







一 序
本文属于贪心NLP训练营学习笔记系列。在之前的机器学习的分享中,是关于传统机器学习的一些重要的模型,从本节课开始学习深度学习。
神经网络 只是借鉴了生物学的神经系统,与真实的大脑生物学还差别很大。
二 神经元
人工神经元(Artificial Neuron),简称神经元(Neuron),是构成神经网络 的基本单元,其主要是模拟生物神经元的结构和特性,接收一组输入信号并产生输出。
我们把神经元,分为pre-Activation,post-Activation 两个过程。
pre-Activation:假设一个神经元接受D个输入。我们用下面的公式:
表示一个神经元所获得的的输入信号x的加权和,就是一个线性的关系。
post-Activation:
其中非线性函数 叫做激活函数(Activation Function),对于 pre-Activation 通常使用线性模式,但是
可以有不同的激活函数。类似于超参数。

三 激活函数
激活函数在神经元中非常重要的,不同的激活函数尤其是在多层神经网络如何选择对于最终的结果影响很大。
作用:激活函数的主要作用是提供网络的非线性建模能力,如果没有激活函数,那么神经网络只能表达线性映射。多层网络就跟单层没啥区别了。
下面开始介绍常见的激活函数:
线性激活 linear activation function
输出和输入相等或者成比例。常用你在神经网络的最后一层,它的问题:它的导数是常数,梯度也是常数,梯度下降无法工作。

这里老师画图讲解,多层的线性转换跟单层是一个效果。只有非线性转换,深度神经网络才具备了分层的非线性的学习能力。
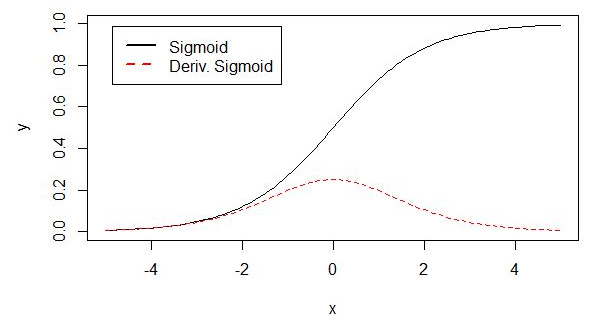
Sigmoid函数
之前在学习逻辑回归的时候,了解过它的特点。值域(0,1),定义域 实数域。具有很好的性质用于输出概率,可以被表示做分类问题(用值域表示)
它的特点:输入越小,越接近于0;输入越大,越接近于1。严格递增的。

Tanh函数
Tanh函数可以看作放大并平移的Logistic函数,其值域是(−1, 1)。

插一个点,Sigmoid或tanh的缺点:梯度消失问题,老师没有讲。参照网上的介绍简单看下,因为没学习后面反向传播的推导过程,就是大致的印象。
sigmoid两侧导数逐渐趋近于0, 即
,具体来说,在反向传播的过程中,sigmoid的梯度会包含了一个f(x)的导数因子,因此一旦输入落入两端的饱和区,
就会变得接近于0,导致反向传播的梯度也变得非常小,此时网络参数可能甚至得不到更新,难以有效训练,这种现象称为梯度消失。
ReLU(Rectified Linear Units)
ReLU修正线性单元函数 ,公式如下:
对于所有正值,ReLU是线性的(identity),对于所有负值,ReLU是零的。
- 由于没有复杂的数学运算,因此计算开销小,所以训练速度会更快。
- 当输入值为正数时,导数为1,那么就不存在梯度消失的问题了,每层的网络都可以得到相同的更新速度。
- 它可以被稀疏地激活。
注意下面截图老师的讲的sparse 稀疏性。这个稀疏性是指的模型稀疏性,而不是之前one-hot模型那种数据稀疏性。
稀疏性模型通常具有更好的预测能力和更少的过拟合.直观上可以这样理解,人的大脑有很多的神经元,但是有分工的。它们具有不同的作用,并由不同的信号激活。
所有负值均为0导致的问题,会导致权重无法更新,这种现象称为“神经元死亡”。这里老师没展开讲

****************
逻辑回归是神经网络的特例:
假设激活函数是Sigmoid 函数。
当y=1时, ,是逻辑回归的目标函数。

四 多层感知器(Multi-Layer Perceptron,MLP)
4.1 单层神经网络:

在介绍多层神经网络之前,先给大家介绍只有一层隐藏层的神经网络:输入为X,是D维的。.经过一层神经元之后,输出为
,最终的输出为
.
每一个神经元都是经历两个过程,第一个过程是pre-Activation 将输入线性化,然后将结果作为输入进行第二个过程post-Activation.
用 是第i个神经元的pre-Activation。
是第i个神经元的post-Activation.
那么 注意这里的上标 (1) 表示为第一层网络。
表示隐藏层第1个神经元与输入层第2个输入的权重.
举例隐含层的第一个神经元, ,同理到
可以依次表示出来,最终的
表示a(x)向量构成.
看做是有
构成的向量。
具体使用什么激活函数,取决于 f(x)是什么问题,如果是回归问题,一般采用线性激活函数,如果是分类问题,一般采用softmax激活函数.
4.2 多分类问题(Multiple outputs classification &loss)

在一个多层网络的模型里,最后的输出层我们一般单独处理,老师讲了一个多分类问题的处理思路:
最后一层神经元的执行两个过程,分别是:pre-Activation 部分是
post-Activation 部分是,这里的激活函数就是softmax激活函数.
我们通过softmax 激活函数,可以计算出每一个分类的一个概率,这是预测值,概率和为1。
上面截图 计算出概率分别为:0.3,0.6,0.1我们也有真实的标签:0,1,0(one-hot编码).我们需要计算两者之间的差异,因为我们要计算一个损失函数,计算的过程就是训练的过程,然后不断去减少损失函数,就是计算交叉熵类似于逻辑回归。
4.3 multi-layer neural network

本节学习多层神经网络的数学表达,假设具有L层神经网络,L就表示有几个隐含层,最上面是out-put层。
假设是第k层,那么其中第k层的pre-Activation就是上一层的一个线性转换。
post-Activation 部分是
output层: 这里的激活函数,举例可以用softmax。
万能近似定理Universal Approximation Theorem
这里老师插入一个背景知识点,这个理论对于深度学习有重要指导影响。

在具有一个隐含层的神经网络中,如果给定足够多的神经元,它可以用来近似任何连续型函数;
意思是即使这样一个简单的模型,它也可以模拟出任何复杂的函数,不需要多层,本质上是学会了x到y的映射f(x)。

缺点:目前我们还没有任何一种理想中的优化算法去学出这个参数,如果以后能设计出一种算法可以学出这个参数,那么我们将不再需要搭建很多层神经网络,只需要搭建一层即可。
五 大脑工作流程

这里说了两个点,1是人的大脑分成几个区域,区域是功能不同的。2是对信息的处理流程,以视觉举例,不同的神经元参与了活动,我们感知到的东西会越来越具象化。
我们希望的神经网络就是这样的一种结构,就是有分布式的特点的,能一层一层的去感知世界,这一点和大脑的处理方式是比较类似的。但是大脑真正的处理机制没有完全搞懂,有待科学技术发展。















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









