







论文地址:https://arxiv.org/abs/2103.14030
一、简介
在计算机视觉建模中,长期以来都是 CNN \text{CNN} CNN占据主导地位。从 AlexNet \text{AlexNet} AlexNet和其在 ImageNet \text{ImageNet} ImageNet图像分类任务上的革命性表现开始, CNN \text{CNN} CNN的架构更大的规模、更广泛的连接和更复杂的卷积形式进化的越来越强大。随着 CNNs \text{CNNs} CNNs作为各种视觉任务的骨干网络,这些架构的改善为整个领域带来了性能的提升。
另一方面,自然语言处理中的网络架构则采取了不同的路线,如今的流行架构为 Transformer \text{Transformer} Transformer。 Transformer \text{Transformer} Transformer是为序列建模和迁移任务设计的,其显著之处在于能够对数据中的远程依赖进行建模。在语言领域中的巨大成功令研究人员尝试将其应用在计算机视觉中,其近期已经在图像分类和视觉语言联合模型上都显示了非常好的效果。
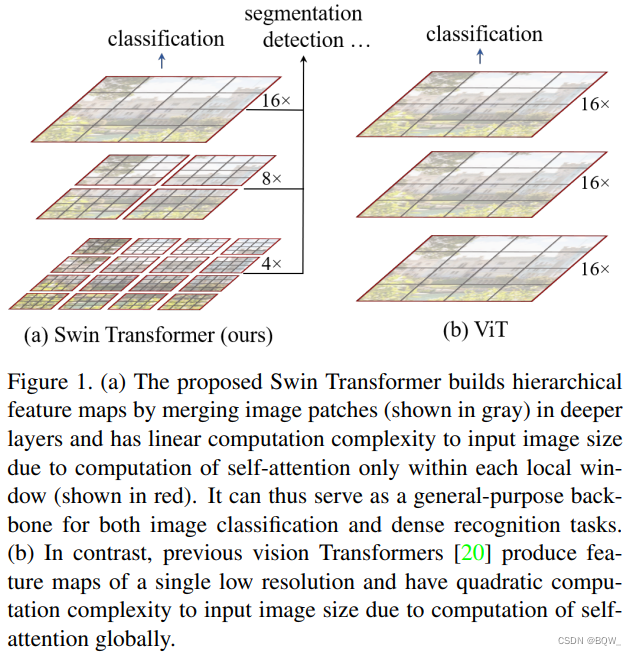
在本文中,作者尝试扩展 Transformer \text{Transformer} Transformer的适用性,使其可以作为计算机视觉的主干网络,就像其在 NLP \text{NLP} NLP和 CNN \text{CNN} CNN在计算机视觉中那样。作者观察到,将语言上的优良表现迁移至视觉领域的重要挑战可以通过两个模态间的区别来解释。其中一个区别是规模。不同于单词token,其可以在语言 Transformer \text{Transformer} Transformer中作为基础元素被处理,而视觉元素在规模上的差异特别大,特别是在目标检测任务中需要被注意。在现有的基于 Transformer \text{Transformer} Transformer的模型中,所有的token规模都是固定的,这并不适合视觉应用。另一个区别是图像中像素的分辨率比文本段落中单词高很多。许多视觉任务,如语义分割,需要在像素级别进行稠密预测。高分辨率图像对于 Transformer \text{Transformer} Transformer来说是棘手的,自注意力计算复杂度是图像尺寸的平方。为了解决这些问题,作者提出了一种称为 Swin Transformer \text{Swin Transformer} Swin Transformer的通用 Transformer \text{Transformer} Transformer,其构造层次 feature map \text{feature map} feature map并且拥有图像尺寸的线性复杂度。如上图(a)中, Swin Transformer \text{Swin Transformer} Swin Transformer通过从小尺寸 patch \text{patch} patch开始并逐步合并相邻的 patch \text{patch} patch,从而构建一个层次表示。基于这些层次 feature map \text{feature map} feature map, Swin Transformer \text{Swin Transformer} Swin Transformer能够方便的利用先进的技术进行稠密预测,例如 FPN \text{FPN} FPN和 U-Net \text{U-Net} U-Net。通过将图像分割为非重叠窗口来计算局部自注意力机制,从而实现了线性复杂度。每个窗口中的 patch \text{patch} patch数量是固定的,其计算复杂度是图像尺寸的线性规模。这些优点使 Swin Transformer \text{Swin Transformer} Swin Transformer适合作为各种视觉任务的主干网络。
Swin Transformer \text{Swin Transformer} Swin Transformer的关键设计元素是连续自注意力层间的滑动窗口划分。滑动窗口链接了前一层的窗口,通过在它们之间提供链接来极大的改善模型的建模能力。 Swin Transformer \text{Swin Transformer} Swin Transformer在图像分类、目标检测和语义分割等任务上取得了良好的性能。其在三个任务上显著的优于 ViT/DeiT \text{ViT/DeiT} ViT/DeiT和 ResNe(X)t \text{ResNe(X)t} ResNe(X)t。
二、 Swin \text{Swin} Swin
1. 整体架构
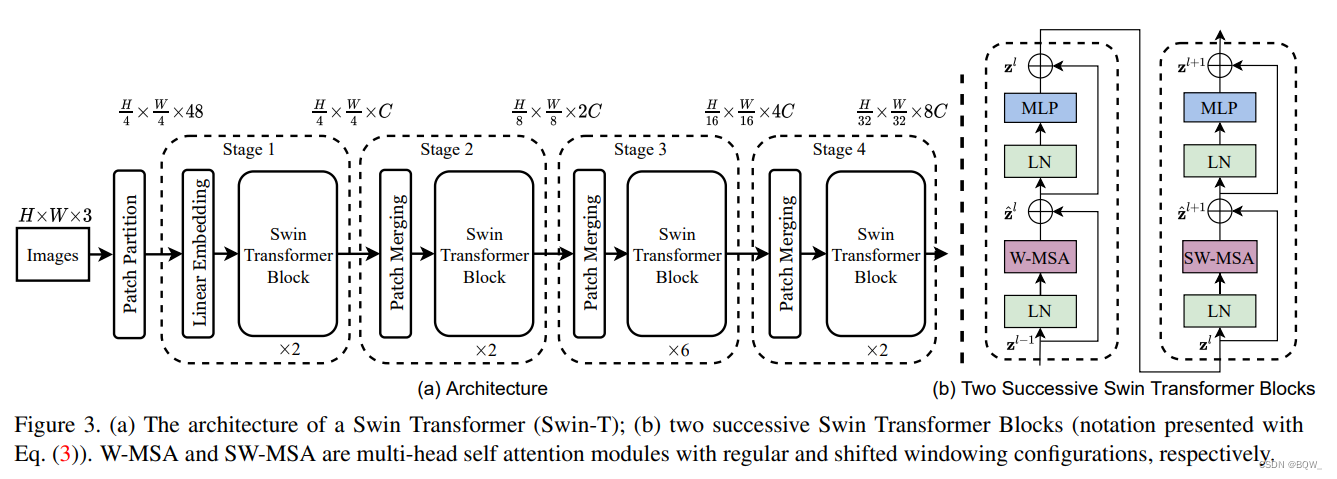
上图是一个 tiny \text{tiny} tiny版本的 Swin Transformer \text{Swin Transformer} Swin Transformer架构。该模型会通过 patch \text{patch} patch划分模块将 RGB \text{RGB} RGB图像划分为不重叠的 patches \text{patches} patches,类似于 ViT \text{ViT} ViT。每个 patch \text{patch} patch被当做一个"token", patch \text{patch} patch的特征被设置为原始像素 RGB \text{RGB} RGB值的拼接。在具体实现中,使用 4 × 4 4\times 4 4×4的 patch size \text{patch size} patch size且每个 patch \text{patch} patch的特征维度为 4 × 4 × 3 = 48 4\times 4\times 3=48 4×4×3=48。使用一个线性embedding层将原始特征投影至一个任意维度,记为 C \text{C} C。
将若干个具有改进自注意力的
Transformer
\text{Transformer}
Transformer块(
Swin Transformer
\text{Swin Transformer}
Swin Transformer块)应用在这些
patch tokens
\text{patch tokens}
patch tokens。这些
Transformer
\text{Transformer}
Transformer块会维护
(
H
4
×
W
4
)
(\frac{H}{4}\times\frac{W}{4})
(4H×4W)个token,并且该层和线性嵌入层一起统称为阶段一。
为了能够产生一个层次表示,随着网络变的更深,token数量会通过一个
path merging
\text{path merging}
path merging层进行缩减。第一个
patch merging
\text{patch merging}
patch merging层会拼接
2
×
2
2\times2
2×2个相邻的
patch
\text{patch}
patch特征,并在合并后的
4
C
4C
4C维度特征上应用一个线性层。这会导致token的数量减少到
2
×
2
=
4
2\times 2=4
2×2=4倍,并将输出维度设置为
2
C
2C
2C。将
Swin Transformer
\text{Swin Transformer}
Swin Transformer块应用在特征上进行特征转换,分辨率保持为
H
8
×
W
8
\frac{H}{8}\times\frac{W}{8}
8H×8W。
patch merging
\text{patch merging}
patch merging层和特征传播
Swin Transformer
\text{Swin Transformer}
Swin Transformer块被称为阶段二。该过程被重复两次,分别称为阶段3和阶段4,输出分辨率分别为
H
16
×
W
16
\frac{H}{16}\times\frac{W}{16}
16H×16W和
H
32
×
W
32
\frac{H}{32}\times\frac{W}{32}
32H×32W。这些阶段会产生一个层次表示,具有与
VGG
\text{VGG}
VGG和
ResNet
\text{ResNet}
ResNet这样典型卷积神经网络相同的特征映射分辨率。因此,
Swin Transformer
\text{Swin Transformer}
Swin Transformer可以非常方便的替换现有视觉任务中的backbone。
-
Swin Transformer块
Swin Transformer \text{Swin Transformer} Swin Transformer通过滑动窗口模块来替换 Transformer \text{Transformer} Transformer中的标准多头自注意力机制( MSA \textbf{MSA} MSA),其他部分保持相同。图上图(b)所示, Swin Transformer \text{Swin Transformer} Swin Transformer由一个基于 MSA \text{MSA} MSA的滑动窗口组成,并在其后加一个具有激活函数 GELU \text{GELU} GELU的双层 MLP \text{MLP} MLP。 LayerNorm(LN) \text{LayerNorm(LN)} LayerNorm(LN)层应用在每个 MSA \text{MSA} MSA层和 MLP \text{MLP} MLP层之前,并且在每个模块中都会应用残差链接。
2. 基于自注意力的滑动窗口
将标准 Transformer \text{Transformer} Transformer应用在图像任务中,需要执行全局自注意力机制,每个token与其他所有的token间的关系都需要被计算。这样全局的计算将导致token数量平方的复杂度,这导致其不适合具有大量token的密集预测或者一个高分辨率的视觉任务。
2.1 不重叠窗口的自注意力
为了能够高效建模,提出在局部窗口内计算自注意力。该窗口通过不重叠的方法均匀划分图像。假设每个窗口包含
M
×
M
M\times M
M×M个
patch
\text{patch}
patch,在一个具有
h
×
w
h\times w
h×w个
patch
\text{patch}
patch块图像上的全局
MSA
\text{MSA}
MSA的计算复杂度和基于窗口的计算复杂度为
Ω
(
MSA
)
=
4
h
w
C
2
+
2
(
h
w
)
2
C
(1)
\Omega(\text{MSA})=4hwC^2+2(hw)^2C \tag{1}
Ω(MSA)=4hwC2+2(hw)2C(1)
Ω ( W-MSA ) = 4 h w C 2 + 2 M 2 h w C (2) \Omega(\text{W-MSA})=4hwC^2+2M^2hwC \tag{2} Ω(W-MSA)=4hwC2+2M2hwC(2)
前者时间复杂度是 patch \text{patch} patch数量 h w hw hw的平方;当 M M M固定时,后者的时间复杂度为线性的。当 h w hw hw太大时,全局自注意力机制的负担太大,而基于窗口的自注意力则相对灵活。
2.2 连续块中的滑动窗口划分
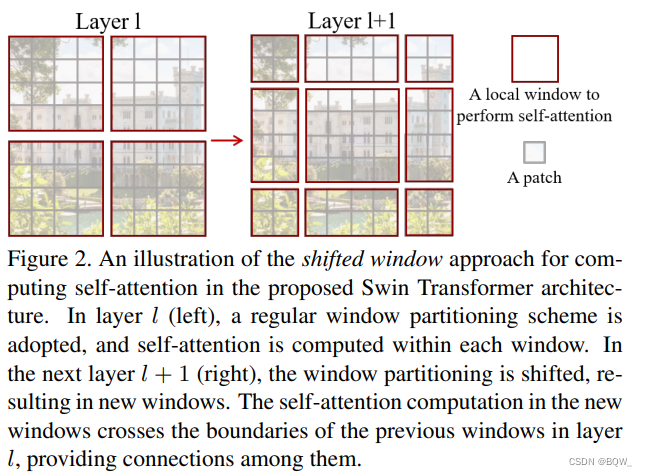
基于窗口的自注意力机制缺乏窗口间的连接,限制了其建模的能力。为了能够在保持无重叠窗口高效计算的同时引入跨窗口连接,本文提出了滑动窗口划分方法。该方法在连续 Swin Transformer \text{Swin Transformer} Swin Transformer块之间交替使用两种划分配置。
如上图说明,第一个模块使用常规的窗口划分策略。划分从左上角开始, 8 × 8 8\times 8 8×8的 feature map \text{feature map} feature map被均等的划分为 2 × 2 2\times 2 2×2个窗口,每个窗口的尺寸为 4 × 4 ( M = 4 ) 4\times 4(M=4) 4×4(M=4)。下一个模块则通过将前一层的常规窗口移动 ( ⌊ M 2 ⌋ , ⌊ M 2 ⌋ ) (\lfloor\frac{M}{2}\rfloor,\lfloor\frac{M}{2}\rfloor) (⌊2M⌋,⌊2M⌋)来获得。
使用滑动窗口划分方法,连续
Swin Transformer
\text{Swin Transformer}
Swin Transformer则计算方式为
z
^
l
=
W-MSA
(
LN
(
z
l
−
1
)
)
+
z
l
−
1
z
l
=
MLP
(
LN
(
z
^
l
)
)
+
z
^
l
z
^
l
+
1
=
SW-MSA
(
LN
(
z
l
)
)
+
z
l
z
l
+
1
=
MLP
(
LN
(
z
^
l
+
1
)
)
+
z
^
l
+
1
(3)
\hat{\textbf{z}}^l=\text{W-MSA}(\text{LN}(\textbf{z}^{l-1}))+\textbf{z}^{l-1} \\ \textbf{z}^l=\text{MLP}(\text{LN}(\hat{\textbf{z}}^l))+\hat{\textbf{z}}^l \\ \hat{\textbf{z}}^{l+1}=\text{SW-MSA}(\text{LN}(\textbf{z}^{l}))+\textbf{z}^{l} \\ \textbf{z}^{l+1}=\text{MLP}(\text{LN}(\hat{\textbf{z}}^{l+1}))+\hat{\textbf{z}}^{l+1} \tag{3}
z^l=W-MSA(LN(zl−1))+zl−1zl=MLP(LN(z^l))+z^lz^l+1=SW-MSA(LN(zl))+zlzl+1=MLP(LN(z^l+1))+z^l+1(3)
其中,
z
^
l
\hat{\textbf{z}}^l
z^l和
z
l
\textbf{z}^l
zl表示在块
l
\text{l}
l中
(S)W-MSA
\text{(S)W-MSA}
(S)W-MSA模块的输出特征和
MLP
\text{MLP}
MLP的输出特征。
W-MAS
\text{W-MAS}
W-MAS和
SW-MSA
\text{SW-MSA}
SW-MSA表示使用常规和滑动窗口划分配置的多头注意力机制。
2.3 滑动窗口的高效计算
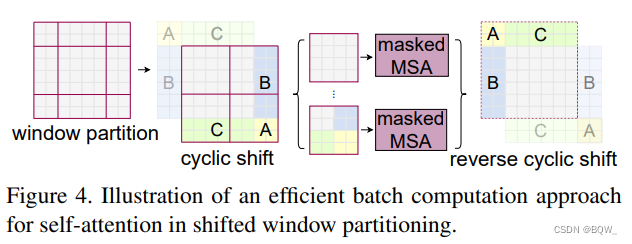
滑动窗口划分会导致更多的窗口,即窗口数量从 ⌈ h M ⌉ × ⌈ w M ⌉ \lceil\frac{h}{M}\rceil\times\lceil\frac{w}{M}\rceil ⌈Mh⌉×⌈Mw⌉增加到 ( ⌈ h M ⌉ + 1 ) × ( ⌈ w M + 1 ⌉ ) (\lceil\frac{h}{M}\rceil+1)\times(\lceil\frac{w}{M}+1\rceil) (⌈Mh⌉+1)×(⌈Mw+1⌉)。此外,还会导致一些窗口小于 M × M M\times M M×M。一个简单的方法是将小窗口填充至 M × M M\times M M×M尺寸,并在计算注意力时将填充值遮蔽掉。若常规窗口划分的数量较小时(例如 2 × 2 2\times 2 2×2),这种简单的方法增加的计算量并不小( 2 × 2 → 3 × 3 2\times 2\rightarrow 3\times 3 2×2→3×3,增大 2.25 \text{2.25} 2.25倍)。本文提出了一个更加有效的计算方法,该方法如上图所示,通过向左上角方向循环移动。经过移动后,一个batch内的窗口可能由若干个子窗口组成,这些子窗口在 feature map \text{feature map} feature map中并不相邻。因此,对于每个子窗口,需要使用一个mask机制来限制自注意力计算。通过循环移动后,batch内窗口数量和常规常量划分一致,且同样高效。
2.4 相对位置编码
计算自注意力机制,在每个头计算相似度时引入相对位置偏移
B
∈
R
M
2
×
M
2
B\in\mathbb{R}^{M^2\times M^2}
B∈RM2×M2
Attention
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
T
/
d
+
B
)
V
(4)
\text{Attention}(Q,K,V)=\text{Softmax}(QK^T/\sqrt{d}+B)V \tag{4}
Attention(Q,K,V)=Softmax(QKT/d+B)V(4)
其中,
Q
,
K
,
V
∈
R
M
2
×
d
Q,K,V\in\mathbb{R}^{M^2\times d}
Q,K,V∈RM2×d是
query
\text{query}
query,
key
\text{key}
key和
value
\text{value}
value矩阵;
d
\text{d}
d是
query/key
\text{query/key}
query/key维度;
M
2
M^2
M2是一个窗口中的
patch
\text{patch}
patch数量。因为沿每一个轴的相对位置位于范围
[
−
M
+
1
,
M
−
1
]
[-M+1,M-1]
[−M+1,M−1],因此参数化一个较小尺寸的偏差矩阵
B
^
∈
R
(
2
M
−
1
)
×
(
2
M
−
1
)
\hat{B}\in\mathbb{R}^{(2M-1)\times(2M-1)}
B^∈R(2M−1)×(2M−1),且
B
B
B中的值从
B
^
\hat{B}
B^中获取。
作者发现相较于并引入偏差或者使用绝对位置嵌入,这种方法都有较大的改善。在输入中添加绝对位置嵌入会轻微降低表现,因此在实现中没有使用绝对位置嵌入。
3. 架构变体
本文构造的base模型称为 Swin-B \text{Swin-B} Swin-B,其模型尺寸和计算复杂度类似于 ViT-B/DeiT-B \text{ViT-B/DeiT-B} ViT-B/DeiT-B。此外,作者还引入了 Swin-T \text{Swin-T} Swin-T、 Swin-S \text{Swin-S} Swin-S和 Swin-L \text{Swin-L} Swin-L,其分别是base模型尺寸和计算复杂度的 0.25 × 0.25\times 0.25×、 0.5 × 0.5\times 0.5×和 2 × 2\times 2×版本。 Swin-T \text{Swin-T} Swin-T和 Swin-S \text{Swin-S} Swin-S的复杂度类似于 ResNet-50(DeiT-S) \text{ResNet-50(DeiT-S)} ResNet-50(DeiT-S)和 ResNet-101 \text{ResNet-101} ResNet-101。窗口的尺寸默认为 M = 7 M=7 M=7。每个注意力头的 query \text{query} query维度为 d = 32 d=32 d=32,每个 MLP \text{MLP} MLP的扩展层是 α = 4 \alpha=4 α=4。
这些模型变体的结构超参为:
- Swin-T \text{Swin-T} Swin-T: C = 96 C=96 C=96,层数量={2,2,6,2}
- Swin-S \text{Swin-S} Swin-S: C = 96 C=96 C=96,层数量={2,2,18,2}
- Swin-B \text{Swin-B} Swin-B: C = 128 C=128 C=128,层数量={2,2,18,2}
- Swin-L \text{Swin-L} Swin-L: C = 192 C=192 C=192,层数量={2,2,18,2}
其中, C C C是第一阶段隐藏层的维度。
三、总结
- 通过两层之间窗口的滑动来建立层次链接;
- 模型中,相对位置编码的效果更好;
- 在视觉领域:通过patch、window以及window间的链接来逐步建模;


















 8456
8456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











