






本文参考XTuner 微调 Llama3 图片理解多模态,感谢机智流提供的学习教程,感谢书生浦语提供的免费算力!
准备环境
ps: 在开始之前,请先清理下磁盘空间,删除不需要的文件。否则会因为占用空间过大而丢失数据。如果已经有环境,也可以直接使用,如果提示module不存在,请尝试使用conda install,如果安装失败那就用pip install,总会成功的!
安装python环境
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia安装XTuner
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .[all]下载教程代码
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial准备模型
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct .准备VisualEncoder
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/openai/clip-vit-large-patch14-336 .准备ImageProjector
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/xtuner/llama3-llava-iter_2181.pth .准备微调数据
大佬们都已经准备好了数据,直接拿来用Tutorial/xtuner/llava/xtuner_llava.md at camp2 · InternLM/Tutorial · GitHub 中的教程来准备微调数据。只是为了学习微调过程,准备的数据单一,因此微调完以后也是过拟合的,只能回答单一的问题。
cd ~
git clone https://github.com/InternLM/tutorial -b camp2
python ~/tutorial/xtuner/llava/llava_data/repeat.py \
-i ~/tutorial/xtuner/llava/llava_data/unique_data.json \
-o ~/tutorial/xtuner/llava/llava_data/repeated_data.json \
-n 200数据格式
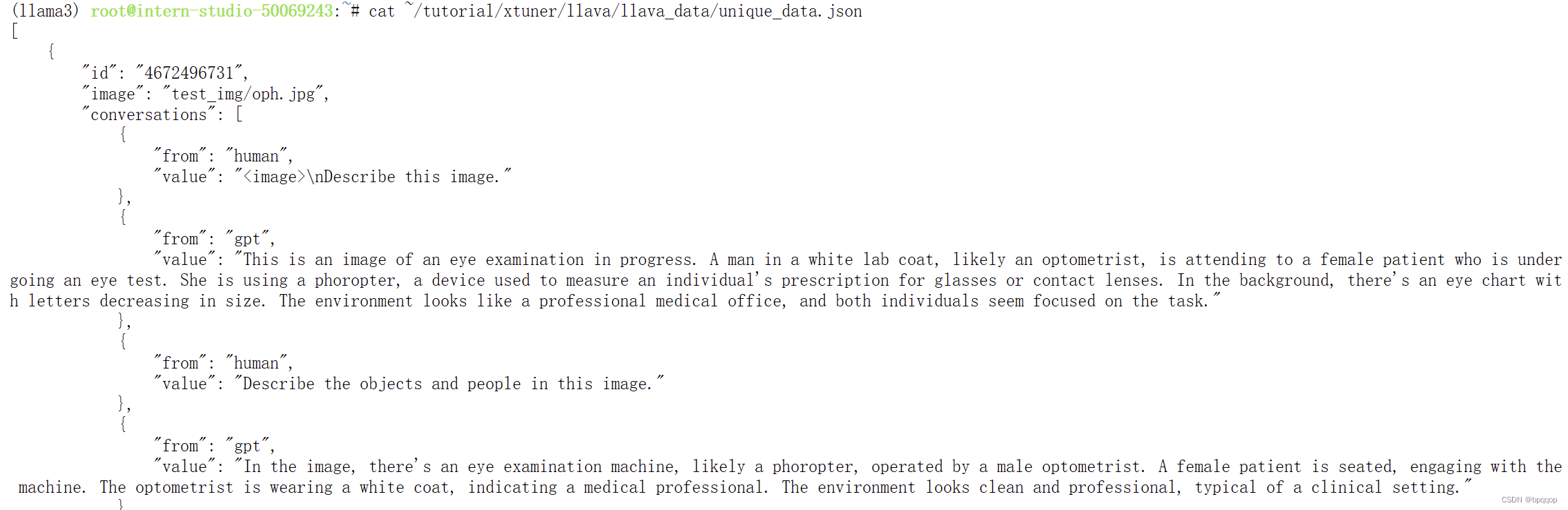
微调过程
启动训练
教程中已经提供了配置,根据不同的配置选择运行命令,如果你的配置只有A100 30% 24G显存,请使用使用以下命令,否则会oom,参数--deepspeed deepspeed_zero2_offload的区别
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2_offload如果你有更高的配置,可以使用一下命令
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2可以看到,微调过过程很慢,A100 30% 24G显存大概需要4小时40分钟!!

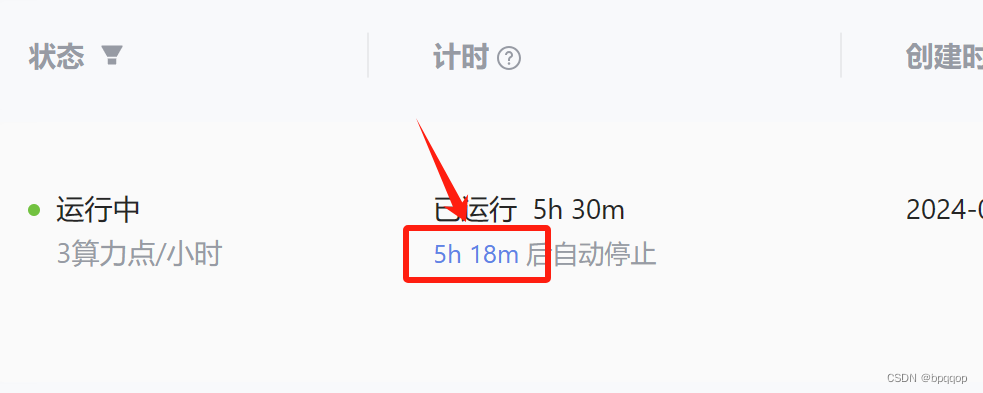
正常情况下算力点用完会自动添加,如果没有自动添加可以在学习群里找助教添加。加完点之后记得回到开发机列表,点击计时列的时间,延长开发机时间!
如果提示oom,可以参考以下方法:

- 使用https://github.com/SmartFlowAI/Llama3-Tutorial/blob/main/tools/internstudio_quant_web_demo.py,原来是 streamlit run internstudio_web_demo.py xxxx,现在是 streamlit run internstudio_quant_web_demo.py xxxxx
- 添加指令--device cpu,以使用cpu运行指令;
- 添加指令--deepspeed deepspeed_zero2,或者--deepspeed deepspeed_zero2_offload(在配置环境时须在xtuner目录下执行指令pip install '.[all]')
训练过程中可能会因为磁盘空间不够,而丢失数据,关注短信和邮箱,删除不必要的文件。
经过漫长的等待,终于迎来了完成的曙光
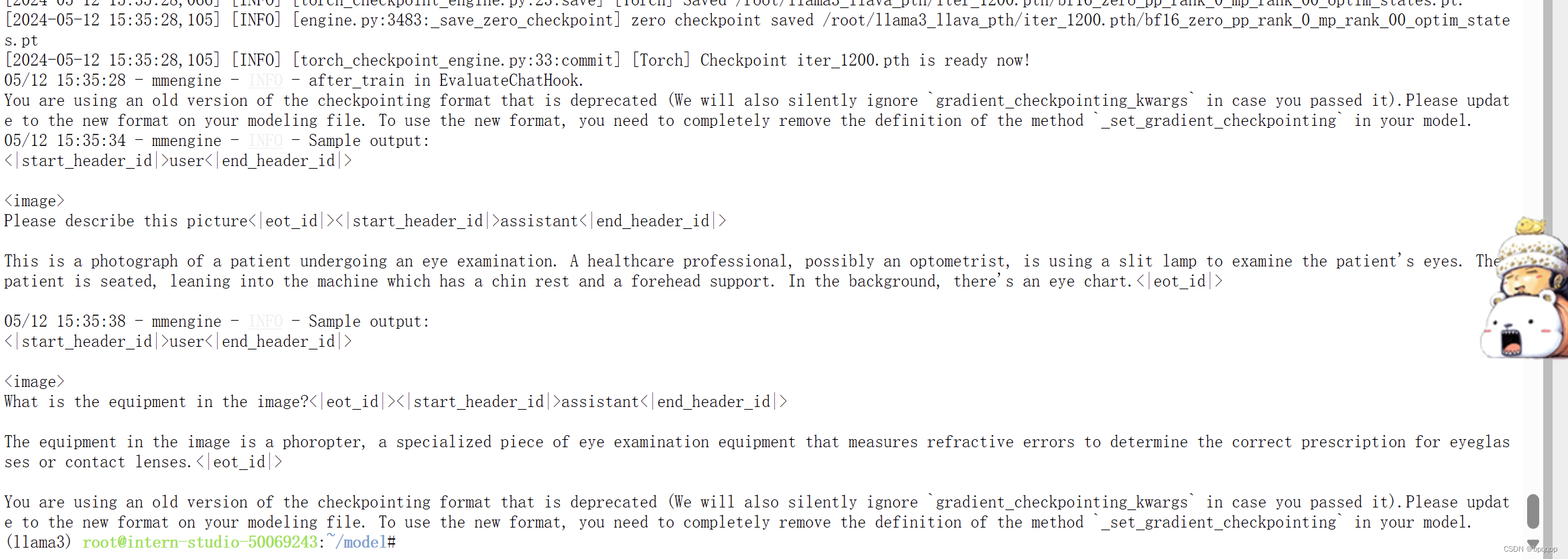
格式转换
训练好后,将原始的image projector和微调后的image projector转换为HF格式
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
~/model/llama3-llava-iter_2181.pth \
~/llama3_llava_pth/pretrain_iter_2181_hf
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
~/llama3_llava_pth/iter_1200.pth \
~/llama3_llava_pth/iter_1200_hf不经转换直接运行会提示以下错误

体验效果:
原始图片
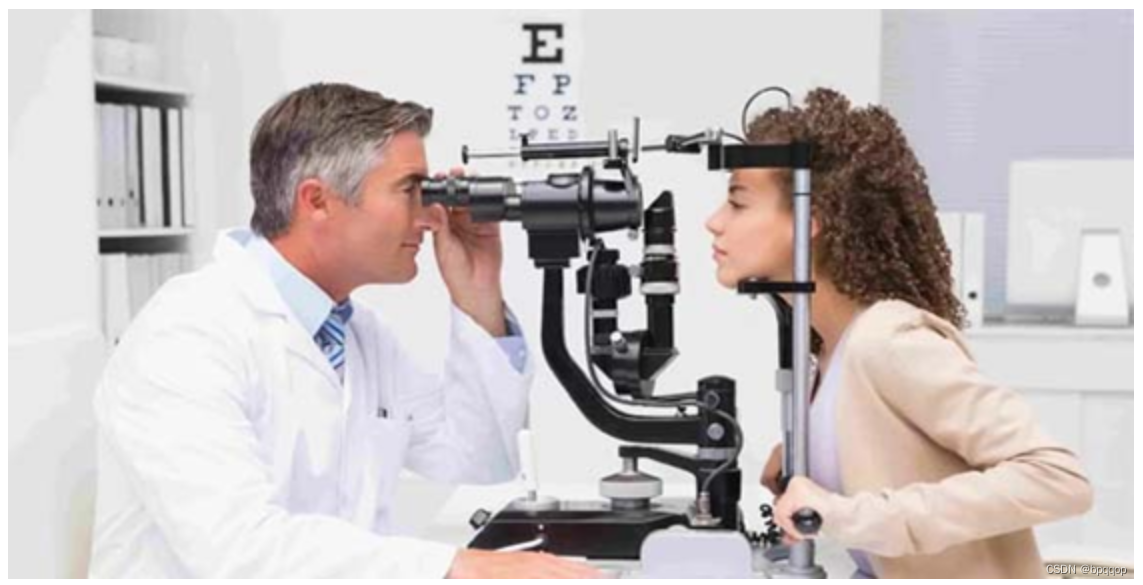
问题1:Describe this image. 问题2:What is the equipment in the image?
运行原始模型
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
--visual-encoder /root/model/clip-vit-large-patch14-336 \
--llava /root/llama3_llava_pth/pretrain_iter_2181_hf \
--prompt-template llama3_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg效果:
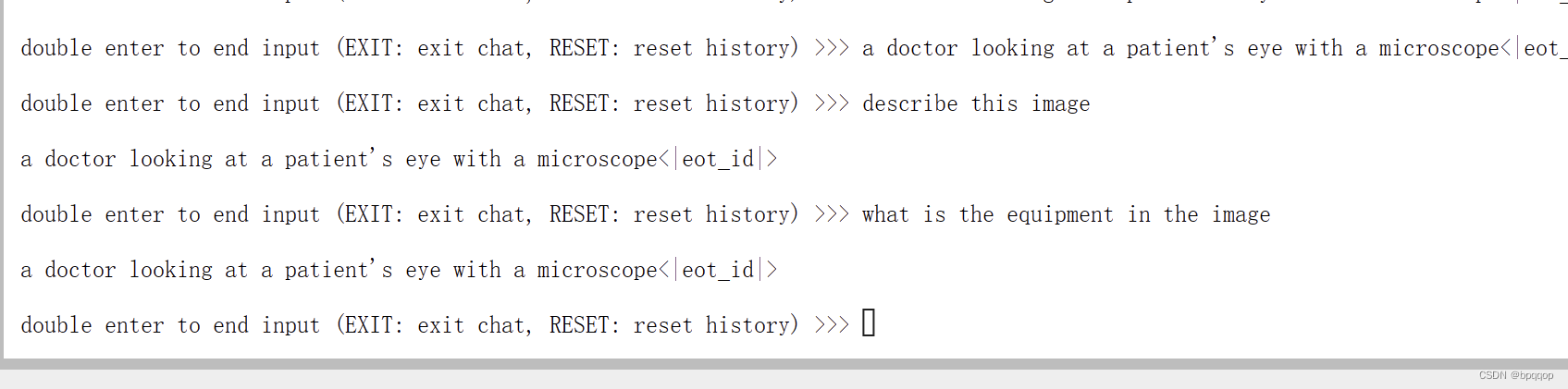
此时可以看到,Pretrain 模型只会为图片打标签,并不能回答问题。
运行微调后的模型
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
--visual-encoder /root/model/clip-vit-large-patch14-336 \
--llava /root/llama3_llava_pth/iter_1200_hf \
--prompt-template llama3_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg效果:

经过 Finetune 后,模型已经可以根据图片回答问题了。当然现在还是过拟合状态。

最后
书生浦语大模型实战营开班了!免费学习,提供免费算力支持,扫码报名!


















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









