









推荐murphy的工具箱,这篇博客是根据大牛的工具箱使用写一些note
Kevin Murphy 现在在Google brain工作,曾在MIT lab工作,他是 Machine Learning: a Probabilistic Perspective 的作者
他写的关于机器学习的工具箱非常好,规范,注释也多,可供大家学习
https://www.cs.ubc.ca/~murphyk/Software/HMM/hmm.html
一、GMM toolbox的一些使用
温故而知新啊,乘着新冠病毒有时间,在家复习一下
GMM toolbox的几个公式
下载 https://www2.aston.ac.uk/eas/research/groups/ncrg/resources/netlab/downloads
说明文档http://cseweb.ucsd.edu/~mdailey/netlab-help/
1、初始化定义
mix = gmm(dim, ncentres, covar_type)
dim 维度,ncentres 混几个Gaussian,协方差矩阵
mix = gmm(2, 4, 'spherical');‘spherical’,协方差矩阵是全1,stored as a vector
‘diag’对角,full 全对称阵列
'spherical' = single variance parameter for each component: stored as a vector
'diag' = diagonal matrix for each component: stored as rows of a matrix
'full' = full matrix for each component: stored as 3d array2、Sample from a Gaussian mixture distribution
data = gmmsamp(mix, n)
给定模型,产生n个观测数据
3、Computes the activations of a Gaussian mixture model.
a = gmmactiv(mix, x) 它计算的是每个GMM 模型产生 观测值x得概率p(x|j),有几个Gauss出概率序列,也就是vector的长度
4、Computes the class posterior probabilities of a Gaussian mixture model.
post = gmmpost(mix, x) 计算后验概率
给定观测x,计算每个Gauss 的输出概率,p(j|x)
the probability of each component conditioned on the data p(j|x)
5、计算概率
Computes the data probability for a Gaussian mixture model.
function prob = gmmprob(mix, x)这是计算由一个混合高斯,注意是混合高斯和 上面的3 不一样,上面3是几个单高斯算出来概率成vector,
这里面是几个按照权重求和
6、使用一个数据集初始化一个GMM模型
mix = gmminit(mix, x, options)7、EM algorithm for Gaussian mixture model.
[mix, options, errlog] = gmmem(mix, x, options)尝试用他们做简单的几个实验:
%定义一个GMM模型
% mix.priors 会是平均数,mix.centres 和 mix.covars 是随机数
% mix.nwts 说的是一共有多少自由度
mix = gmm(2, 4, 'full');%2维度,混合4个GMM
%产生观测数据
data = gmmsamp(mix, 50);
%对mix求一下后验概率 P(j|x)
x = data;
post = gmmpost(mix, x);
% 玩一会全概率和后验概率吧
% P(x) = sumj( P(j)*P(x|j)); %全概率,j是代表GMM中的第j的单Gauss,x是观测序列
% P(j|x) = P(x|j)*P(j) / P(x); %后验概率
a = gmmactiv(mix, x); %a就是 P(x|j)
Px = sum(a .* mix.priors,2); % x产生的概率 P(x)
post1 = (a .* mix.priors) ./ Px; %也就是post,自己对比一下
% 用上面给的data训练一个GMM模型吧
x = data;
options = zeros(1,14);
options(5) = 1 ;%是否用kmeans
mix = gmminit(mix, x, options);
% Set up vector of options for EM trainer
options = zeros(1, 18);
options(1) = 1; % -1什么都不输出.
options(14) = 10; % 循环次数.
[mix, options, errlog] = gmmem(mix, x, options);
二、 HMM 相关公式和函数使用说明




注意 这两个别搞混淆了![]() 和
和![]()
后向概率的发射观测是下一个状态的
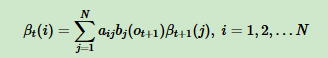
所以![]() 中的bj(Ot+1)并不奇怪了,因为alpha_t(i)中 含有的是bi(Ot)
中的bj(Ot+1)并不奇怪了,因为alpha_t(i)中 含有的是bi(Ot)
而beta_t+1(j)中含有的是 bj(Ot+2)
回到HMM 工具箱,有两个概念
MOG:Mixture of Gaussian-------连续性HMM
The partially observable Markov decision process (POMDP)-----离散型HMM
前后向算法函数使用:
obslik = multinomial_prob(data, B);%obslik 是某个观测序列对发射矩阵的挑出,按时间来的
[alpha, beta, gamma, loglik,xi_summed] = fwdback(pi, A, obslik ,'scaled',0); %完整的前后向算法
alpha beta不用说了,就是前后向算法,loglik是给定的观测序列data在五元组下面的概率,最后是以log的方式给出的
scaled 应该是要归一化,alpha在每个时刻下,对每个状态的概率之和应该是1,beta也应该一样
给定模型 和某个观测序列,gamma说的意思是,在t时刻处于状态S的概率
gamma(t,S)
gamma(:,1) = normalise(alpha(:,1) .* beta(:,1));
gamma(:,2) = normalise(alpha(:,2) .* beta(:,2));
xi_summed说的是 给定模型和观测序列,每个时刻下,从i状态到j状态的概率,他是Q*Q维阵列 (Q是状态个数,O是发射出来的观测值得个数,离散型HMM)
而xi_summed是每个时刻点的这些矩阵的和
三、两种HMM的训练方法:
1、一种是常见的BW算法,它需要算 两个统计量,一个是
ξt(i,j) 表示给定观测序列,在t时刻处于状态Si,t+1时刻处于Sj的概率
gamma(t,i) 表示给定观测序列,在t时刻处于状态Si的概率

BW算法之后的重估公式:,下面的D是多少个观测序列,转移Pi 是 t=1时刻的

2 第二种是Viterbi training方法:
viterbi training的算法,它是一种 观测序列 hard decisions of某个 状态
而BW算法是soft decisions
http://liacs.leidenuniv.nl/~bakkerem2/cmb2017/CMB2017_Lecture10_08continued.pdf
Viterbi training的一个流程

https://nlp.stanford.edu/courses/lsa352/lsa352.lec7.6up.pdf



Viterbi training 的一些特点
1、Much faster than Baum-Welch
2、But doesn’t work quite as well
3、But the tradeoff is often worth it.

viterbi training 的好处是一种硬分类(所以为啥叫force alignment),收敛速度比BW算法要快,但往往不是很准确,另外是硬分,所以有些状态通过计数,是出不来的!所以它计算出来的转移矩阵,发射矩阵,居然有些部分是0,这时候要用laplace 矫正,laplace correction, laplace training 等
但这种方法用在 语音识别的 HMM 前后连接的 HMM结构是可以的它本身就是很多为零
A = [0.8 0.2 0 ...
0 0.8 0.2 0...]
这种方法y用在 DNN HMM好,可以很快知道某个观测序列属于哪个状态,也就是b(O)
DNN-HMM,需要一个GMM-HMM做铺垫,它的目的不是为了求b(O),是为了快速force alignment,之后通过前后3帧联合,后面再得到soft的属于哪一个状态的b(O)
DNN-HMM中的DNN 主要是就是 发射矩阵的估计,DNN应该能模拟非线性的pdf,强于GMM模型
四、协方差矩阵的含义复习
记录一下协方差的含义:
协方差矩阵不是正定矩阵,实在的,它其实是半正定矩阵,也就是说有det(A)=0的时候
协方差矩阵,对角线上是各个维度自己的方差,其他地方则是 互相关元素
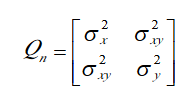


没什么好说的,是除以 N-1
http://www.inf.ed.ac.uk/teaching/courses/inf2b/learnnotes/inf2b-learn-note08-2up.pdf

多维Gauss
这里面有协方差矩阵分母上是N还是N-1的问题

这里的参数估计是除以 N

至于为什么是除以N不是除以N-1,这里有解释
https://www.visiondummy.com/2014/03/divide-variance-n-1/
Conclusion
In this article, we showed where the usual formulas for calculating the mean and the variance of normally distributed data come from. Furthermore, we have proven that the normalization factor in the variance estimator formula should be if the true mean of the population is known, and should be
if the mean itself also has to be estimated.
如果是均值u已经正确估计了,那么就用N-1,我们在计算方差之前,基本先求出来了均值,所以用N-1,
如果均值也不知道是否正确估计了,那么用N
多维高斯,,如果使用full,其实是多维矢量,算协方差矩阵,使用多维高斯求概率
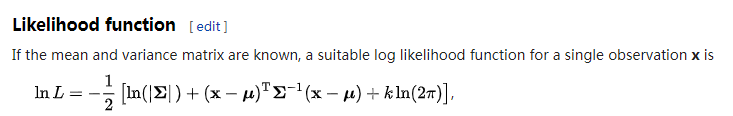
如果是diag的,使用diag, 实际上协方差是每个维度自己算方差
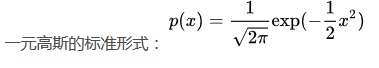 ,然后多个维度的概率相乘
,然后多个维度的概率相乘
matlab中mvnpdf和normpdf的区别
多维正态分布mvnpdf,
一维正态分布normpdf:但是要注意入口参数 西格玛 是平方
协方差矩阵的求法
netlab中的HMM-GMM的协方差有两种 diag 和full 两种分别说的是主对角线有元素,其他地方全是零,而full则是全部都有元素
他们的matlab代码如下:
data是个数*维度,或者说,单个样本是行向量
mu = mean(data,1);
diffs = data - (ones(size(data, 1), 1) * mu);
%'diag'
Sigma = sum((diffs.*diffs), 1)/size(data, 1);%注意这里面已经有平方了
%'full'
%Sigma = (diffs'*diffs)/size(data, 1);
diag是相当于特征中的每个维内部自己计算均值和方差(多个单高斯的组合),
而full则是协方差,它探求的是各个维度之间的关系(什么关系,见下图二维高斯图)
diag算出来的值就是full中主对角线的值
他们的几何含义:https://www.cnblogs.com/cloud-ken/p/9629539.html

投影为1、 圆 2、y轴投影长,3、归一化后y轴投影长,4、右旋转,5、左旋转
六,一个小问题
前向算法和维特比解码都有概率有什么区别?
先看定义:
前向算法
知道HMM的参数 λ = (A, B, π) 和观测序列O = {o1,o2, ..., oT} ,如何计算模型 λ 下观测序列O出现的概率P(O | λ)。
viterbi解码:
知道HMM的参数 λ = (A, B, π) 和观测序列O = {o1,o2, ..., oT},如何计算给定观测序列条件概率P(I|O, λ )最大的状态序列I
有差别,差别在哪里?前向算法是给定模型和观测序列,算出所有可能的状态路径都能发射出来O的所有的概率之和
Viterbi是这里面概率最大的一条路径,一个是所有的概率之和。一个是最大概率的路径















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









