







一、未使用Dropout的正常情况下
在4.交叉熵的代码的网络模型构建中添加一些隐藏层,并且输出训练集的损失和准确率。
将4.交叉熵中的
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是10 输入是784,设置偏置为1,添加softmax激活函数
Dense(units=10,input_dim=784,bias_initializer='one',activation="softmax"),
])
添加隐藏层修改为:
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh"),
Dense(units=10,bias_initializer='one',activation="softmax")
])
代码运行结果:
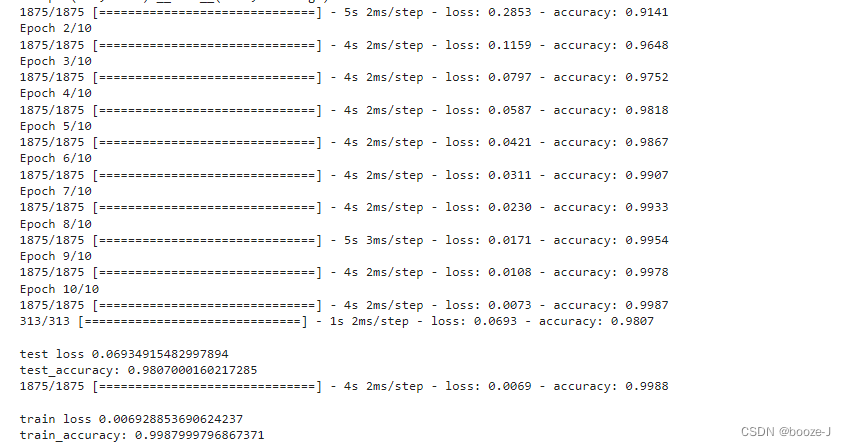
对比4.交叉熵的运行结果,可以发现添加更多隐藏层之后,模型测试的准确率大大提高,但是却出现了轻微的过拟合现象。
二、使用Dropout
在模型构建中添加Dropout:
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# 让40%的神经元不工作
Dropout(0.4),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh"),
# 让40%的神经元不工作
Dropout(0.4),
Dense(units=10,bias_initializer='one',activation="softmax")
])
使用Dropout之前需要先导入from keras.layers import Dropout
运行结果:
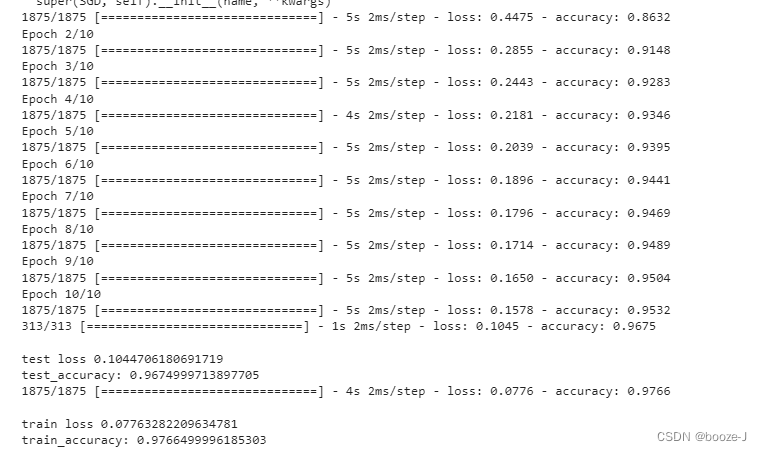
在这个例子中并不是说使用dropout会得到更好的效果,但是有些情况下,使用dropout是可以得到更好的效果。
但是使用dropout之后,测试准确率和训练准确率还是比较接近的,过拟合现象不是很明显。从训练结果中可以看到,训练过程中的准确率都低于最终模型测试训练集的准确率,这是因为使用dropout之后,每次训练都只是使用部分神经元进行训练,然后模型训练完之后,最后测试的时候,是使用所有神经元进行测试的,所以效果会更好。
完整代码
1.未使用Dropout情况的完整代码
代码运行平台为jupyter-notebook,文章中的代码块,也是按照jupyter-notebook中的划分顺序进行书写的,运行文章代码,直接分单元粘入到jupyter-notebook即可。
1.导入第三方库
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Dropout
from tensorflow.keras.optimizers import SGD
2.加载数据及数据预处理
# 载入数据
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) 还未进行one-hot编码 需要后面自己操作
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape()中参数填入-1的话可以自动计算出参数结果 除以255.0是为了归一化
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# 换one hot格式
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3.训练模型
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh"),
Dense(units=10,bias_initializer='one',activation="softmax")
])
# 定义优化器
sgd = SGD(lr=0.2)
# 定义优化器,loss_function,训练过程中计算准确率
model.compile(
optimizer=sgd,
loss="categorical_crossentropy",
metrics=['accuracy']
)
# 训练模型
model.fit(x_train,y_train,batch_size=32,epochs=10)
# 评估模型
# 测试集的loss和准确率
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("test_accuracy:",accuracy)
# 训练集的loss和准确率
loss,accuracy = model.evaluate(x_train,y_train)
print("\ntrain loss",loss)
print("train_accuracy:",accuracy)
2.使用Dropout的完整代码
代码运行平台为jupyter-notebook,文章中的代码块,也是按照jupyter-notebook中的划分顺序进行书写的,运行文章代码,直接分单元粘入到jupyter-notebook即可。
1.导入第三方库
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Dropout
from tensorflow.keras.optimizers import SGD
2.加载数据及数据预处理
# 载入数据
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) 还未进行one-hot编码 需要后面自己操作
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape()中参数填入-1的话可以自动计算出参数结果 除以255.0是为了归一化
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# 换one hot格式
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3.训练模型
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# 让40%的神经元不工作
Dropout(0.4),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh"),
# 让40%的神经元不工作
Dropout(0.4),
Dense(units=10,bias_initializer='one',activation="softmax")
])
# 定义优化器
sgd = SGD(lr=0.2)
# 定义优化器,loss_function,训练过程中计算准确率
model.compile(
optimizer=sgd,
loss="categorical_crossentropy",
metrics=['accuracy']
)
# 训练模型
model.fit(x_train,y_train,batch_size=32,epochs=10)
# 评估模型
# 测试集的loss和准确率
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("test_accuracy:",accuracy)
# 训练集的loss和准确率
loss,accuracy = model.evaluate(x_train,y_train)
print("\ntrain loss",loss)
print("train_accuracy:",accuracy)
















 7232
7232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











