







中文标题:基于内部特征融合的自监督单目深度估计
创新点
- 参照HR-Net在网络上下采样的过程中充分利用语义信息。
- 设计了一个注意力模块处理跳接。
- 提出了一个扩展的评估策略,其中方法可以使用基准数据中的困难的情况进行进一步测试,以一种自我建立的方式形成。
网络结构设计
高分辨率编码器

- 浅层但高分辨率的特征在空间上很精确,相反,深层但低分辨率的特征在空间上并不精确,但是语义信息丰富。
- x r e , s x^e_r,s xre,s代表特征图中第s阶段,第r个子流。第r个子流的分辨率是原分辨率的 1 / 2 r − 1 1/2^{r-1} 1/2r−1。
- 使用HRNet编码器,效果明显强于ResNet.
- DIFFNet强制来自不同阶段的特征映射包含不同的语义信息,但在解码之前使用连接策略融合来自所有中间阶段的输出。

 - HRNet和DiFFNet不同节点间特征可视化图,可知DiFFnet的深层特征更加语义。
- HRNet和DiFFNet不同节点间特征可视化图,可知DiFFnet的深层特征更加语义。
 - HRNet和DIFFNet
- HRNet和DIFFNet
注意力机制深度解码器
- 解码器的整体结构和Mono2类似。将DIFF Encoder的每一自流集合的特征当作与编码器的跳接形成U-net。重点是加入了通道注意力机制帮助特征融合。
- 注意力机制:
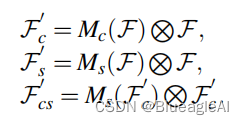 - 在消融实验中,加入空间注意力机制效果不佳,顾舍弃。
蒸馏实验结果

扩展的评估
- 选取了验证集上最难的10张图单独作为测试集进行评估。

参考文献
[1] Zhou H, Greenwood D, Taylor S. Self-supervised monocular depth estimation with internal feature fusion[J]. arXiv preprint arXiv:2110.09482, 2021.
















 6214
6214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











