







原文:Data-Centric AI vs. Model-Centric AI · Introduction to Data-Centric AI
当你学习关于机器学习相关的课程时,通常是给你一个清洁好的数据,你的任务是利用这个数据集训练出一个最好的模型。所有在机器学习课程教的技巧都是为了这个目标:模型(神经网络,决策树等等),训练技巧(正则化,优化算法,损失函数等等),以及模型/超参数选择(还有模型融合,集成学习)。这种方式我们称为以模型为中心的AI。
当我们从事现实世界的机器学习相关工作时,你的公司或者你的用户并不关心你是如何应用一些聪明的模型技巧在质量很好的数据上去训练出一个预测效果很好的模型。跟课堂上不同,现实世界的应用中数据是没有处理好的。你可以随意改变数据集甚至付费收集更多数据使得你的模型表现更好。现实世界的数据通常质量不好一团糟,所以提高数据质量是构造准确模型的前提。老练的数据科学家懂得比起鼓捣模型,探索和处理好数据集更加值得投入精力,但是这个过程对于大型数据集会有点繁复。提高数据质量可以通过人工去做,凭借人们的直觉或专业知识。
与人工处理数据集的方式相比,以数据为中心的AI是使用AI技术更加系统地诊断和处理现实世界中数据集的问题。以数据为中心的AI的形式有:
1.使用AI算法理解数据,然后用这些信息提高模型表现。Curriculum learning是一种这样的算法。
2.AI算法改变数据以提高模型表现。Confident learning是一种这样的算法,这种算法中机器学习模型在一个去除糟糕样本的过滤好的数据集上训练。
在以上例子中,通过把算法应用在训练好的AI模型的输出上,算法自动评估那个样本是糟糕。
适用于监督型机器学习的方法
以数据为中心的AI的工作流程大概是这样:
1.探索数据,处理基本的数据问题,然后转换数据使得数据可以用于机器学习。
2.在整理好的数据集上训练一个机器学习基线模型。
3.使用这个模型帮助你提升数据的质量。(用本教程的技巧)
4.在提升质量之后的数据集上使用不同的模型技巧提高模型的表现,最后得到最好的模型。
以数据为中心的AI例子
这个领域的方法论包括:
--离群检测以及去除离群点(处理数据集中的异常值)
--错误检测以及纠正(处理数据集中不正确的数据/标签)
--达成共识(从多个来源的注释者的决定中得到一个真正的决定,比如决定一个样本的标签的时候,可以综合多个打标签的注释者的意见)
--数据增量(给数据集增加样本)
--特征工程和特征选择(对数据的表达的处理)
--积极学习active learning(下一个打标签的样本要选择信息量最大的样本)
--知识表示curriculum learning(把样本从最简单到最复杂排序)
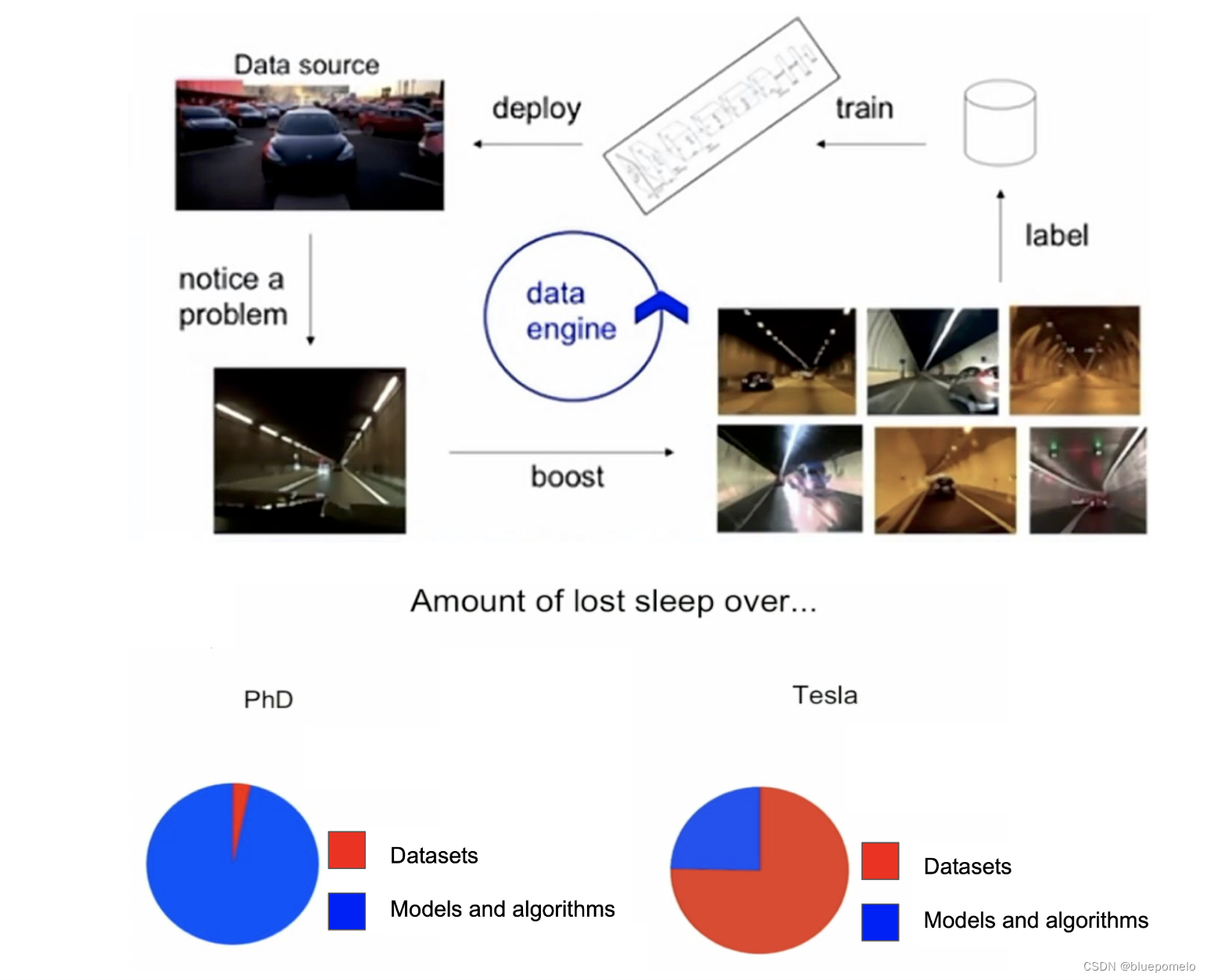
Tesla的自动驾驶系统对比竞争者的更加先进。他们指出数据工程是关键:(图片来源 https://vimeo.com/274274744)
为什么我们需要以数据为中心的AI
质量差的数据每年花费美国3万亿美金。数据质量问题是每个行业都要面对的问题而且花费巨大。随着数据集增大,如果没有算法的帮助,处理大型数据集是不可能的。在大量数据上训练的机器学习模型比如ChatGPT很大程度依赖人力(人类的反馈)去处理低质量的数据的缺陷。但是全靠人力也不能处理所有的数据缺陷。我们需要自动化的方法和系统化的工程法则去确保机器学习模型能够在清洁的数据上训练。机器学习已经深入到我们生活的方方面面,医疗保健、金融、交通等等,系统以一种可靠的方式得到训练是很有必要的。
近年的研究强调了以数据为中心的AI在各种应用中的价值。对于使用含有有噪声标签的数据训练的图片分类,最近有一项基准研究在逐渐增加著名的Cifar-10数据集噪声率的情况下,使用不同的方法训练模型。研究显示对数据集做一些适应性的改变,然后使用简单的模型训练比起使用噪声数据集训练的复杂模型的准确率更高。

本课程所讲的技巧适用于大部分监督刑机器学习模型以及训练模型的方法。
一些参考:(扩展阅读)
[G21] Press, G. Andrew Ng Launches A Campaign For Data-Centric AI. Forbes, 2021.
[B09] Bengio, Y., et al. Curriculum Learning. ICML, 2009.
[NJC21] Northcutt, C., Jiang, L., Chuang, I.L. Confident Learning: Estimating Uncertainty in Dataset Labels. Journal of Artifical Intelligence Research, 2021.
[R16] Redman, T. Bad Data Costs the U.S. $3 Trillion Per Year. Harvard Business Review, 2016.
[S22] Strickland, E. Andrew Ng: Unbiggen AI. IEEE Spectrum, 2022.
[C23] Chiang, T. ChatGPT is a Blurry JPEG of the Web. New Yorker, 2023.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









