






从均匀分布U(a, b)中生成值,填充输入的张量或变量
# 服从 U(a, b)
torch.nn.init.uniform(tensor, a=0, b=1)
w = torch.Tensor(3, 5)
print nn.init.uniform(w)
从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
# 服从 N(mean,std)
torch.nn.init.normal(tensor, mean=0, std=1)
w = torch.Tensor(3, 5)
print torch.nn.init.normal(w)
用单位矩阵来填充2维输入张量或变量。在线性层尽可能多的保存输入特性
torch.nn.init.eye(tensor)
w = torch.Tensor(3, 5)
# 生成单位矩阵
print torch.nn.init.eye(w)
使用值val填充输入Tensor或Variable 。
# 将值始化值为val
torch.nn.init.constant(tensor, val)
w = torch.Tensor(3, 5)
# 生成一个三行五列值全为2的tensor
print torch.nn.init.constant(w,2)
xavier
torch.nn.init.xavier_uniform_(tensor, gain=1)
这里有一个gain,增益的大小是依据激活函数类型来设定
xavier初始化方法中服从均匀分布U(−a,a)
分布的参数
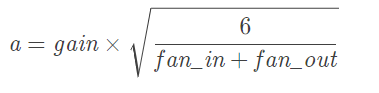
torch.nn.init.xavier_normal_(tensor, gain=1)
xavier初始化方法中服从正态分布N(mean=0, std)
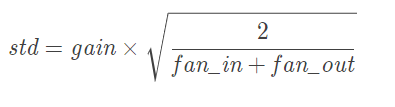
kaiming均匀分布
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
此为均匀分布,U~(-bound, bound), bound = sqrt(6/(1+a^2)*fan_in)
其中,a为激活函数的负半轴的斜率,relu是0
mode- 可选为fan_in 或 fan_out, fan_in使正向传播时,方差一致; fan_out使反向传播时,方差一致
nonlinearity- 可选 relu 和 leaky_relu ,默认值为 leaky_relu
nn.init.kaiming_uniform_(w, mode=‘fan_in’, nonlinearity=‘relu’)
kaiming正态分布
torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
此为0均值的正态分布,N~ (0,std),其中std = sqrt(2/(1+a^2)*fan_in)
其中,a为激活函数的负半轴的斜率,relu是0
mode- 可选为fan_in 或 fan_out, fan_in使正向传播时,方差一致;fan_out使反向传播时,方差一致
nonlinearity- 可选 relu 和 leaky_relu ,默认值为 leaky_relu
nn.init.kaiming_normal_(w, mode=‘fan_out’, nonlinearity=‘relu’)
注:fan_in = kernel_size[0] * kernel_size[1] * in_channels
fan_out = kernel_size[0] * kernel_size[1] * out_channels

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









