






近日国家数据局印发了《可信数据空间发展行动计划(2024—2028年)》,提出到2028年要建成100个以上可信数据空间,可以预见的是接下来的三年时间里,全国各地将掀起一阵可信数据空间建设热潮。为了帮助更多的人理解可信数据空间这一新概念,笔者查阅了相关文献资料,形成了自己对这一概念的理解,并总结成本文,分享给读者。
需要说明的是,文章所述内容皆为个人理解,如有不准确的地方,还请留言指正。
一、问题的提出
假设某区域有几家早餐店,他们都出售鸡蛋、包子、油条、等食物,为了业务发展的需要,他们都希望了解以下信息:(1)区域市场容量有多大,即区域内每天一共可以卖出多少钱的早餐;(2)哪种食物更受欢迎,即每种食物各卖出多少钱。
这些问题的解决,看上去很简单,只需要把5家早餐店的销售数据都拿出来做个汇总和分类汇总就可以了。然而,事实上,这些数据对于每一家早餐店来说,都属于核心的商业秘密,都不愿被竞争对手(甚至也包括开展统计计算的人)知晓。所以,如何在不向任何人泄露自己数据的前提下,获得所有早餐店的汇总和分类汇总数据,就成了一个极具挑战性的问题。
可信数据空间的概念,就是为了解决上述问题而提出的。可信数据空间(Trusted Data Space)是一个旨在确保数据共享与交换过程中的数据隐私、安全性和可信度的概念。它通常是通过建立一套可靠的技术和治理框架,使不同的数据拥有者能够在保护自身数据隐私的前提下共享数据资源,并保证数据在使用过程中的透明性、合规性以及可追溯性。
二、问题的分析
让我们回到文章开头提出的5家早餐店的问题上,为了解决前述的问题,我们必须解决好以下三方面的问题:
1. 数据存储的问题
数据要存储在安全的环境或者介质中,这里的安全是指数据不能被非法读取。早餐店的销售数据存储在各自的电脑系统中,物理环境方面,通常情况下不进入早餐店、或者没有登录密码都无法操作电脑也就无法读取数据,所以数据的安全性是靠物理环境隔离与系统密码保护的。然而,这种安全性的保证是有代价的,这个代价就是为数据的共享制造了障碍,任何被授权的人或者系统,读取数据时都是不太方便的,而计算5家店的统计数据,是一定需要读取每家店的数据的。幸运的是,这个例子中只有5家店,数据共享的成本还不算太高,但如果是10万家店,这个数据共享的问题就表现得较为凸出了。
为了更好的解决该问题,降低数据共享的成本,我们可以考虑另一种更优的方案,把大家的数据都存在一起,比方说同一个数据库或者同一个网络硬盘,每家店都给自己的数据加密,这样,即使能够得到别人数据,这些数据也是加密后的一堆乱码,毫无意义。如果需要共享给别人访问的时候,只需要把密码告诉别人就可以了。当然,现实的系统中需要解决的问题远比这里的情形要复杂,比方说部分授权访问或者限时授权访问等问题。
目前,解决数据统一存储,访问过程可追溯等问题地一项重要技术就是“区块链”,因此区块链技术是可信数据空间地重要支撑性技术之一。
2. 数据传输的问题
为了做全局的统计与分析,需要将各个店的数据(可以是加密过或者处理过的)分享给其他店,这里的分享其实包含了数据传输的过程,通常情况下,这些数据是通过网络进行传输的,因此数据在传输的过程中如何防止被侦听也是一个需要解决的问题。
为了解决数据在网络上安全传输的问题,可以采用加密传输的方法,这类方法已有大量的成熟技术方案。因此,数据加密技术,也是可信数据空间地重要支撑性技术之一。
3. 数据计算的问题
数据计算的问题是该例子中最核心也最有挑战性的问题,这种挑战性集中地体现在如何计算出正确的结果,又保证各方的数据都不被其他各方知晓,这类问题在学术上被称为“隐私计算“技术。
幸运的是,学术界对于隐私计算问题的研究很早就开始了,而且已经取得了很多重要的成果,多种具体的技术方案,已经可以在一定程度上解决该问题,所以,隐私计算技术也是可信数据空间的重要支撑性技术之一。
目前,隐私计算技术的发展已经可以支撑常见的统计学分析,例如求和、求均值、求方差、求最值等,也可以完成线性回归、逻辑回归等简单的机器学习算法;但因受限于处理精度以及通信开销等问题,隐私计算在处理复杂的非线性优化(深度学习、复杂的神经网络训练等)、实时计算和大规模处理(视频流分析、语音识别、大数据实时分析等)、大规模多方协同计算(通信开销极大)等问题时,还存在很多局限和挑战。
三、问题的拓展
让我们进一步拓展前述的早餐店的例子,假设这几家早餐店利用隐私计算等技术解决了前述的问题之后,他们认为该数据对于其他希望进入餐饮行业的创业者具有重要的价值,希望向他们出售该数据,以获得额外的收益。这时,如何实现数据的交易,如何证明数据确实来自于他们5家区域有影响力的早餐店,以及如何根据贡献数据的多少分配利益等一系列现实的问题就凸显了出来。
区块链技术可以实现分布式记账,可在没有第三方背书的情况下完成交易,可以在很大程度上解决数据如何交易,如何结算,如何溯源等问题。
让我们再进一步拓展前述的例子,假如这5家早餐店,希望紧跟人工智能发展的脚步,利用手里的销售和企业经营的数据训练一个智能体或者一个大模型,这个大模型可以回答关于早餐行业的很多问题,为早餐店和其他社会实体提供有价值的咨询服务。这时候他们又面临一个问题,如何在不泄露各自数据的前提下,使用大家数据的合集共同去训练一个大模型,这就是“联邦学习”技术需要解决的问题了。
联邦学习技术可以使用分布式的数据完成神经网络模型的训练,它把训练分成两阶段,继续以5家早餐店的例子来说,各个早餐店先使用自己手中的数据完成第一阶段模型的训练,然后把训练好的模型,注意不是原始数据,上传到服务器,由服务器再基于上传的局部训练数据完成最后的聚合训练,最终完成整个模型的训练。
由上述介绍可知,从广义上来说,联邦学习可以看作是“模型训练这一特定问题的隐私计算解决方案”,或者叫“基于隐私计算的模型训练”。
四、问题的总结
通过对上述具体案例分析我们可以看出,可信数据空间是在保证数据安全与数据隐私的前提下实现数据分布式的加工分析、交易记账、数据溯源的一整套解决方案。其主要支撑性技术包括:区块链、隐私计算、联邦学习、加解密等。
五、“可信数据空间”与“数据元件”概念
最后,必须说明的是,可信数据空间不是同类问题唯一的解决方案,除此之外,还有包括数据元件在内的其他解决方案。相较于可信数据空间,数据元件技术方案采用集中式的处理方式,通过物理隔离与软件隔离的方式,保证数据隐私与数据安全。此外,数据元件技术着眼于数据加工环节的安全与隐私保护,几乎没有涉及数据溯源与交易记账等问题。从某种意义上来说,数据元件技术可以被广义的看作是“集中式(非分布式的)的、环境隔离的、第三方背书(中心化的)的隐私计算解决方案”。
六、可信数据空间软硬件系统的组成
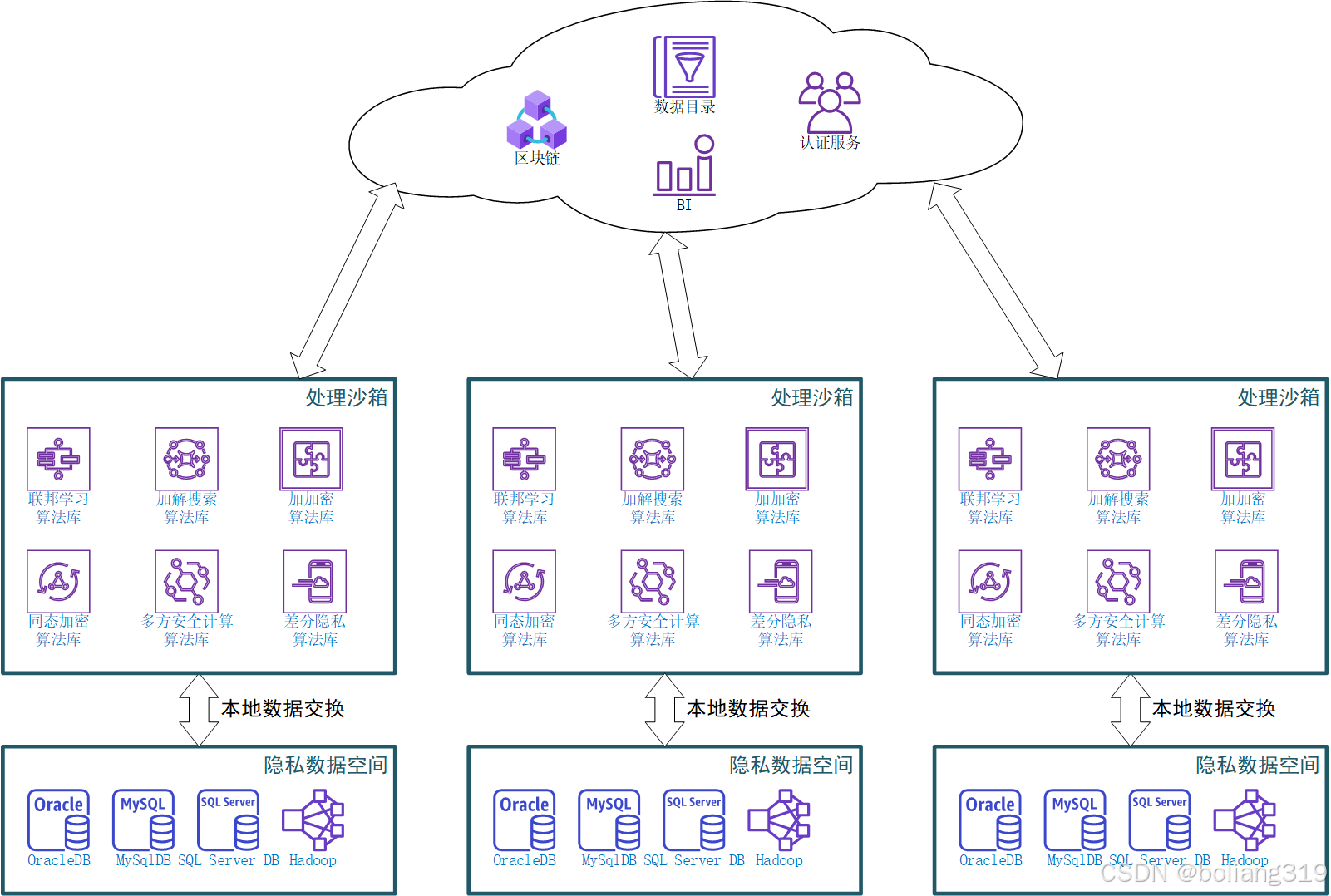
从功能上来说,一套可信数据空间系统,应包括以下几个子模块:数据存储模块、隐私计算模块、数据交易模块、身份认证与权限管理模块。
数据存储模块,可进一步分解成一块逻辑上统一的存储空间(大数据存储系统、数据湖等),一套带有加解密功能的数据访问控制软件,以及一系列用于数据抽取、清洗、加工的数据处理算法库。
隐私计算模块可简单的理解为由各种常见隐私计算算法组成的算法库,包括了用于联邦学习算法。
数据交易模块可以是一套集中式的交易与溯源系统,也可以是一套区块链基础设施,区块链的解决方案采用去中心化的方式实现交易并保证交易的安全和不可篡改,并提供数据溯源的能力。
身份认证与权限管理模块则负责管理用户的账号信息以及权限分配信息。
从硬件的角度来看,承载整套可信数据空间的硬件仍然是传统的网络基础设施、存储系统、服务器与终端PC。如果系统需要支持分布式学习等功能,则还需配备GPU或者NPU等专用加速硬件。

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









