







文章目录
一、导入数据
在打比赛的过程中,数据可视化可以让我们更好的看到每一个关键步骤的结果如何,可以用来优化方案,是一个很有用的技巧。
# 加载所需的库
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
text = pd.read_csv(r'result.csv')
二、数据可视化(泰坦尼克号数据集)
2.1 图形的分类和特征
| 柱形图(bar) | 根据柱形的高低来判断数据的多少,以直观的视觉角度描绘数据的基本变量。通常情况下,为了图像的视觉接受程度,通常一组数据不超过十个。 |
|---|---|
| 折线图plot | 是使用线条的形式反映数据随时间的变化趋势,数据越多时,反映的趋势过程越准确,这也是数据的特点,折线图通常处理的数据以时间变化为主要依据点。 |
| 饼图(pie) | 图像的展现形式与圆饼相似,将数据按照百分比的形式进行展示对比。同样,由于从视觉角度,人的肉眼对于百分比的精确度掌握不足,在选择数据时,以不超过六个为佳。 |
| 散点图(scatter) | 散点图作为三维数据的应用图,对于数据的划分也是依据多个不同的指标进行,散点图中单个数据的作用不明显,数据量越大,散点图的作用越明显,将数据集中的区域作为数据的分类标准。 |
#柱形图(bar)
x=np.arange(5)
y = np.random.random(5)
vert_bars = plt.bar(x, y)
plt.show()
#折线图(plot)
data=np.arange(10)
plt.plot(data)
plt.show()
#饼图(pie)
#自动根据数据的百分比画饼。labels是各个块的标签。autopct=%1.1f%%表示格式化
#百分比精确输出,explode,突出某些块,不同的值突出的效果不一样。pctdistance=1.12百分比距离圆心的距离,默认是0.6.
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'
sizes = [15, 30, 45, 10]
explode = (0, 0.1, 0, 0) # only "explode" the 2nd slice (i.e. 'Hogs')
plt.pie(sizes,autopct='%1.2f%%')
plt.show()
#散点图(scatter)
x = np.arange(10)
y = np.random.randn(10)
plt.scatter(x, y, color='red', marker='+')
plt.show()
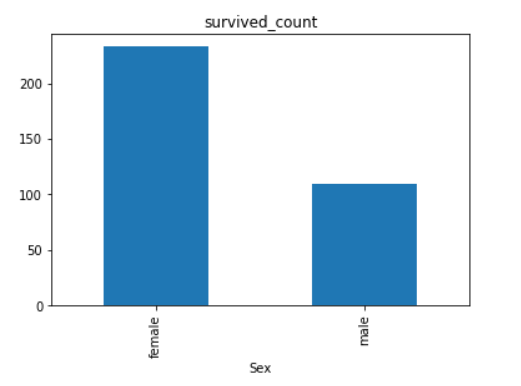
2.2 男女中生存人数分布情况(用柱状图试试)
sex = text.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()
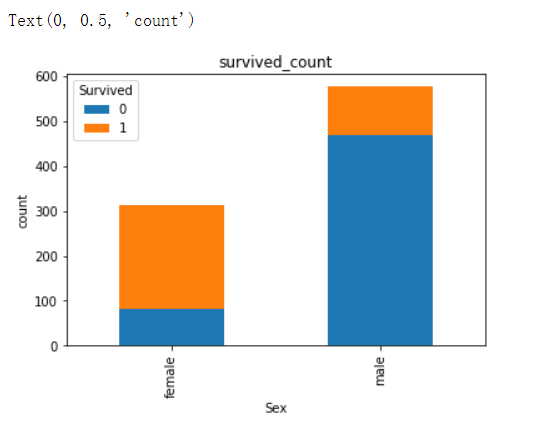
2.3 男女中生存人与死亡人数的比例图(用柱状图试试)
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
# plot(kind='bar',stacked=True)堆积条形图
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
plt.show()
Text(0, 0.5, ‘count’)
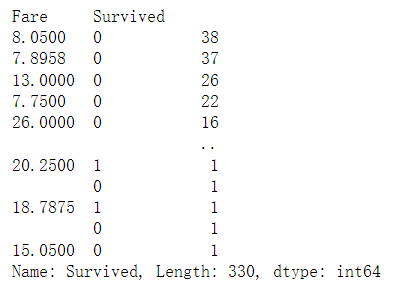
2.4 不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
# 排序
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur
# 排序后绘折线图
fare_sur=text.groupby('Fare')['Survived'].value_counts().sort_values(ascending=False)
fig = plt.figure(figsize=(20, 18)) #figure \的长宽
fare_sur.plot(grid=True) #添加网格线
plt.legend() #加上图例
plt.show()
# 排序前绘折线图
fare_sur1 = text.groupby(['Fare'])['Survived'].value_counts()
fig = plt.figure(figsize=(20, 18))
fare_sur1.plot(grid=True)
plt.legend()
plt.show()
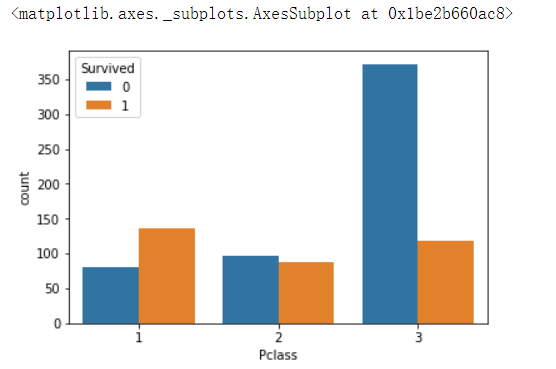
2.5 不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
# 1表示生存,0表示死亡
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
sns.countplot(x="Pclass", hue="Survived", data=text)
plt.show()
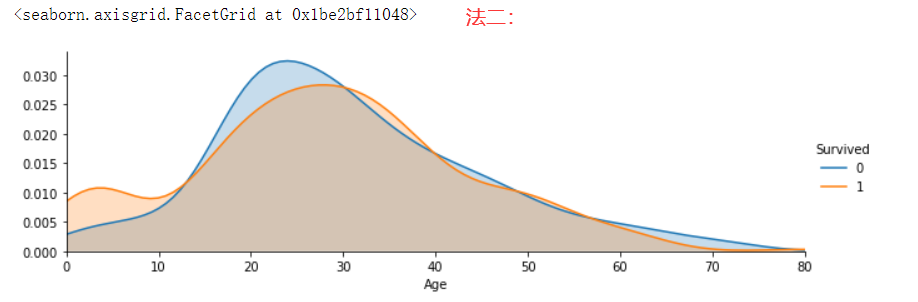
2.6 不同年龄的人生存与死亡人数分布情况。(不限表达方式)
# 法一:先聚合,再排序
facet=text.groupby(['Age'])['Survived'].value_counts().sort_index(ascending=True)
facet.plot()
plt.show()
#法二:seaborn的使用
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
plt.show()
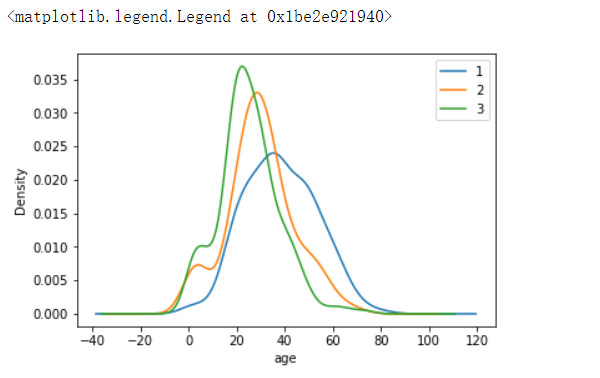
2.7 不同仓位等级的人年龄分布情况。(用折线图试试)
#法一
facet = sns.FacetGrid(text, hue="Pclass",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
plt.show()
#法二
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











