







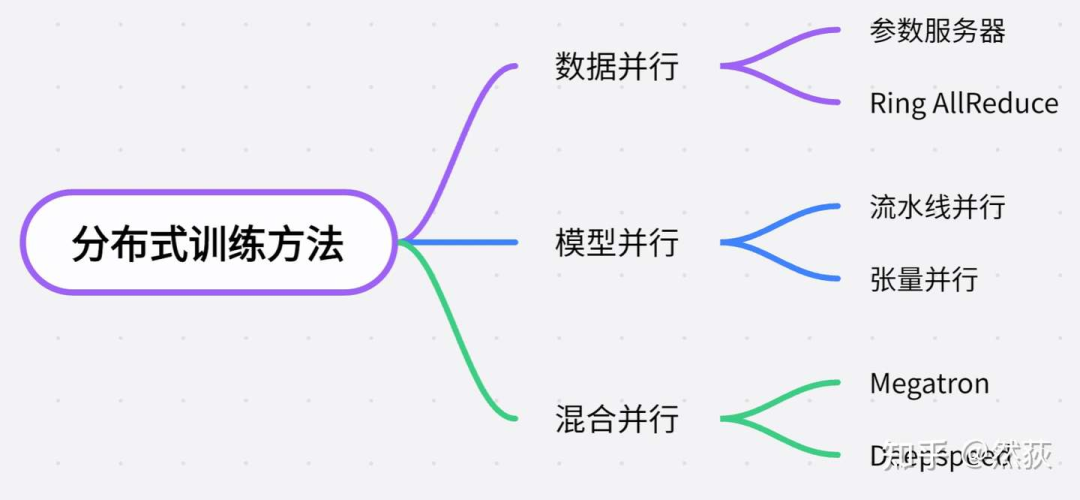
1. 背景介绍
如果你拿到了两台8卡A100的机器(做梦),你的导师让你学习部署并且训练不同尺寸的大模型,并且写一个说明文档。你意识到,你最需要学习的就是关于分布式训练的知识,因为你可是第一次接触这么多卡,但你并不想深入地死磕那些看起来就头大的底层原理,你只想要不求甚解地理解分布式的基本运行逻辑和具体的实现方法。那么,我来帮你梳理关于大模型的分布式训练需要了解的知识。
1.1 分布式定义
分布式就是把模型或者数据分散分布到不同的GPU去。为什么要分散到不同的GPU,当然是因为一个GPU的显存太小了(不管从为了训练加速还是模型太大塞不进去这两个角度来看,本质就是单个GPU显存不够)。为什么GPU显存这么小,是因为GPU对带宽的要求很高,能达到这样高带宽的内存都很贵,也就是说从成本的角度上导致单个GPU显存有限。
1.2 分布式方法分类
从需要加载的模型大小来分类,一般可以这样对分布式的方法进行分类。
-
单卡能够容纳训练的小模型,分布式就是为了训练加速,一般使用的是数据并行的方法,也就是每一块GPU复制一份模型,然后将不同的数据放到不同的GPU训练。
-
模型变得越来越大,单卡都无法支持一个模型训练的时候,就会使用模型并行的方法,模型并行又分为流水线并行(Pipeline Parallelism)和张量并行(Tensor Parallelism),其中流水线并行指的是将模型的每一层拆开分布到不同GPU。当模型大到单层模型都无法部署在单个gpu上的时候,我们就会用到张量并行,将单层模型拆开训练。
-
Deepspeed,则是用了Zero零冗余优化的方法进一步压缩训练时显存的大小,以支持更大规模的模型训练。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
2. 必要知识补充
2.1 模型是怎么训练的
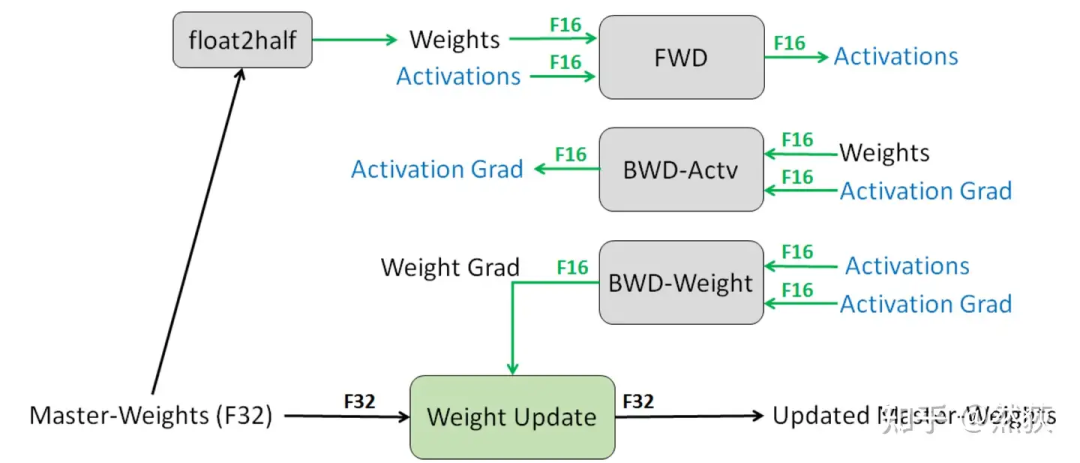 我们想了解模型训练时分布式是如何进行优化的,那么知道模型是如何训练的就非常重要。我们以目前最广泛使用的混合精度训练为例,按照训练运行的逻辑来讲:
我们想了解模型训练时分布式是如何进行优化的,那么知道模型是如何训练的就非常重要。我们以目前最广泛使用的混合精度训练为例,按照训练运行的逻辑来讲:
-
Step1:优化器会先备份一份FP32精度的模型权重,初始化好FP32精度的一阶和二阶动量(用于更新权重)。
-
Step2:开辟一块新的存储空间,将FP32精度的模型权重转换为FP16精度的模型权重(用于前向和计算梯度)。
-
Step3:运行forward和backward,产生的梯度和激活值都用FP16精度存储。
-
Step4:优化器利用FP16的梯度和FP32精度的一阶和二阶动量去更新备份的FP32的模型权重。
-
Step5:重复Step2到Step4训练,直到模型收敛。
我们可以看到训练过程中显存主要被用在四个模块上
-
模型权重本身(FP32+FP16)
-
梯度(FP16)
-
优化器(FP32)
-
激活值(FP16)
具体训练的时候会消耗多少显存怎么计算呢,多大的模型在训练的时候会超出我们的最大显存呢,关于大模型训练时的显存占用分析可以看一看这篇文章“一文讲明白大模型显存占用(只考虑单卡)”,讲得非常详细(自卖自夸),有助于后续我们理解怎么优化显存占用。
https://zhuanlan.zhihu.com/p/713256008
2.2 GPU是怎么通讯的
我们常常听说单机8卡、多机多卡、多节点,这里的“单机”和“节点”也就是指的是单个服务器,8卡自然指的是8张显卡。在同一个服务器内的8张GPU共享同一个主机系统的资源(如CPU资源、系统内存等),同一节点内的不同GPU之间通过PCIe总线或者NVLink(仅限NVIDIA显卡)进行通讯,不同节点之间的GPU一般是通过InfiniBand网卡通讯(NVIDIA的DGX系统就是一张GPU卡配一个InfiniBand网卡),下图可以看出,多节点之间的通讯带宽和单节点多GPU之间的通讯带宽是可以达到差不多速度的。你问为什么节点之间不用NVLink,因为 NVLink设计用于非常短距离的通信,通常在同一服务器机箱内 ,不方便扩展。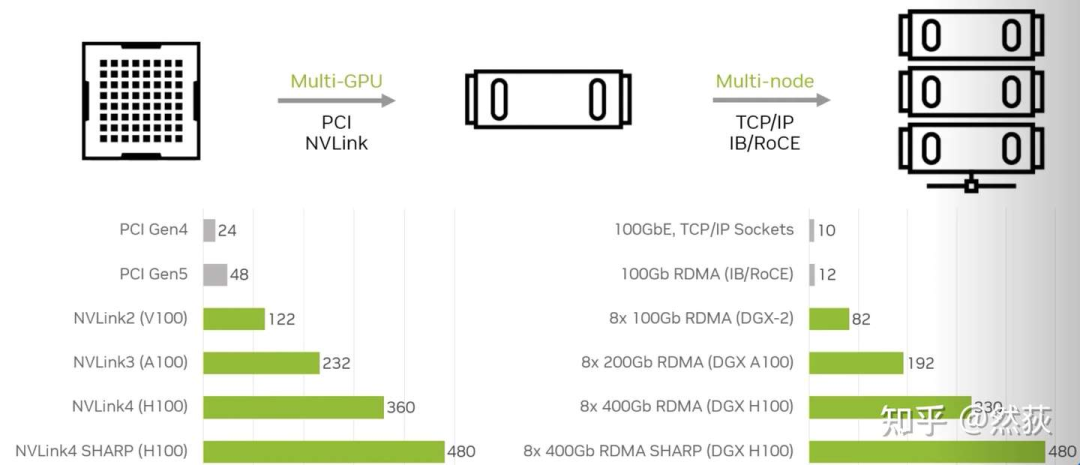 除了上面介绍的硬件,还有软件部分,就是大名鼎鼎的NCCL 英伟达集合通信库,专用于多个 GPU 乃至多个节点间通信的实现。AllReduce,Broadcast,Reduce,AllGather,ReduceScatter就是NCCL主要实现的通信原语。
除了上面介绍的硬件,还有软件部分,就是大名鼎鼎的NCCL 英伟达集合通信库,专用于多个 GPU 乃至多个节点间通信的实现。AllReduce,Broadcast,Reduce,AllGather,ReduceScatter就是NCCL主要实现的通信原语。
其实NCCL就是提供了一个接口,我们也不需要了解底层如何实现的,只需调用接口,就可以实现GPU间的通信。
2.2.1 Broadcast(广播)
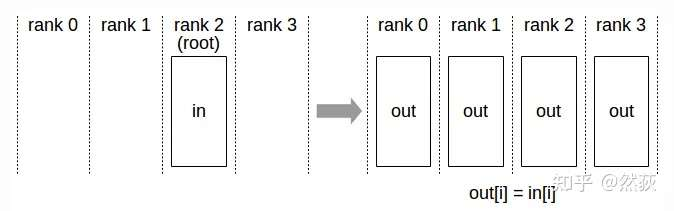 将一个GPU上的数据同时发送到所有其他GPU,这种操作方式就叫做广播(broadcast)。
将一个GPU上的数据同时发送到所有其他GPU,这种操作方式就叫做广播(broadcast)。
2.2.2 Scatter(散射)
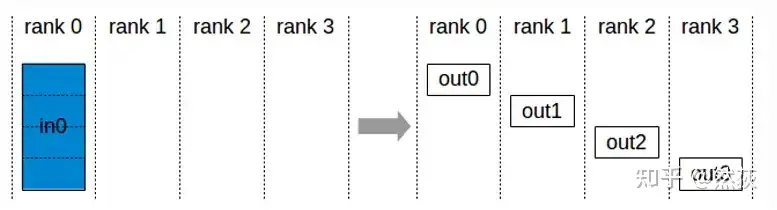 把一个GPU上的数据切分为多块,按照顺序向其他GPU发送数据块,就叫做散射。
把一个GPU上的数据切分为多块,按照顺序向其他GPU发送数据块,就叫做散射。
2.2.3 Reduce(规约)
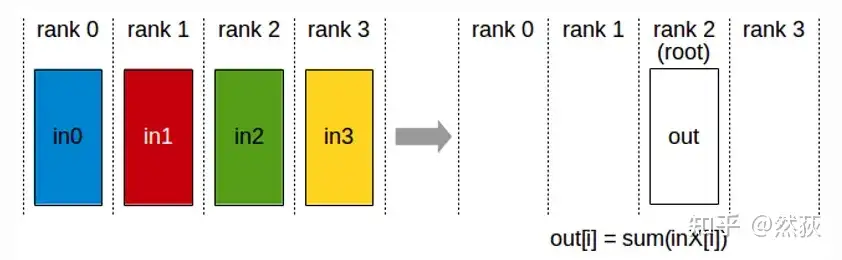 reduce在这里的作用是求和,即将多个GPU的数据发送到指定的GPU然后求和。
reduce在这里的作用是求和,即将多个GPU的数据发送到指定的GPU然后求和。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









