







 本文深入剖析了BERT模型,包括输入编码、注意力机制、模型架构和输出结果。BERT使用Transformer的Encoder部分,通过多头自注意力机制捕捉上下文信息。输入经过词嵌入、位置编码和分段编码处理,输入到12层的Transformer Encoder,每层由自注意力层和前馈神经网络组成。模型最后的输出可用于不同任务,如分类。在训练时,通过交叉熵损失进行优化;预测时,通过softmax得到概率分布。BERT在自然语言处理任务中表现优秀,广泛应用于实体识别、情感分析等领域。
本文深入剖析了BERT模型,包括输入编码、注意力机制、模型架构和输出结果。BERT使用Transformer的Encoder部分,通过多头自注意力机制捕捉上下文信息。输入经过词嵌入、位置编码和分段编码处理,输入到12层的Transformer Encoder,每层由自注意力层和前馈神经网络组成。模型最后的输出可用于不同任务,如分类。在训练时,通过交叉熵损失进行优化;预测时,通过softmax得到概率分布。BERT在自然语言处理任务中表现优秀,广泛应用于实体识别、情感分析等领域。
bert源码祥读
1 word2vec理解

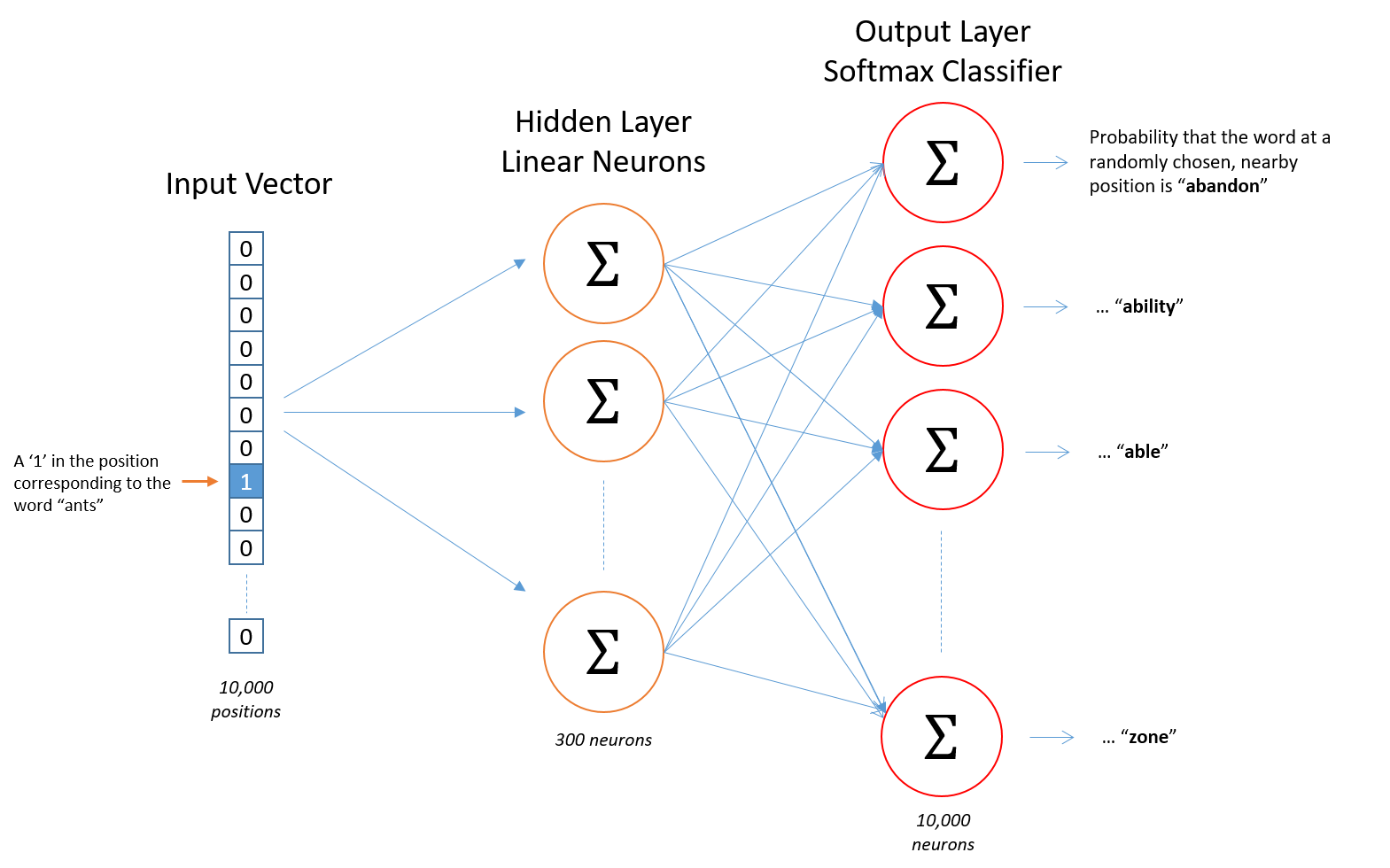

2 整体架构
- 输入如何编码?
- 输出结果是什么?
- Attention的目的?
- 怎样组合?
输入处理


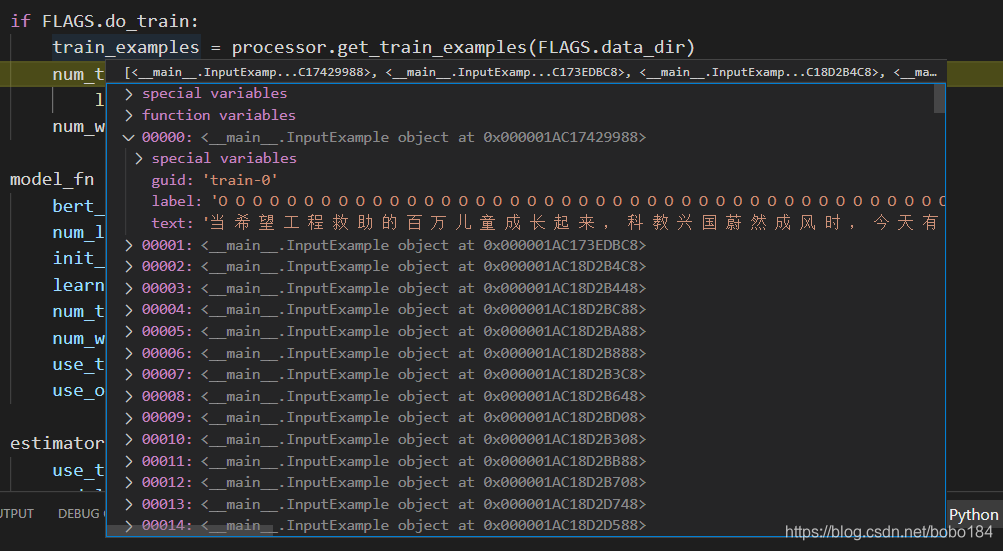
label_map: {‘B-LOC’: 6, ‘B-ORG’: 4, ‘B-PER’: 2, ‘I-LOC’: 7, ‘I-ORG’: 5, ‘I-PER’: 3, ‘O’: 1, ‘X’: 8, ‘[CLS]’: 9, ‘[SEP]’: 10}
textlist [‘当’, ‘希’, ‘望’, ‘工’, ‘程’, ‘救’, ‘助’, ‘的’, ‘百’, ‘万’, ‘儿’, ‘童’, ‘成’, ‘长’, …]
ntokens:[’[CLS]’, ‘当’, ‘希’, ‘望’, ‘工’, ‘程’, ‘救’, ‘助’, ‘的’, ‘百’, ‘万’, ‘儿’, ‘童’, ‘成’, …]
input_ids:[101, 2496, 2361, 3307, 2339, 4923, 3131, 1221, 4638, 4636, 674, 1036, 4997, 2768, …]
label_ids:[9, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …]
segment_ids:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …]
input_mask:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …] 128
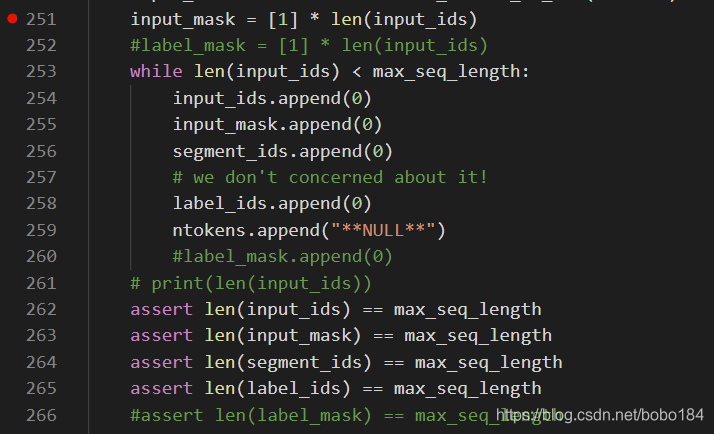
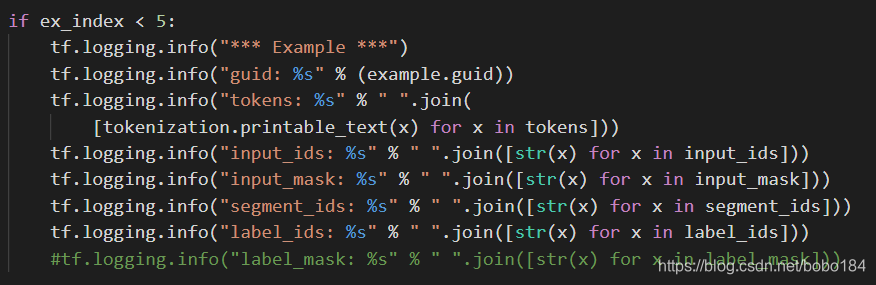


50658/32*3=4749

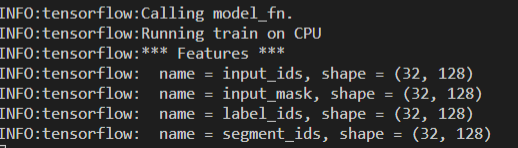
模型构建
input_ids (32,128)
input_mask (32,128)
label_ids (32,128)
segment_dis (32,128)
词嵌入过程
-
embedding_lookup return 返回值为word_embedding (32,128,768)

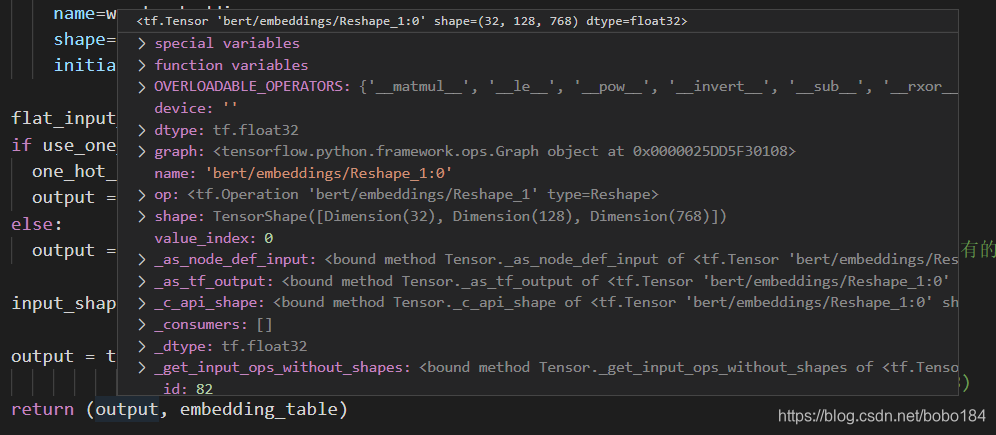
-
token_type_emdedding (32,128,768)
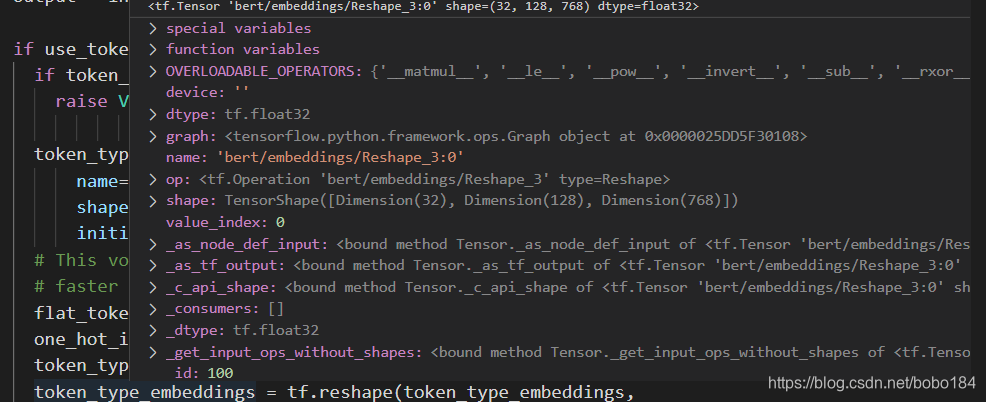
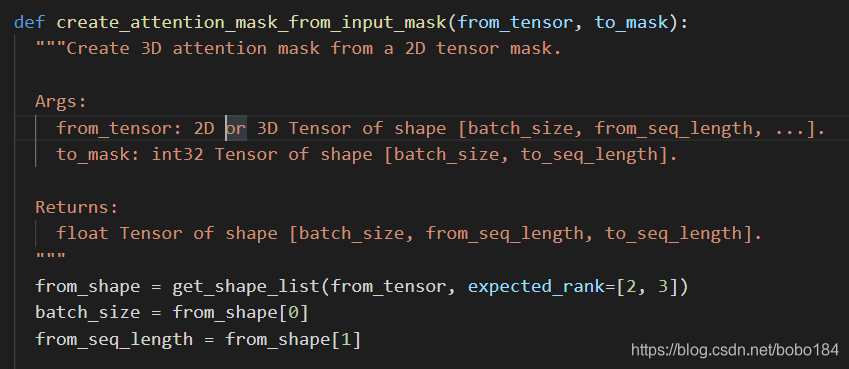
-
position_emdedding 刚开始初始化 为(512,768)
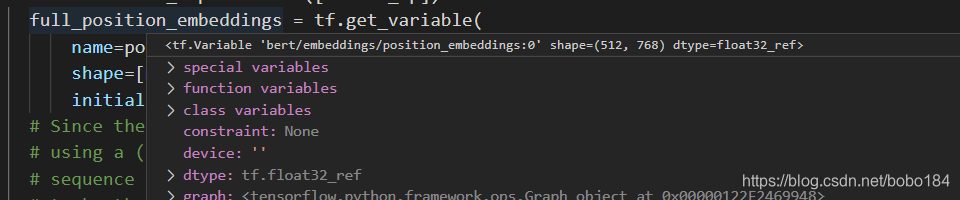
切片处理 (512,768) ->(128,768)

-
attention mask (32,128,128)
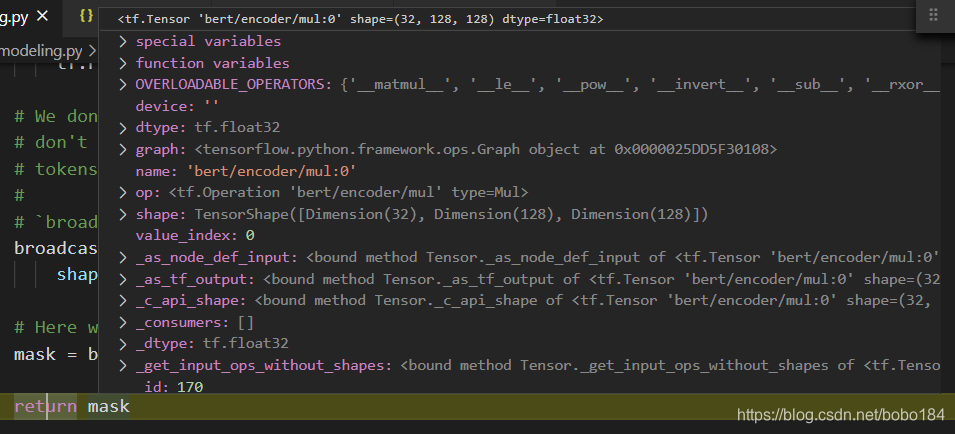

transformer结构
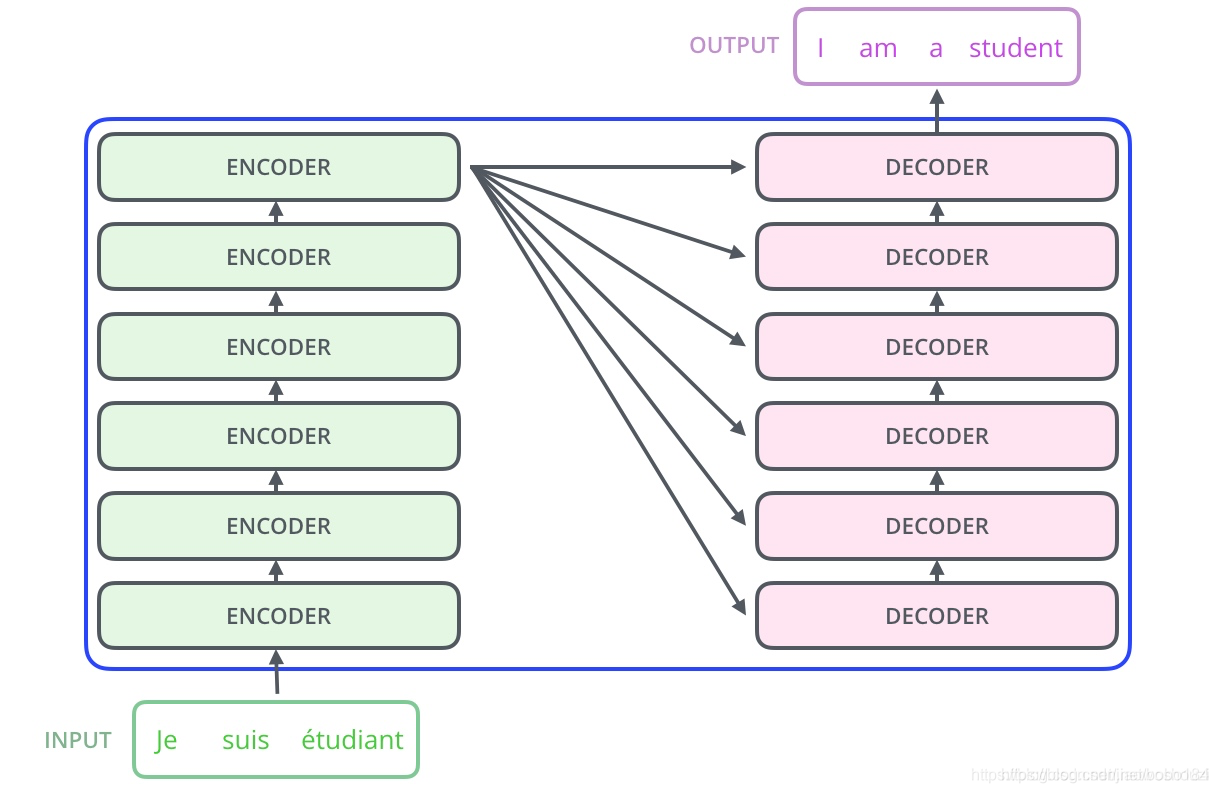
1.bert与transformer关系
在Transformer中,使用Encoder做特征提取器,然后用Decoder做解析,输出我们想要的结果。
而对于BERT,它作为一个预训练模型,它使用固定的任务——language modeling来对整个模型的参数进行训练,这个language modeling的任务就是masked language model,所以它是一个用上下文去推测中心词[MASK]的任务,故和Encoder-Decoder架构无关,它的输入输出不是句子,其输入是这句话的上下文单词,输出是[MASK]的softmax后的结果,最终计算Negative Log Likelihood Loss,并在一次次迭代中以此更新参数。所以说,BERT的预训练过程,其实就是将Transformer的Decoder拿掉,仅使用Encoder做特征抽取器,再使用抽取得到的“特征”做Masked language modeling的任务,通过这个任务进行参数的修正。
2.encode结构
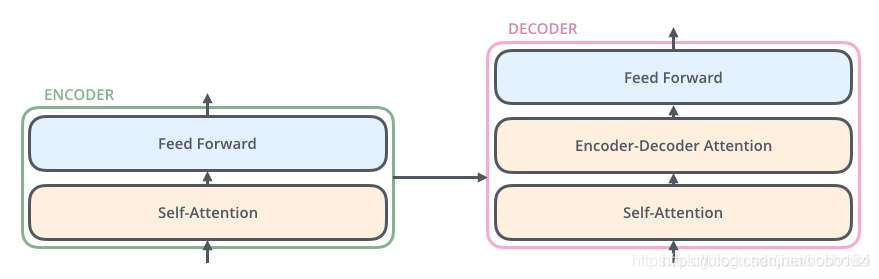
encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。decoder也包含encoder提到的两层网络,但是在这两层中间还有一层attention层,帮助当前节点获取到当前需要关注的重点内容。


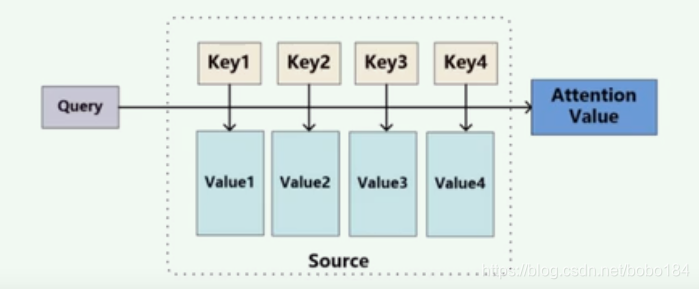
3.Self-Attention
举例:
The animal didn’t cross the street because it was too tired
The animal didn’t cross the street because it was too narrow
这里的it到底代表的是animal还是street,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,self-attention就能够让机器把it和animal联系起来

最终的得分值经过softmax 最终上下文结果
scaled Dot-Product Attention 不能让分值随着向量维度的增大而增加
每个词对于整个句子序列的贡献程度
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the same, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-with vector.
This function first projects `from_tensor` into a "query" tensor and
`to_tensor` into "key" and "value" tensors. These are (effectively) a list
of tensors of length `num_attention_heads`, where each tensor is of shape
[batch_size, seq_length, size_per_head].
Then, the query and key tensors are dot-producted and scaled. These are
softmaxed to obtain attention probabilities. The value tensors are then
interpolated by these probabilities, then concatenated back to a single
tensor and returned.
In practice, the multi-headed attention are done with transposes and
reshapes rather than actual separate tensors.
# Scalar dimensions referenced here:
# B = batch size (number of sequences) 8
# F = `from_tensor` sequence length 128
# T = `to_tensor` sequence length 128
# N = `num_attention_heads` 12
# H = `size_per_head` 64
from_tensor_2d = reshape_to_matrix(from_tensor)#(1024, 768)
to_tensor_2d = reshape_to_matrix(to_tensor)
#B:batchsize F:`from_tensor` T:`to_tensor` N:`num_attention_heads` H:`size_per_head`
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# `query_layer` = [B, N, F, H] #为了加速计算内积
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H] #为了加速计算内积
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
每一个子层(self-attetion)之后都会接一个残差模块,并且有一个Layer normalization
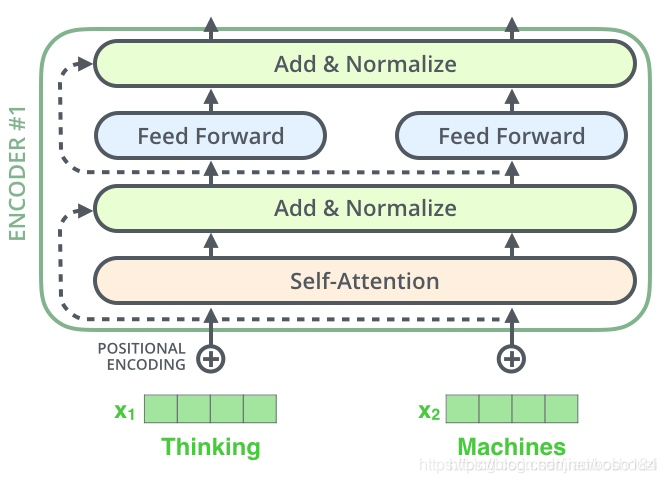
再一步细化可以得到下图
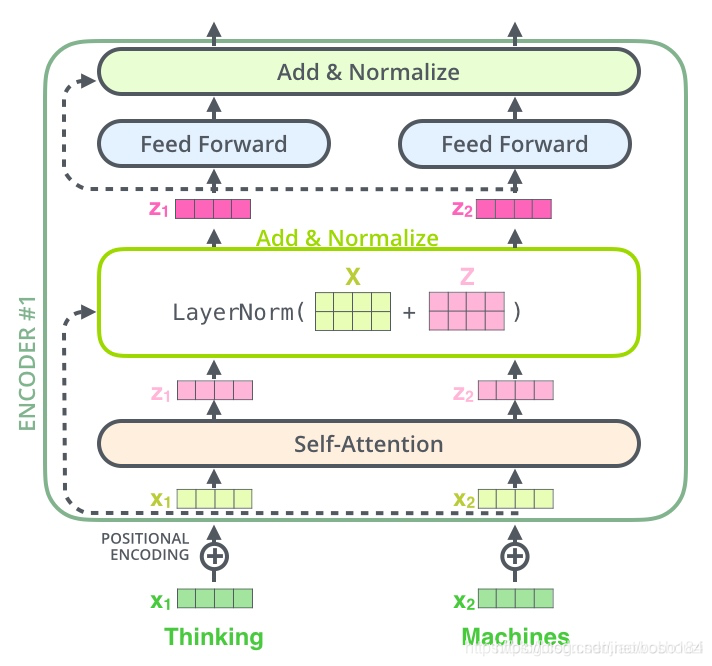
with tf.variable_scope("output"): #1024, 768 残差连接
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"): #全连接层 (1024, 3072)
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"): #再变回一致的维度
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
输出32x128x768
4.不同任务->需要的模型输出



self.sequence_output = self.all_encoder_layers[-1] #12层取最后一层 我们需要的
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.这对于段级的
# (或段对级)分类任务,我们需要一个固定的
#段的维度表示。
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1) #取第一个词[cls]
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
def get_pooled_output(self):
return self.pooled_output
def get_sequence_output(self):
"""Gets final hidden layer of encoder.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
to the final hidden of the transformer encoder.
"""
return self.sequence_output
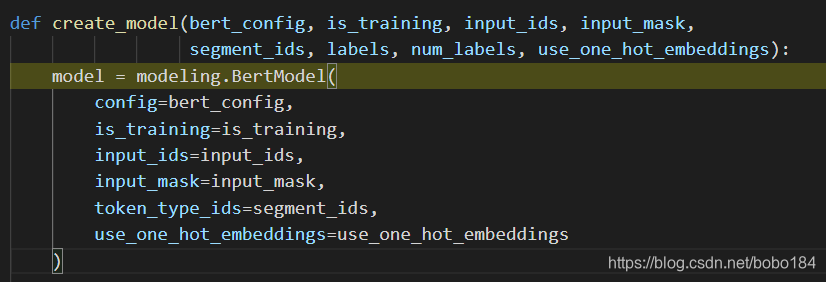
def create_model(bert_config, is_training, input_ids, input_mask,
segment_ids, labels, num_labels, use_one_hot_embeddings):
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings
)
output_layer = model.get_sequence_output() #shape=(32, 128, 768)
hidden_size = output_layer.shape[-1].value #768
#分类soft_max-> 全连接
output_weight = tf.get_variable(#权重w初始化
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02)
)
output_bias = tf.get_variable(#偏置b初始化
"output_bias", [num_labels], initializer=tf.zeros_initializer()
)
log日志
INFO:tensorflow:**** Trainable Variables ****
INFO:tensorflow: name = bert/embeddings/word_embeddings:0, shape = (21128, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/embeddings/token_type_embeddings:0, shape = (2, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/embeddings/position_embeddings:0, shape = (512, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/embeddings/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/embeddings/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_0/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_1/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_2/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_3/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_4/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_5/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_6/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_7/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_8/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_9/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_10/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/self/query/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/self/query/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/self/key/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/self/key/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/self/value/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/self/value/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/output/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/attention/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/intermediate/dense/kernel:0, shape = (768, 3072), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/intermediate/dense/bias:0, shape = (3072,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/output/dense/kernel:0, shape = (3072, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/output/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/output/LayerNorm/beta:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/encoder/layer_11/output/LayerNorm/gamma:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/pooler/dense/kernel:0, shape = (768, 768), *INIT_FROM_CKPT*
INFO:tensorflow: name = bert/pooler/dense/bias:0, shape = (768,), *INIT_FROM_CKPT*
INFO:tensorflow: name = output_weights:0, shape = (11, 768)
INFO:tensorflow: name = output_bias:0, shape = (11,)
一些小细节 我认为重要的
-
gelu激活函数


-
Positional Encoding

-
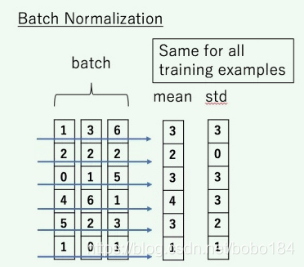
Layer normalization

-
token阶段的wordpiece
-
transformer中mask机制
自定义数据相关修改
1 训练修改
#自定义标签
def get_labels(self):
# prevent potential bug for chinese text mixed with english text
# return ["O", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", "[CLS]","[SEP]"]
# return ["O", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", "X","[CLS]","[SEP]"]
return ["O", "B-Product", "I-Product", "B-Organization", "I-Organization", "B-Component",
"I-Component", "B-Location", "I-Location", "B-Number", "I-Number","B-Percent", "I-Percent",
"B-Unit", "I-Unit","B-Time", "I-Time","B-Relation", "I-Relation","X","[CLS]","[SEP]"]
with tf.variable_scope("loss"):
if is_training:
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
output_layer = tf.reshape(output_layer, [-1, hidden_size])
logits = tf.matmul(output_layer, output_weight, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
# logits = tf.reshape(logits, [-1, FLAGS.max_seq_length, 11])
logits = tf.reshape(logits, [-1, FLAGS.max_seq_length, num_labels]) #当前任务的num_labels = 23
# mask = tf.cast(input_mask,tf.float32)
# loss = tf.contrib.seq2seq.sequence_loss(logits,labels,mask)
# return (loss, logits, predict)
##########################################################################
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_sum(per_example_loss)
probabilities = tf.nn.softmax(logits, axis=-1)
predict = tf.argmax(probabilities,axis=-1)
return (loss, per_example_loss, logits,predict)
2 预测修改
还是修改对应的num_labels
def metric_fn(per_example_loss, label_ids, logits):
# def metric_fn(label_ids, logits):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
precision = tf_metrics.precision(label_ids,predictions,11,[2,3,4,5,6,7],average="macro") #修改为自己的标签数和对应位置
recall = tf_metrics.recall(label_ids,predictions,11,[2,3,4,5,6,7],average="macro")
f = tf_metrics.f1(label_ids,predictions,11,[2,3,4,5,6,7],average="macro")
#
3 预测结果
数字和单位实体


关系实体

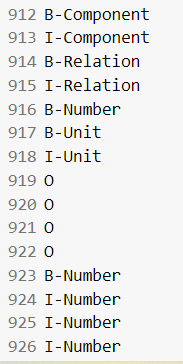
todo
-
self-attention详细计算过程
- q,k,v
-
bert predict
-
bert之后改进 albert使用以及将最后的全连接层改为Bi-lstm+crf层提高准确率
-
针对不同的数据的修改

















 4105
4105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









