







原文作者:Zhaopeng Qiu, Xian Wu, Jingyue Gao, Wei Fan
原文标题:U-BERT: Pre-training User Representations for Improved Recommendation
原文来源:AAAI 2021
原文链接:https://www.aaai.org/AAAI21Papers/AAAI-2116.QiuZ.pdf
U-BERT: Pre-training User Representations for Improved Recommendation
对于推荐系统来说,学习到精确的用户representation是非常重要的。早期的研究方法从user-item评分矩阵中得到用户representation。但是这种办法存在问题,评分矩阵通常十分稀疏,而且评分也比较粗粒度。有些方法使用了review增强用户的表征,但是由于某些领域的review非常少,也无法获得准确的用户表征。本文提出的U-BERT方法很好的解决了这个问题。
问题定义
U = { u k } k = 1 k = M 和 I = { i j } j = 1 j = N \mathcal{U =}\left\{ u_{k} \right\}_{k = 1}^{k = M}和\mathcal{I =}\left\{ i_{j} \right\}_{j = 1}^{j = N} U={ uk}k=1k=M和I={ ij}j=1j=N分别表示领域D中的用户集和item集,领域D中的评论集为 T f \mathcal{T}_{f} Tf( U \mathcal{U} U写给 I \mathcal{I} I),每条评论包含user ID u u u,item ID i i i,文本 s s s,评分 r r r。用户在其他领域的评论集为 T p \mathcal{T}_{p} Tp,评论的格式与上述相同(item集不同)。
模型架构
模型分为两个部分:pre-training和fine-tuning。预训练阶段,通过两个自监督任务从不同领域的评论中预训练U-BERT模型和用户表征。微调阶段,使用预训练好的模型U-BERT编码用户特征,帮助item编码器得到领域D的评论中的item表征。通过监督评分预测任务,得到领域D最终的推荐模型。
预训练阶段
预训练阶段的模型架构如图2所示。有三个模块组成:输入层、评论编码器、用户编码器。
输入层
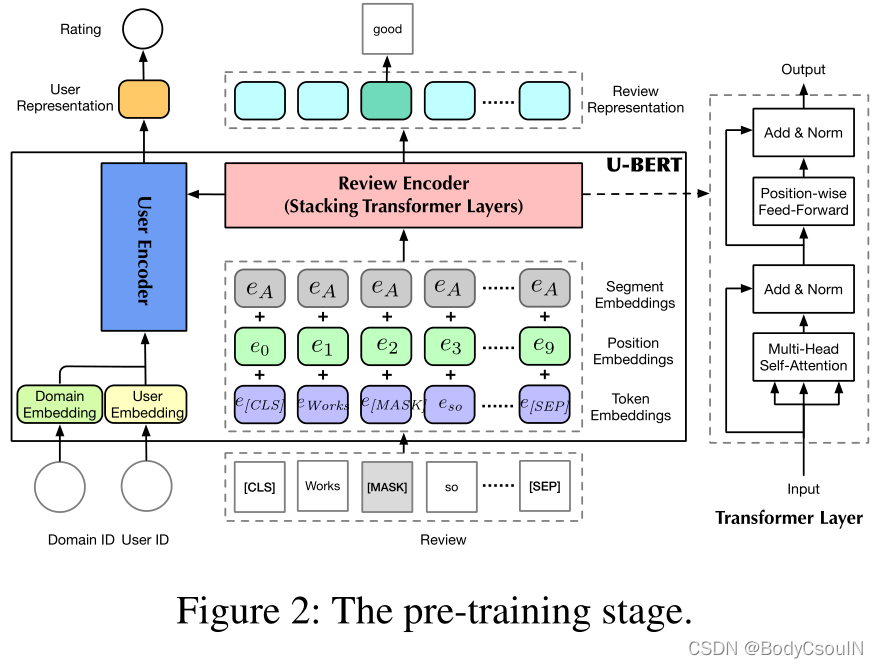
输入评论文本、用户ID和相应的领域ID。输入的每一条评论,添加[CLS]和[SEP]到起始和末尾位置。然后将评论中的每一个单词通过矩阵 E W ∈ R ∣ V ∣ × d \mathbf{E}_{W} \in \mathbb{R}^{\mathcal{|V| \times}d} EW∈R∣V∣×d转化为对应的嵌入向量, ∣ V ∣ \mathcal{|V|} ∣V∣是单词表的大小, d d d是嵌入向量的维度。然后每个嵌入向量加上相应的segment embedding和position embedding。最终一条评论的representation为 S ∈ R L s × d \mathbf{S} \in \mathbb{R}^{L_{s} \times d} S∈RLs×d, L s L_{s} Ls是评论s的长度。
用户ID也转化为d维的向量 u \mathbf{u} u,通过嵌入矩阵 E U ∈ R ∣ U ∣ × d \mathbf{E}_{U} \in \mathbb{R}^{\mathcal{|U| \times}d} EU∈R∣U∣×d。为了解决两个阶段中领域不一致的问题,作者引入了domain ID来建模特定domain的信息。同样通过一个矩阵 E O \mathbf{E}_{O} EO将domain ID转化为向量 o ∈ R d \mathbf{o} \in \mathbb{R}^{d} o∈Rd。
review encoder
使用多层Transformer。 S l = { e t l } t = 1 t = L s \mathbf{S}^{l} = \left\{ \mathbf{e}_{t}^{l} \right\}_{t = 1}^{t = L_{s}} Sl={ etl}t=1t=Ls表示第 l + 1 l + 1 l+1个Transformer层的输入,也就是第 l l l的输出。 S 0 \mathbf{S}^{0} S0就是review encoder的输入,也就是上文提到的 S \mathbf{S} S**。**不同的Transformer层之间的参数是不同的。每个Transformer层包括两个子层,Multi-Head Self-Attention和Position-wise Feed-Forward。
Multi-Head Self-Attention层中,使用上下文语义增强评论中每个单词的representation。使用三个矩阵 Q ∈ R L Q × d 、 K ∈ R L K × d 、 V ∈ R L V × d \mathbf{Q} \in \mathbb{R}^{L_{Q} \times d}\mathbf{、}\mathbf{K} \in \mathbb{R}^{L_{K} \times d}\text{、}\mathbf{V} \in \mathbb{R}^{L_{V} \times d} Q∈RLQ×d、K∈RLK×d、V∈RLV×d,而且 L K = L V L_{K} = L_{V} LK=LV。
Attn ( Q , K , V ) = Softmax ( QK ⊤ / d ) V \text{Attn}(\mathbf{Q},\mathbf{K},\mathbf{V}) = \text{Softmax}\left( \mathbf{\text{QK}}^{\top}/\sqrt{d} \right)\mathbf{V} Attn(Q,K,V)=Softmax(QK⊤/d)V
每个attention head都使用上式计算,即:
head i = Attn ( S l W i Q , S l W i K , S l W i V ) \text{head}_{i} = \text{Attn}\left( \mathbf{S}^{l}\mathbf{W}_{i}^{Q},\mathbf{S}^{l}\mathbf{W}_{i}^{K},\mathbf{S}^{l}\mathbf{W}_{i}^{V} \right) headi=Attn(SlWiQ,SlWiK,SlWiV)
head i ∈ R L s × d / h \text{head}_{i} \in \mathbb{R}^{L_{s} \times d/h} headi∈RLs×d/h然后将多个head拼接起来:
MH ( S l ) = [ head 1 ; … ; head h ] W O \text{MH}\left( \mathbf{S}^{l} \right) = \left\lbrack \text{head}_{1};\ldots;\text{head}_{h} \right\rbrack\mathbf{W}^{O} MH(Sl)=[head1;…;headh]W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









