







使用实例损失学习图像-文本嵌入
最新版应该是2020发表在ACM上的
本文从实例级别上来考虑cross-modal检索问题(无监督)
图像和文本都有丰富的语义,但是停留在异构模式中,将图像和文本映射到一个共享的特征空间是一个挑战。
过去,通常使用ranking loss(使正样本对之间的距离比负样本对之间的距离小于预定义margin)作为image-text表征学习的目标函数。

如上图:动机。将image/text组定义为一张图像和与其相关的句子。我们观察到,一个图像/文本组彼此之间或多或少存在差异。因此,我们在训练期间将每个image/text视为一个不同的类,从而产生实例损失。
每对训练样本中包含一个视觉特征和一个文本特征,ranking loss集中在两种模式之间的距离上,而没有明确考虑单个模态中的特征分布。那么对于两个相近(语义略有不同)的测试图像,这类精细粒度的任务(比如区别灰狗和黑狗)就比较难以完成。在实验中也证明使用ranking loss可能会导致网络陷入局部最小值。
本文使用image-text匹配数据集来微调word2vec模型[T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv:1301.3781, 2013. ]。而Instance Loss旨在为ranking loss提供更好的权重初始化,从而产生更discriminative和鲁棒的image-text描述。
本文提出一个双流(dual-path)CNN模型用于视觉-文本嵌入学习。即在该任务中,CNN+CNN的结构比RNN+CNN更加高效。
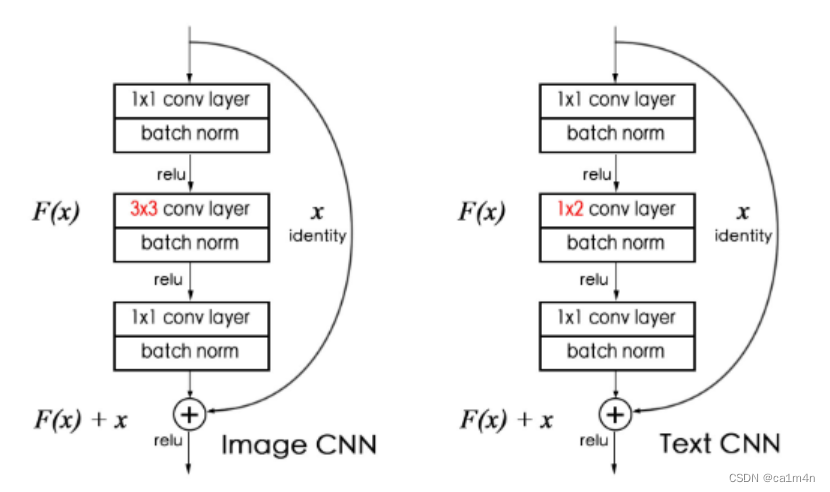
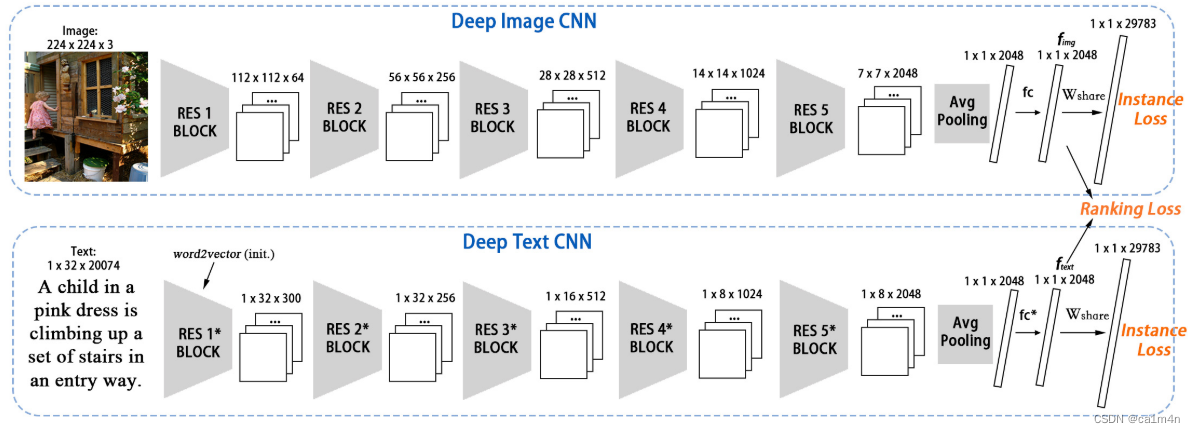 如下图,深度图像CNN和深度文本CNN的基本块。与图像的局部模式类似,句子中的邻接词可能包含重要线索。图像CNN中的滤波器尺寸为3X3带有高度和宽度填充;文本CNN中的滤波器带下为1X2带有长度填充。此外,我们还使用了一个shortcut连接,这有助于训练深度卷积网络。输出F(x)+x和输入x具有相同的大小。
如下图,深度图像CNN和深度文本CNN的基本块。与图像的局部模式类似,句子中的邻接词可能包含重要线索。图像CNN中的滤波器尺寸为3X3带有高度和宽度填充;文本CNN中的滤波器带下为1X2带有长度填充。此外,我们还使用了一个shortcut连接,这有助于训练深度卷积网络。输出F(x)+x和输入x具有相同的大小。
训练过程分为两个阶段:
Stage I 使用固定的经预训练的image CNN并仅使用instance loss训练text CNN(往往需要从头进行训练),以避免预训练好的image CNN受损;
Stage II 对整个网络进行端到端的微调(结合instance loss和ranking loss),包括image CNN。
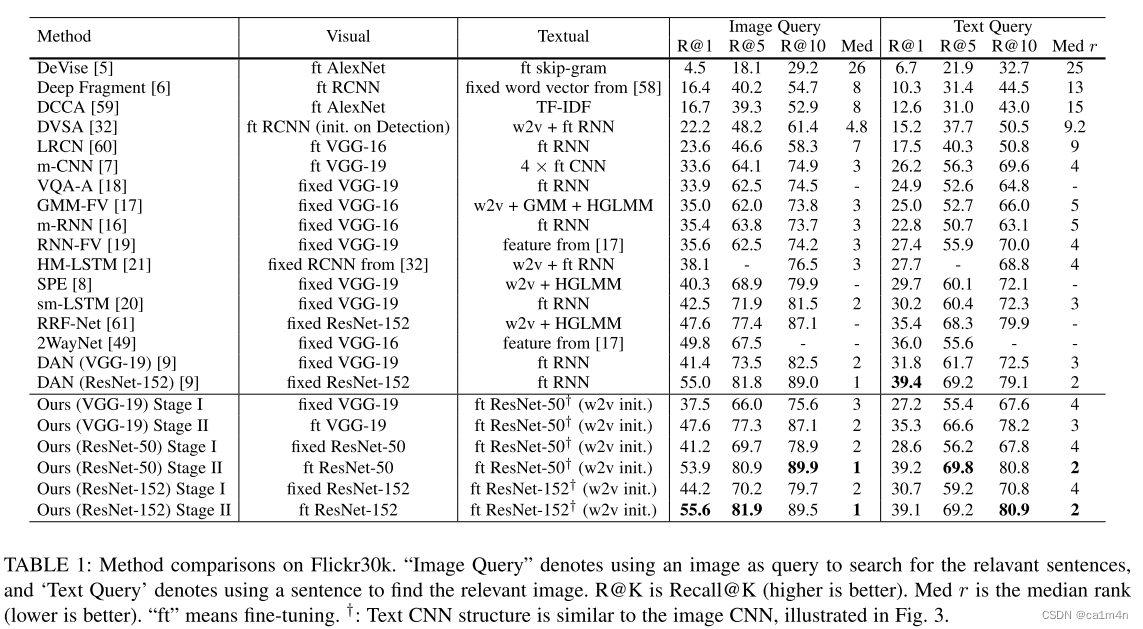
实验结果:
















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











