







Motivation
- 自注意力机制在2D自然图像领域面临3个挑战:
- 视二维图像为一维序列。
- 对于高分辨率图像,二次复杂度消耗太大。
- 只捕捉空间适应性,忽略通道适应性。
Contribution
- 设计了 Large Kernel attention(LKA),包含卷积和自注意力机制的优势。并基于LKA设计了VAN的主干。
Method
Large Kernel Attention
- 注意机制可以看作是一个自适应选择过程,它可以选择判别特征,并根据输入特征自动忽略噪声响应。注意力机制的关键步骤是生成注意力图,表示不同点的重要性。为此,我们应该学习不同点之间的关系。
- 有两种不同的方法构建不同点间的关联。
- self-attention mechanism: 捕捉大范围依赖(long-range dependence).
- large kernel convolution: 使用大核卷积构建关联性并产生注意力图。
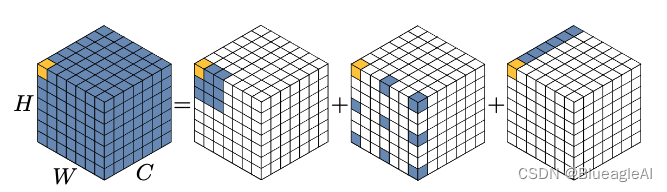
- (参考上图)为了克服两种方法的不足并充分利用自注意力和大核卷积,我们提出解构大核卷积。把大核卷积分成三部分:一个空间局部卷积 Depth-wise convolution, 一个空间大范围卷积 Depth-wise dilation convolution 和一个通道卷积1x1 convolution。
- 具体的,我们可以吧KxK的大核卷积解构成 K d × K d \frac{K}{d} \times \frac{K}{d} dK×dK 步长为d的空洞卷积,一个 ( 2 d − 1 ) × ( 2 d − 1 ) (2d-1) \times (2d-1) (2d−1)×(2d−1) 的深度卷积以及一个 1 × 1 1\times1 1×1 卷积。
- 通过解构可以捕捉大范围的关联并减少计算消耗以及参数量。
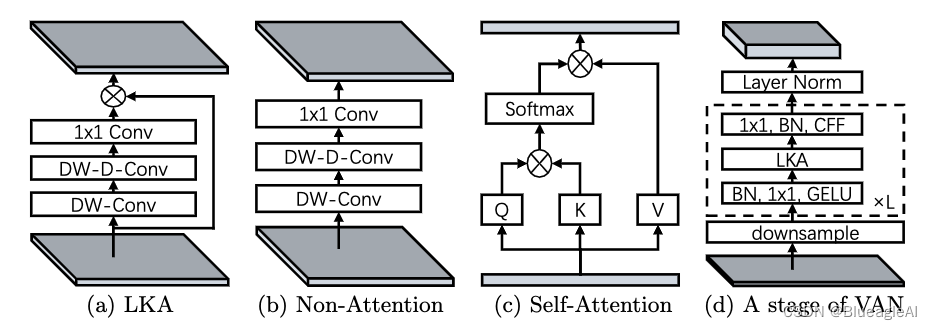
Visual Attention Network(VAN)
- VAN采用了简单的垂直结构,用四个阶段减少输出的空间分辨率,
H
4
×
W
4
,
H
8
×
W
8
,
H
16
×
W
16
,
H
32
×
W
32
\frac{H}{4} \times \frac{W}{4},\frac{H}{8} \times \frac{W}{8},\frac{H}{16} \times \frac{W}{16},\frac{H}{32} \times \frac{W}{32}
4H×4W,8H×8W,16H×16W,32H×32W。

- 默认情况下,我们的 LKA 采用 5 × 5 深度卷积、具有扩张 3 的 7×7 深度卷积和 1×1 卷积来近似 21 × 21 卷积。在这种情况下,VAN 可以有效地实现本地信息和远程连接。我们分别使用7 × 7和3 × 3步幅卷积进行4×和2×下采样。
















 3831
3831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











