







目录
1. 基于孤立词的GMM-HMM语音识别系统
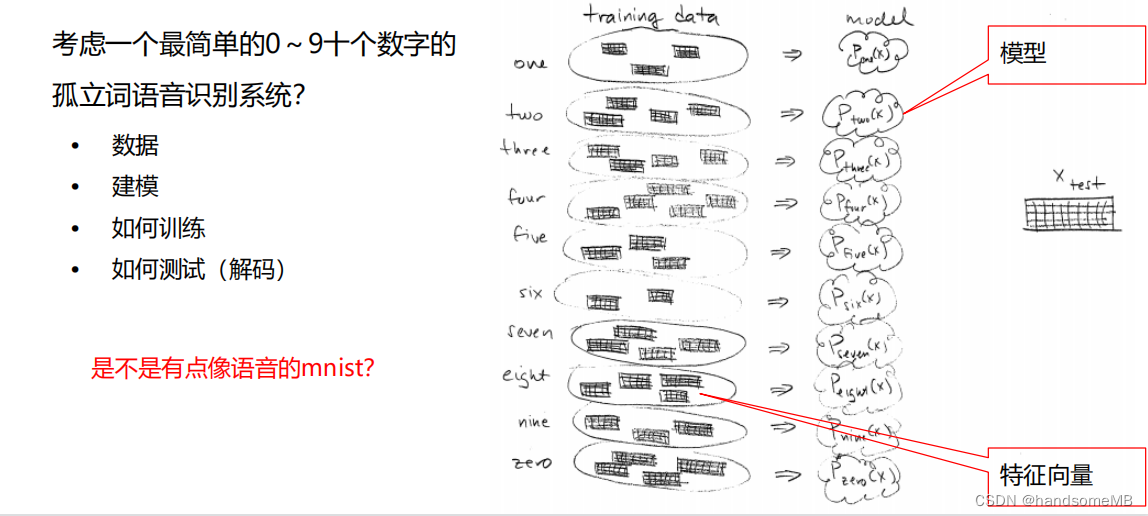
目标:

建模:

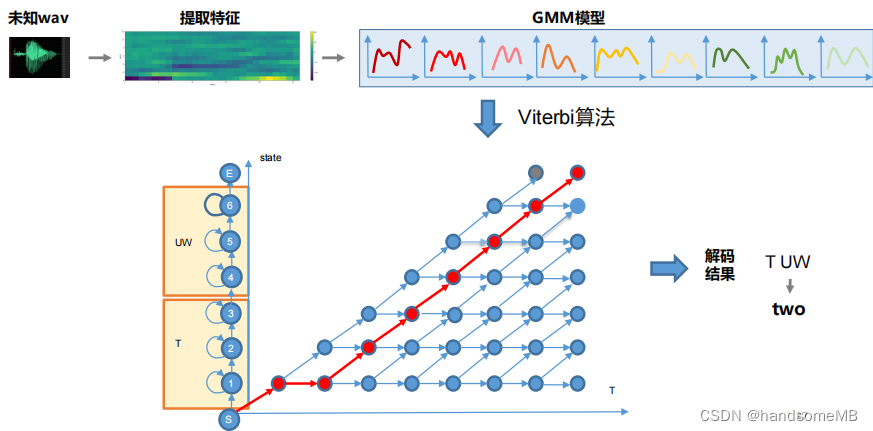
GMM-HMM语音识别系统流程(孤立词):
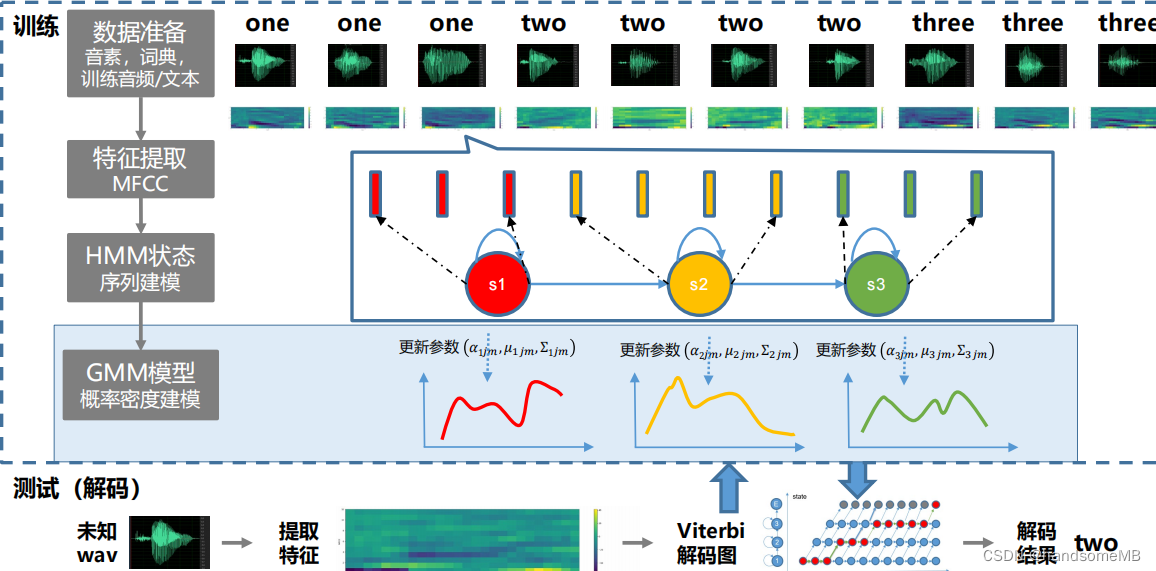
a. 训练(前向后向训练/Viterbi训练)


Viterbi训练
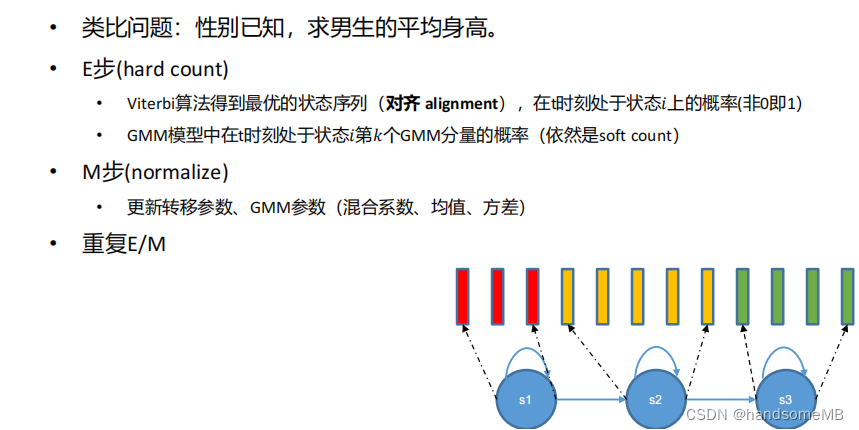

前向后向训练(Baum-Welch训练)


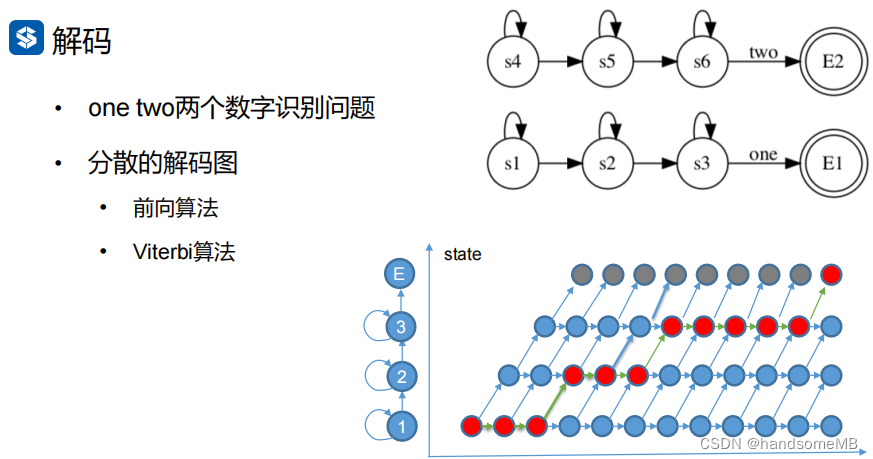
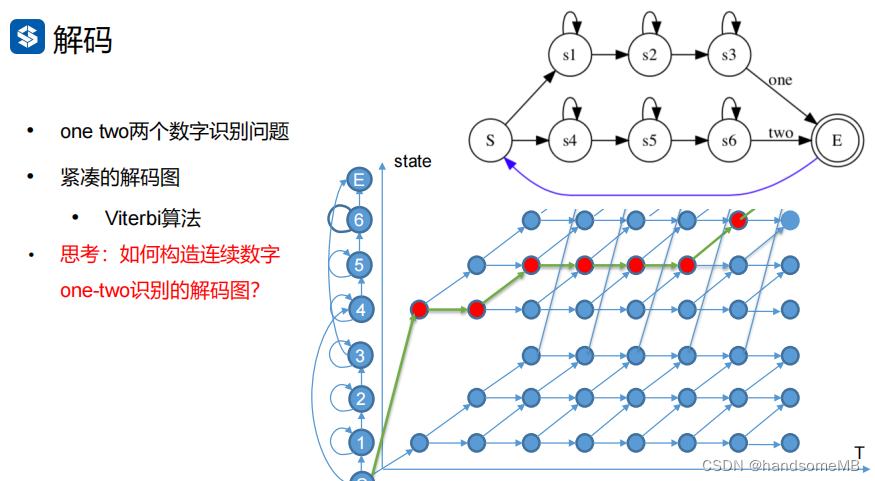
b. 解码

2. 基于单音素的GMM-HMM语音识别系统

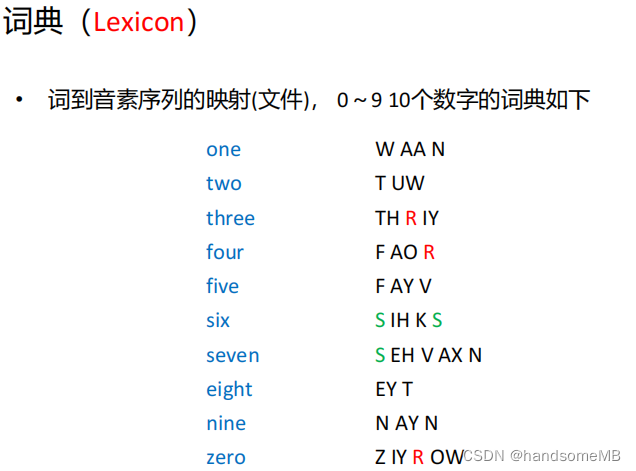
a. 音素/词典

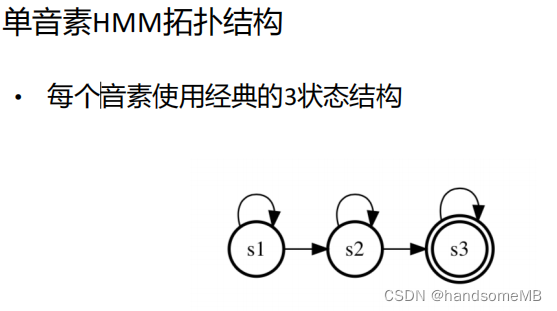
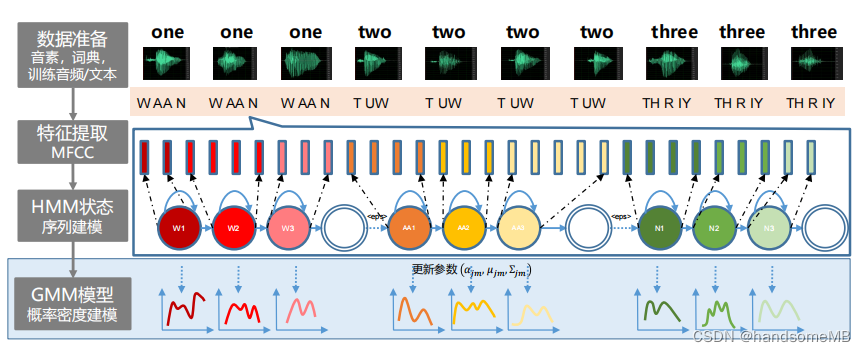
b. 训练
c. 解码

3. 基于三音素的GMM-HMM语音识别系统

a. 三音素


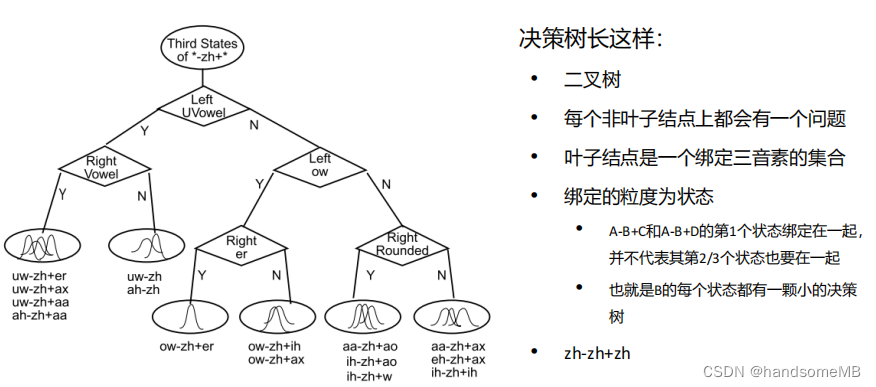
b. 决策树
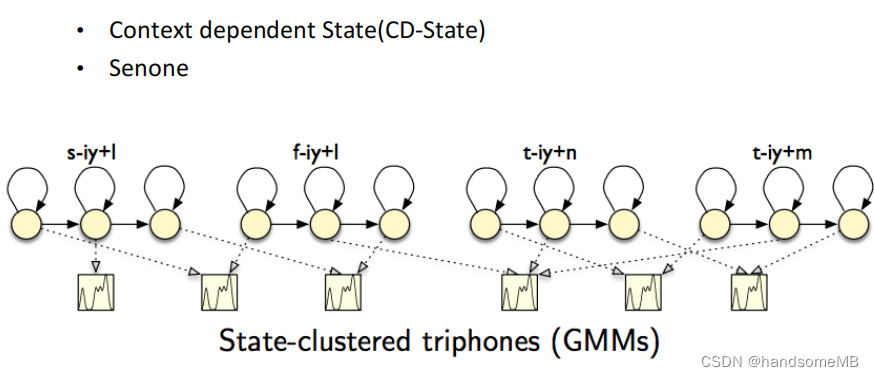


c. 训练
d. 解码
4. 基于GMM-HMM语音识别系统流程


5. 总结
第五章讲述了如何构建语音识别系统,是对前四章知识的总结与应用,应将上节的两个学习算法与本节的知识理解清楚。
6. 作业代码
待完善

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









