







一 序
本文属于贪心NLP训练营学习系列。上节课学习了神经网络的数学表达,本节学习数学表达式的参数w,b.
二 神经网络的损失函数
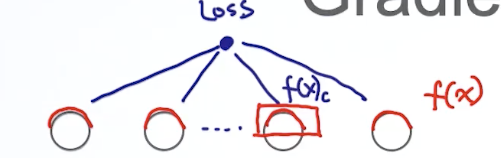
假设模型有一个输入层,一个输出层以及L个隐含层。我们把softmax作为输出层的激活函数.
我们把output层的pre-Activation部分写作,post-Activation 部分写作f(x).
损失函数主要部分:, 其中 参数
损失函数包含两项是预测值,真实值。
损失函数: ,前面的均值函数为经验风险,后面结构风险(可以看做是正则项,为了解决过拟合的问题)。
区分损失函数、代价函数和目标函数之间的区别和联系:
损失函数(Loss Function)通常是针对单个训练样本而言。
代价函数(Cost Function)通常是针对整个训练集。
目标函数(Objective Function)通常是一个更通用的术语,表示任意希望被优化的函数。
三者关系:A loss function is a part of a cost function which is a type of an objective function。
接下来是使用随机梯度下降法SGD求解的过程。
初始化
接下开看函数L怎么表达。
交叉熵损失函数
假设是一个四分类问题,我们可以计算出 f(x)的值,{0.6,0.2,0.1,0.1},我们的真实值y通常用one-hot表示,{0,1,0,0},
那么f(x) 与y的交叉熵=
推广来看,对于任意的f(x),y ,,这里的y是下标。因为对于one-hot方式,只有一个值为1,其余为0.

三 BP算法
损失函数对于要求参数,就是loss对于整个网络每个参数梯度。为了计算梯度,涉及了几个方面的计算。
loss对于output层的post-Activation 部分f(x).对于output层的pre-Activation部. output层需要特殊处理 。
对于隐含层,post-Activation 部分 ,pre-Activation部分
.
最后,计算loss对于参数()
BP算法的学习过程由正向传播过程和反向传播过程组成。在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果在输出层得不到期望的输出值,则取输出与期望的误差的平方和作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数(也称梯度),构成目标函数对权值向量的梯量,作为修改权值的依据,网络的学习在权值修改过程中完成。误差达到所期望值时,网络学习结束。

3.1 Gradient Computation of output
由于是一个具体的值,而
是一个向量,所以我们先考虑一个值.假设是第c个值,则我们先考虑
= 其中:
那么
其中采用独热向量编码编码,如果y=1,
再计算 第二个

这里output层从到
我们当做分类器使用,就是
是
经过softmax函数的转行.所以我们按照softmax的定义,先把
表示出来。
=
补充一个求导基础运算
= 对照视频拼写了最复杂的式子了,下面进行 简化。
= 注意是对
复合函数的求导
= 利用了softmax函数的定义
=
=
现在我们求出了loss对于out-put层第c个神经元的pre-Activation梯度,同样我们 参照上面按照向量表达的方法求解loss对于的梯度
这里的
3.2 Gradient Computation of hidden layer
对于隐含层,在做反向传播的时候loss对它的 post-Activation 部分的梯度是依赖于上一层的pre-Activation节点的。
为了求解第K层的梯度,会使用到链式求导方法。
如果计算从A到B的梯度,只途径C点 :
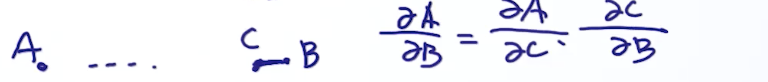
如归途径多个点().

所以,
根据神经网络的定义:
= 后面的一项,这里当j=c,求导为1.只剩下
= 把i向量化展开。
上面是只考虑一个神经元的情况。同样对于
我们再来 看隐含层pre-Activation的梯度计算。在做反向传播的时候,它是依赖于post-Activation的。
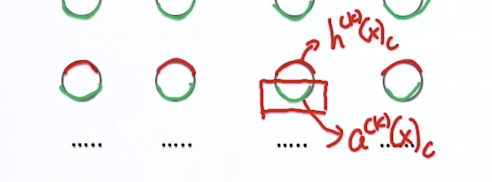
所以根据链式求导方法:
= 这里的
所以
这里引入一个概念: ,
,
这是element-wise product 元素智能乘积。
3.3 Gradient Computation of parameter
损失函数
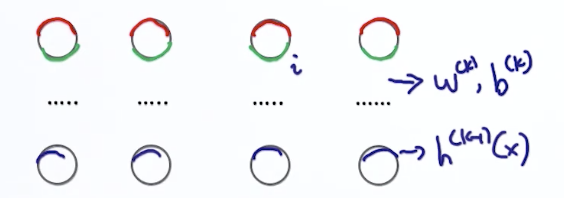
根据 pre-Activation 的方程可知
同样,
向量展开就是下图的样式

= 因为b起到的是偏移量,对于求导=1
意思就是BP神经网络中所有参数的梯度,主要是链式求导法则。接下来看怎么吧这些参数套用到BP算法之中 。
3.4 BP算法参数更新过程
for training data (x,y)
1 compute output gradient
采用独热向量编码编码,如果y=1,
2 对于隐含层反向循环,就是从k=L+1 ->1
a. compute gradient of parameter
b. compute gradient of hidden layer
**************

如同网上的很多文章,对于BP算法的介绍,更 倾向于列公式 ,尤其是数学不好跟我这种就晕了。有些背景知识就是神经元的分层,输入层、输出层、隐含层通常怎么处理。
权值矩阵w 行列的意义,行代表着这一层有多少个神经元,列代表上一层的输出向量的维度。矩阵好处是element-wise product方便。
再就是要理解BP算法的流程。不是上来就看反向传播,正向传播的流程也要理解,正向传播就是将一个样本输入到神经网络,从而获得输出值的过程,参见上面截图,目的是为了保存下各种中间变量
(过程就是不断将输入做线性组合,再应用激活函数,转换成输出,再到下一层的输入,不断重复直到到达神经网络的最后一层)。
反向过程是 先计算出out-put层的梯度 ,再逐层计算隐含层的参数 ,再计算隐含层的梯度。
最后才是BP算法的数学推导过程。
这里推荐看下:https://www.jiqizhixin.com/graph/technologies/7332347c-8073-4783-bfc1-1698a6257db3
四 Gradient checking
由于在BP算法中网络比较复杂,参数比较多,如果写错参数经过多层网络会带来比较大影响。如果 使用TensorFlow或者pytouch这种 三方框架时,它们已经帮我们集成了这个技巧。我们自己手动实现时,通常会使用gradient checking来防止写错参数带来的影响。
利用导数(梯度)的定义:
当很小->0,如果我们用导数定义跟我们实际公式求出的差小于阈值时,我们就认为导数是正确的
















 3152
3152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









