处理图像中的多个像素点,极大地加速了图像处理过程。此外,GPU还具备共享内存、高带宽内存、可编程性等特性,使其在处理图形密集型任务时表现出卓越的性能。这些优势使得GPU成为了图像处理领域的“加速器”,大幅提升了图像处理的速度和效率。具体可参考如下:
(1) 共享内存
现代GPU通常配备共享内存,这种内存架构比CPU的缓存更快、更高效,尤其在处理具有高度局部性的算法时,GPU的共享内存能显著提升处理效率。共享内存使得多个处理单元可以快速访问和共享数据,减少了内存瓶颈,从而提高了整体的计算性能。
(2) 负载管理
与CPU相比,GPU在处理负载管理方面表现更加灵活。GPU能够通过调整寄存器数量来优化资源分配,降低子系统的负载。这种灵活性使得GPU在处理复杂计算任务时,能够有效地管理和分配资源,从而保持高效的运行状态。
(3) 高速计算
GPU的并行处理能力使其在计算速度上远远超过传统的CPU。GPU拥有更高的内存带宽和处理能力,这使得它在处理大规模数据时表现出色。具体来说,GPU的计算速度可以比CPU快近100倍,尤其是在处理涉及大量浮点运算或矩阵操作的任务时,这种速度优势尤为明显。
(4) 嵌入式应用中的灵活性
在嵌入式应用领域,GPU也展现出了巨大的优势。虽然ASIC(专用集成电路)和FPGA(现场可编程门阵列)在某些特定任务中表现出色,但GPU提供了更大的灵活性,使其成为嵌入式应用中的理想选择。与ASIC和FPGA不同,GPU可以通过编程轻松调整以适应不同的任务需求,减少了开发时间和成本。
(5) 多任务并行执行
GPU的硬件架构允许不同的模块同时执行多种任务,这使得GPU在并行执行方面非常出色。例如,在神经网络的训练中,GPU的张量内核可以同时处理不同的计算任务,如矩阵乘法和卷积运算。这种多任务并行执行能力使得GPU在深度学习和AI应用中成为不可或缺的计算工具。
3. GPU是如何构建及工作的?
GPU在有效处理多个复杂计算任务方面的主要优势,源自其卓越的“大规模并行架构”设计。
GPU由数百甚至数千个小型处理内核组成,这些内核通常被称为流处理器(Stream Processors)或着色器内核(Shader Cores)。每个处理内核都配备了自己的寄存器和共享内存块,用于存储数据和执行程序指令。这种设计使得GPU能够以极高的效率同时处理大量并行任务。
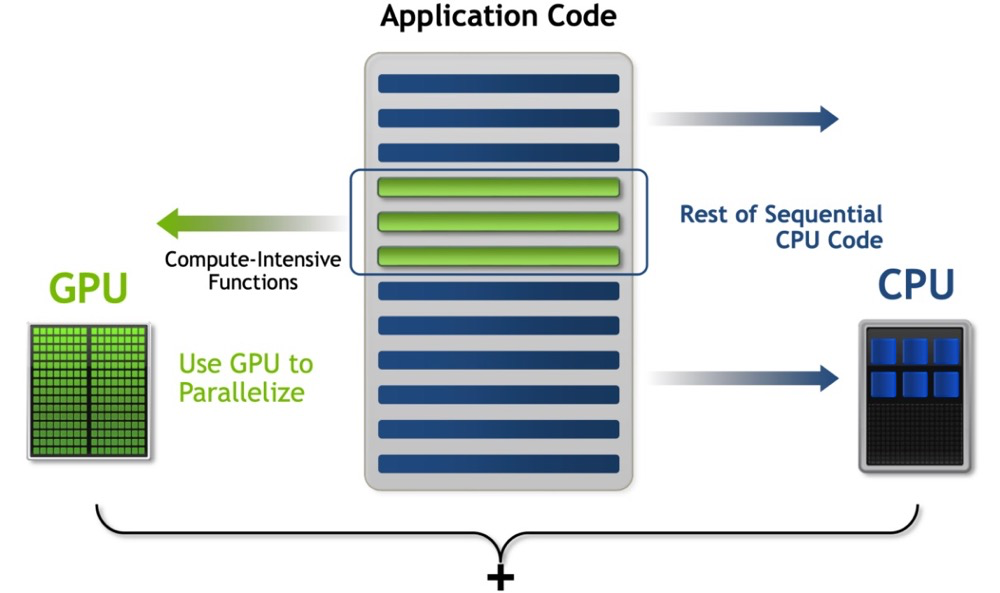
相比传统的中央处理器(CPU),GPU的并行处理能力使其在执行密集计算任务时表现得尤为出色。CPU通常依赖于少数几个强大的内核,而GPU则通过大量的小型内核同时处理任务,将复杂的计算工作分解为许多简单的操作进行并行计算,从而极大地提高了处理速度。这种架构设计使得GPU在图形渲染、科学计算、人工智能训练等需要大规模数据处理的领域,表现出色。
此外,GPU的寄存器和共享内存块的设计,使得数据可以在多个内核之间高效传递和共享,减少了因数据传输造成的延迟,从而进一步提升了计算性能。正是这些独特的架构优势,使得GPU成为现代计算领域不可或缺的核心组件,为各种计算密集型任务提供了卓越的解决方案。
GPU的核心组成部分如下:
(1) 算术逻辑单元(ALUs)
算术逻辑单元是GPU的基本构建模块,负责执行各种算术和逻辑运算。ALUs通常被安排成组,每个组可以同时执行成千上万次操作。这种并行计算能力使得GPU在处理图形密集型任务时表现得尤为强大,如复杂的图像渲染和科学计算。
(2) 视频内存(VRAM)
视频内存是专门用于GPU的存储单元,用来存储显示图形所需的数据。VRAM允许GPU快速访问纹理、帧缓冲区以及其他必要的图形数据,从而加快图像渲染速度并降低延迟。充足的VRAM容量对图形处理的效率至关重要,特别是在处理高分辨率图像和实时3D渲染时,VRAM可以显著提升整体性能。
(3) 纹理映射单元(TMUs)与渲染输出单元(ROPs)
纹理映射单元负责纹理映射和滤波操作,将纹理数据准确地应用到3D模型上。渲染输出单元则处理最终的图像生成工作,将视觉数据转换为像素,并管理抗锯齿、深度测试等任务。这些单元的协同工作,确保了图像的质量和渲染的精度,使得复杂场景的实时渲染成为可能。
4. 常见的GPU内核类型对比解析
通常而言,现代GPU为了适应日益复杂的计算需求,配备了多种类型的内核,以加速不同类型的任务,从而实现业务场景的落地。
(1) RT Cores
RT Cores是专门为光线追踪(Ray Tracing)技术而设计的专用内核。光线追踪是一种高级渲染技术,通过模拟光线在虚拟环境中的传播路径,以生成具有物理准确性的图像效果。这种技术能够精确地再现光线与物体之间的相互作用,如反射、折射、阴影、漫射等,使得图像更加逼真。
RT Cores的主要应用场景在于高端图形渲染,特别是在电影、游戏和虚拟现实(VR)等需要高度真实感的领域。传统的图形渲染技术(如光栅化)虽然速度快,但在处理复杂光影效果时往往力不从心。RT Cores的引入使得实时光线追踪成为可能,从而提升了视觉体验的质量。例如,在游戏中,光线追踪能够生成更加真实的动态反射和阴影效果,使得场景更加生动和沉浸。
RT Cores通过硬件加速实现了光线追踪的高效处理,这使得以往需要数小时甚至数天渲染的电影级效果,现在可以在实时场景中生成。随着硬件技术的进步和RT Cores的普及,光线追踪技术正逐渐成为主流,推动了视觉内容创作的革命。
(2) Tensor Cores
Tensor Cores是为深度学习和AI工作负载设计的专用内核。其主要功能是加速张量运算,尤其是在深度神经网络的训练和推理过程中。张量是数学中的多维数组,深度学习模型的大部分计算,如矩阵乘法、卷积操作等,都可以归结为张量运算。Tensor Cores能够大幅度提升这些运算的效率,使得复杂的神经网络训练时间显著缩短。
Tensor Cores的应用广泛覆盖了AI和机器学习的多个领域,如图像识别、自然语言处理、语音识别、自动驾驶和科学研究等。在这些领域,深度学习模型通常需要处理大量数据和复杂计算,Tensor Cores提供了专用硬件加速,大大提高了模型训练和推理的速度。例如,在自动驾驶中,Tensor Cores加速了图像处理和物体识别,从而提高了系统的实时响应能力和精确性。
与通用的CUDA Cores相比,Tensor Cores针对特定的张量计算进行了优化,能够以更低的功耗完成更高效的计算。这使得AI应用程序可以更快地从大量数据中提取有用信息,支持更复杂的模型架构和更快的迭代开发。
(3) CUDA Cores
CUDA Cores是GPU中最基本的处理单元,负责执行各种并行计算任务。CUDA(Compute Unified Device Architecture)是由NVIDIA开发的并行计算平台和编程模型,允许开发者利用GPU的计算能力来加速广泛的应用。每个CUDA Core可以看作是一个独立的计算引擎,能够执行基本的算术运算、逻辑操作、数据移动等。
通常而言,CUDA Cores的应用范围非常广泛,包括但不限于以下领域:
科学计算:例如分子动力学模拟、天气预报、基因序列分析等,这些任务通常涉及大量浮点运算和数据处理。
图形渲染:CUDA Cores负责处理3D图形中的基本渲染任务,如顶点处理、像素着色等。
物理仿真:在计算机图形学和工程模拟中,CUDA Cores用于模拟物体的物理特性,如流体动力学、刚体碰撞等。
CUDA Cores的并行处理能力使其在执行大规模并行任务时表现尤为出色。随着GPU架构的发展,CUDA Cores的数量不断增加,这直接提升了GPU的整体性能。相比于传统的CPU,GPU中的CUDA Cores数量众多,因此能够同时处理成千上万的线程,从而大幅缩短计算时间,提升应用的效率和响应速度。
在现代GPU中,这三种类型的内核通常是协同工作的。例如,在渲染一个包含复杂光照效果的场景时,RT核心负责计算光线与场景的交点,张量核心负责加速神经网络进行实时风格转换,而CUDA核心则负责处理其他通用计算任务。这种协同工作使得GPU能够高效地处理各种复杂的图形和计算任务。
5. 如何理解GPU内核类型在整个GPU架构体系中的作用?
在GPU架构体系中,内核类型是决定其计算能力和并行处理性能的关键因素。CUDA核心、张量内核、向量内核和纹理内核等等多种内核类型共同协作,使GPU能够处理从图形渲染到深度学习、科学模拟等各种高性能计算任务。每种内核类型的设计都针对特定的计算场景进行优化,赋予GPU强大的并行计算能力,极大地提升了任务执行效率。
作为“灵魂因素”,CUDA的核心概念在于其“并行处理”设计理念, 通过将复杂的计算任务拆分为成千上万、甚至数百万个较小的称为“线程”的计算单元,每个线程可以在GPU的不同核心上同时执行。这种架构特别适用于需要高并发数据处理的应用场景,如图像处理、物理模拟、机器学习训练以及高性能科学计算。
CUDA Core作为 CUDA平台的基础组成部分,也是GPU内负责执行计算任务的并行处理单元。GPU中的 CUDA Core数量直接决定了它能够同时处理多少任务,核心数量越多,设备的并行计算能力和处理性能就越强。这使得CUDA成为推动高性能计算的重要工具,能够在深度学习、科学模拟和工程计算等领域发挥关键作用。
在GPU架构的背景下,CUDA Core虽然与CPU中的核心在名称上相似,但它们的设计目标和功能存在根本性的差异。CPU核心通常专为顺序处理任务而设计,每次可以高效地处理几个软件线程。然而,CUDA Core是GPU中高度并行架构的一部分,旨在同时处理成千上万个线程。这使得它们能够以极高的并发度执行分解为细小任务的工作负载,大幅提升了计算速度和效率。
此外,CUDA平台提供了高度灵活的编程接口,允许开发者通过自定义线程管理和内存访问模式来进一步优化GPU的计算能力。借助这一平台,开发者能够充分发挥 GPU的并行计算优势,加速各种复杂的计算任务,从而极大提高系统的整体性能。
6. GPU在AI中的应用
GPU在并行处理方面具有无与伦比的优势,尤其在训练人工智能模型时,往往是首选计算硬件。
人工智能训练通常涉及对大量数据样本进行相同或相似的操作,这种操作模式非常适合并行处理架构。在实际应用中,随着数据集的规模不断扩大,要求处理能力必须不断增强,以保证任务的高效执行。在这种背景下,GPU凭借其大规模并行处理能力,成为了企业和研究机构在人工智能领域的首选设备。
通常而言,GPU能够在越来越多的企业中发挥自身价值,主要体现在以下几点,具体可参考:
(1) 神经网络训练
神经网络训练过程中,需要处理大量并行输入数据。GPU的架构使其能够同时处理数千甚至数百万个数据点,从而显著加速深度学习模型的训练过程。例如,在图像识别或自然语言处理等任务中,神经网络模型需要在大量数据样本上进行反复训练,以提升模型的准确性和泛化能力。GPU的并行处理能力使得这一过程能够在更短的时间内完成,从而提高了开发效率。
(2) 加速人工智能和深度学习操作
人工智能和深度学习应用中,大量的矩阵运算和复杂计算是常态。GPU专门为这种计算密集型任务进行了优化,特别是通过其Tensor Cores和CUDA Cores,GPU能够加速矩阵乘法、卷积运算等关键操作,使得模型训练和推理速度大大提升。这种加速效果在处理海量数据时尤为明显。
(3) 传统的人工智能推理和训练算法
除了深度学习,GPU在传统人工智能算法中也发挥着重要作用。无论是随机森林、支持向量机,还是聚类分析,GPU都能够提供强大的并行计算能力,加速这些算法的执行。此外,GPU的高内存带宽使得它能够快速访问和处理大量数据,进一步提升了算法的执行效率。
起初,GPU主要用于图形渲染,但随着并行计算需求的增长,GPU逐渐成为高性能计算(HPC)和人工智能领域的核心组件。如今,GPU已经深入企业级应用,特别是在数据中心和云计算环境中,其强大的计算能力使其成为运行大规模并行任务的理想选择。
参考:
https://acecloud.ai/resources/blog/gpu-vs-cpu-for-image-processing/#Why_is_a_GPU_suitable_for_image_processing
https://www.techtarget.com/searchvirtualdesktop/definition/GPU-graphics-processing-unit
https://mp.weixin.qq.com/s/Iay9V9cCGxCEbAaqBTTW1w
如果您认为这篇文章有些帮助,还请不吝点下文章末尾的"点赞"和"在看",或者直接转发朋友圈,

近期更新的文章:
热文鉴赏:
《推荐一篇Oracle RAC Cache Fusion的经典论文》
文章分类和索引:

















 4495
4495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









