







// 永远别问我们双11花掉多少钱 包裹有多重,心里有多痛 //
双11刚刚过去,双12即将到来,不知大家的手是否还在?经历过某猫某东某宝拼杀的各位买家,大概都有过被这些平台猜透小心思,“看了又看、买了又买”的经历。它们在偷看你的生活吗,为什么总能直击你的心房,让你不由自主的献出积蓄呢?
今天,我们深扒一下那些“猜你喜欢”背后的势力——推荐系统算法中的元老级算法:基于物品的协同过滤算法。


不管你在“双11”还是“618”这样的“商造节日”中有没有剁过手,对“看了该商品的人还看了”这样的推荐形式也一定不陌生。
无论是淘宝还是京东,抑或其他电商网站,这样的推荐形式都可以算是标配。类似的还有“喜欢这部电影的人还喜欢”,“关注了TA的人还关注了”,等等。这样的推荐形式都来自一个“古老”的推荐算法——基于物品的协同过滤。
基于物品的协同过滤诞生于1998年,由亚马逊首先提出。2001年,其发明者发表了相应的论文。这篇论文在Google学术上的引用数已经近7000次,并且在WWW2016大会上荣获“时间检验奖”,颁奖词是:“这篇杰出的论文深深地影响了实际应用。”
历经15年,它仍然在发光发热,显然这个奖它当之无愧。虽然今天各家公司都在使用这个算法,好像它是一个公共资源一样,但亚马逊早在1998年,即论文发表前三年就申请了专利。

通常人的行为会有惯性,这种惯性可能是兴趣使然,可能是从众心理使然,也可能是下意识的行为使然。表现就是,看着碗里的想着锅里的,因为碗里的和锅里的总是很类似。这就是基于物品的协同过滤算法最原始的想法:给你推荐和你喜欢的物品相似的物品。
问题在于这个“相似的物品”是如何计算出来的。在基于内容的推荐系统中,相似物品是用内容的相似性计算出来的,这当然也是很符合直觉的做法。但是实际上人的群体行为还会有一些内容特征抓不到的相似性,同一个群体喜欢的物品,总是有某种共同的因素蕴藏其中,这种共同的因素虽然并不能被准确地表述出来,但可以用来做出很好的推荐。
解释了对基于物品的协同过滤算法的直觉理解后,再看看在技术上有何必要性。
在基于物品的协同过滤算法出现之前,信息过滤系统最常使用的是基于用户的协同过滤算法。基于用户的协同过滤算法首先计算相似用户,然后再根据相似用户的喜好推荐物品,这个算法有以下几个问题。
- 用户数量往往比较多,两两相似度计算起来非常吃力,成为瓶颈。
- 用户的品味变化是很快的,不是静态的,所以兴趣迁移问题很难被反映出来。
- 由于数据稀疏和倾斜,用户和用户之间的共同消费行为实际上是比较少的,而且一般都针对一些热门物品,对发现用户兴趣帮助不大。
反观基于物品的协同过滤算法,它首先计算相似物品,然后再根据用户消费过或者正在消费的物品为其推荐相似的物品,基于物品的算法怎样解决上面的这三个问题呢?
首先,严格地说,同一时期可以推荐的物品数量往往少于用户数量,所以一般计算物品之间的相似度就不会成为瓶颈。其次,物品之间的相似度不易改变,没有用户的品味变化快。这样就完全解耦了用户兴趣迁移这个问题。最后,物品对应的消费者数量较大,所以计算出的物品相似度比用户相似度更可靠。
协同过滤算法最依赖的是用户物品的关系矩阵,基于物品的协同过滤算法也不例外,它的基本步骤如下。
- 构建用户物品的关系矩阵,矩阵元素可以是用户的消费行为(隐式反馈),也可以是消费后的评分,还可以是对消费行为的某种量化,如时间、次数、费用等,也可当成评分。
- 假如矩阵的行表示物品,列表示用户,则两两计算行向量之间的相似度,可以得到物品相似度矩阵,行和列都表示物品。
- 根据推荐场景不同,产生两种不同的推荐结果。一种是在某一个物品页面推荐相关物品,另一种是在个人首页产生类似“猜你喜欢”的推荐结果。稍后会分别进行讲解。
▊ 计算物品相似度
接下来详细聊一下如何计算物品之间的相似度。从用户物品关系矩阵中得到的物品向量长什么样子呢?它是一个稀疏向量。*
- 向量的一维代表一个用户,向量的总维度代表总的用户数量。
- 向量各个维度的取值表示用户对这个物品的消费结果。可以是代表行为(隐式反馈)的布尔值,也可以是量化的分数,如评分、时间长短、次数多少、费用高低等,还可以是消费的评价分数。
- 没有消费过的物品就不再表示出来,所以说是一个稀疏向量。
接下来就是如何两两计算物品的相似度了,一般选择余弦相似度,当然还有其他的相似度计算法方法。计算公式如下:
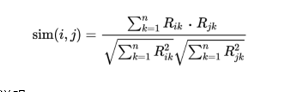

在这个公式中,分母表示两个物品向量的长度,求元素值的平方和再开方。分子是两个向量的点积,相同位置的元素值相乘再求和。
这个公式的物理意义在于计算两个向量的夹角余弦值。相似度为1时,对应角度为0°,如胶似漆;相似度为0时,对应角度为90°,毫不相干,互为“路人甲”。
看上去计算量很大,貌似每一个求和的复杂度都和向量维度,即用户数量是一样的。但是别忘了,前面说过它们都是稀疏向量,也就是向量中绝大多数值都是0,求和时不用算,求点积时更不用算,只计算两个物品的公共用户即可,只是少许几个乘积而已。
关于这个算法,物品之间的相似度计算有很多可以改进之处。通常有以下两个改进方向。
- 物品维度中心化。用矩阵元素的原始值减去物品向量的平均值。先计算每一个物品收到的评分的平均值,再用物品向量中的分数减去对应物品的平均值。这样做的目的是什么呢?去掉物品中“铁杆粉丝”群体的非理性因素,例如一个流量明星主演的电影,其“铁杆粉丝”可能会集体去打高分,那么用物品的平均值来实现中心化就有一定的抑制作用。
- 用户维度中心化。用矩阵元素的原始值减去用户向量的平均值。计算每一个用户的评分平均值,他给所有物品的评分再减去这个平均值。这样做的目的又是什么呢?每个人标准不一样,有的标准严苛,有的宽松,所以减去用户评分的平均值可以在一定程度上保留偏好,去掉主观成分。
*
上面提到的相似度计算方法不只适用于评分矩阵,也适用于行为矩阵。所谓行为矩阵,即矩阵元素为0或者1的布尔值,也就是隐式反馈。隐式反馈取值特殊,有一些基于物品的改进推荐算法无法应用,比如著名的Slope One算法,稍后会讲到。
实际上,基于物品的协同过滤算法和基于用户的协同过滤算法在计算相似度这一步是一模一样的,区别就是一个计算行向量的相似度,另一个计算列向量的相似度,只需要将用户行为矩阵转置一下即可。
▊ 计算推荐结果
在得到物品相似度之后,接下来就是为用户推荐他可能会感兴趣的物品,基于物品的协同过滤算法有两种应用场景。
第一种属于Top K 推荐,常常表现为类似“猜你喜欢”这样的形式。触发方式是当用户访问首页时,汇总和用户已经消费过的物品相似的物品,按照汇总后分数从高到低推出。汇总的公式是这样的:
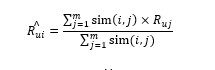
这个公式的核心思想和基于用户的协同过滤算法一样,用相似度加权汇总。要预测一个用户u 对一个物品i 的评分数,就要遍历用户u 评分过的所有物品。假如一共有m 个物品,用每一个物品和待计算物品i的相似度乘以用户的评分,加权求和后除以所有这些相似度的总和,就得到了一个加权平均评分,作为用户u 对物品i的分数预测。
和基于物品的协同过滤算法一样,我们在计算时不必对所有物品都计算一遍,只需要按照用户评过分的物品,逐一取出和它们相似的物品就可以了。
这个过程离线完成后,去掉那些用户已经消费过的物品,保留分数最高的K 个结果进行存储。当用户访问首页时,直接展示出来即可。
第二种属于相关推荐,也就是本文开篇时提到的场景。这类推荐不需要提前合并计算,当用户访问一个物品的详情页面时,或者完成一个物品消费的结果页面时,可以直接获取这个物品的相似物品推荐,也就是“看了又看”或者“买了又买”这样的推荐结果。
▊ Slope One算法
对于经典的基于物品的协同过滤算法,相似度矩阵计算无法实时更新,整个过程都是离线完成的,而且还有另一个问题,计算相似度时没有考虑相似度的置信问题。例如,两个物品都被同一个用户喜欢,且仅仅被这一个用户喜欢,那么余弦相似度计算的结果是1,这个1明显不可信,但在最后汇总计算推荐分数时,却对结果的影响很大。
Slope One算法针对这些问题做了改进。Slope One算法专门针对评分矩阵,不适用于行为矩阵。Slope One算法计算的不是物品之间的相似度,而是物品之间的距离,即相似度的反面。举个例子就一目了然了。下表是一个简单的评分矩阵。
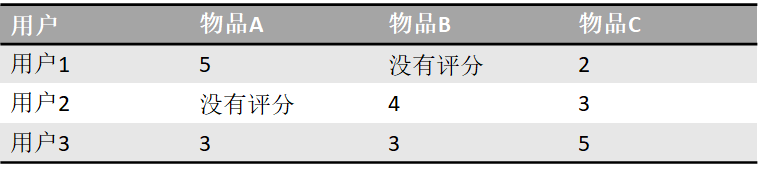
这个矩阵反映了这些事实:用户1给物品A、C评分,分别是5、2;用户2给物品B、C评分,分别是4、3;用户3给物品A、B、C评分,分别是3、3、5。现在,先来两两计算物品之间的平均距离,如下表所示。

根据计算方法,以物品B和物品C为例:
- 它们有两个共同用户,分别是用户2和用户3。
- 两个共同用户对物品A和物品B的评分距离分别是:1=4-3,-2=3-5,平均距离是-0.5=(1-2)/2。
在距离矩阵表中,括号里的数字表示两个物品的共同用户数量,代表两个物品平均距离的置信程度。比如物品A和物品B之间的平均距离是0,共同评分用户数是1,知道这个平均距离后,就可以用一个已评分物品的评分去预测另一个物品的评分。
用这个距离矩阵去预测那些还没有被用户评分的物品会被用户评多少分,方式就是根据用户已经评分的物品,以及物品之间的评分距离来推算,公式如下: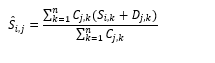

这个公式中包含以下两个部分。
- 分子中括号里部分表示用户对物品k 的评分加上物品k 和物品j 的平均评分距离,用户对物品j 还没有评分。实际上是单个物品k 对物品j 的评分预测。
- 分母是一个用共同评分用户数对分子中括号部分做的加权平均。
举个例子:
如果只知道用户2给物品B的评分是4,物品B和物品A之间的平均距离是0,因此根据这一个物品可以预测用户2给物品A的评分也是4。类似根据物品C来预测用户2给物品A的评分为3.5。再按照共同评分用户数求加权平均后,用户2可能会给物品A的评分为:
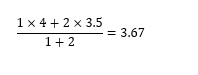

本文在基于用户的协同过滤算法基础上介绍了一个比较常见的算法——基于物品的协同过滤算法。这个算法常常在电商网站上见到,“猜你喜欢”“看了又看”这样的相关推荐,都是由这个推荐算法产生的。
最后我们介绍了一个改良版的基于物品的协同过滤算法——Slope One算法。这个算法的核心思想是计算物品之间的评分距离,再采用共同评分用户数加权来得到结果。

本文知识点选自博文视点新书《推荐系统》。本书是一本关于推荐系统产品如何落地的综合图书,内容覆盖产品、算法、工程、团队和个人成长。

本书旨在解决推荐系起步阶段80%的问题,对多达20个推荐系统核心主题进行精细讲解,横跨产品、算法、工程团队和个人成长。不用直击灵魂,只要直击左下阅读原文,就可以领略这本由推荐系统不折不扣的老炮小生,给大家带来的亦庄亦谐别具一格的好书。
█ 本 书 特 色
- 快:跨技术实践|管理决策视角,历数业界优选案例|工具,帮助非算法出身工程师快速搭建起可用系统。
- 通:旨在实现决策|架构|安全|运营无障碍沟通,覆盖产品|算法|工程|团队|个人成长|思维模式|问题类型。
- 全:纵向系统剖析推荐算法模型,从传统内容推荐、协同过滤到FM模型再到评价指标与深度学习应用。
- 珍:解密设计推荐系统不可或缺又不可多得一手资料,如信息流内在逻辑|典型工程架构|内部模块细节。
█ 关 于 作 者
陈开江
偶以“刑无刀”的名义“出没江湖”,初于北京理工大学学习自然语言处理,先后任职于新浪微博、车语传媒、贝壳找房等公司,做自然语言处理及推荐系统开发等工作,也曾有两三年与推荐系统有关的创业经验。有译著《机器学习:实用案例解析》,在公众号ResysChina上发表过推荐系统系列文章,在极客时间开设有《推荐系统36式》付费专栏。
█ 大 咖 推 荐
- 谷文栋 / ResysChina发起人
- 张俊林 / 新浪微博机器学习团队AILab负责人
- 阿稳 / 酷划CTO,曾任豆瓣、淘宝资深算法专家,《智能Web算法》译者
- 王守崑 / 爱因互动创始人,曾任豆瓣首席科学家
- 张奇 / 北京惠每科技有限公司CEO,曾任天猫推荐团队负责人
- 张相於 / 阿里巴巴高级算法专家
- 严强 / 快手商业副总裁,曾任淘宝资深算法专家
- 冯扬 / 贝壳找房数据智能中心负责人,曾任腾讯、新浪微博推荐算法专家
█ 本书目录结构
1 概念与思维1.1 该要推荐系统吗1.2 问题模式有哪些1.3 要具有什么样的思维模式2 产品漫谈2.1 推荐系统的价值和成本2.2 信息流简史3 内容推荐3.1 用户画像简介3.2 标签挖掘技术3.3 基于内容的推荐4 近邻推荐4.1 基于用户的协同过滤算法4.2 基于物品的协同过滤算法4.3 相似度算法一览5 矩阵分解5.1 SVD算法5.2 ALS算法5.3 BPR算法6 模型融合6.1 线性模型和树模型6.2 因子分解机6.3 Wide&Deep模型7 探索和利用7.1 MAB问题与Bandit算法7.2 加入特征的UCB算法7.3 Bandit算法与协同过滤算法8 深度学习8.1 深度隐因子8.2 深度CTR预估9 其他算法9.1 排行榜9.2 采样算法9.3 重复检测10 架构总览10.1 信息流推荐架构10.2 个性化首页架构10.3 搜索引擎、推荐系统及广告系统11 关键模块11.1 日志收集11.2 实时推荐11.3 AB实验11.4 推荐服务11.5 开源工具12 效果保证12.1 测试及常用指标12.2 推荐系统的安全13 团队与个人13.1 团队组建13.2 个人成长13.3 小结
▶ 博文菌●互动时间 ◀
虽然“猜你喜欢”来势汹汹,但也免不了有翻车的时候,欢迎在留言区分享你经历过的“猜你喜欢”翻车瞬间!
了解本书详情:https://u.jd.com/RJo8Hu
本文由博客一文多发平台 OpenWrite 发布!
















 4558
4558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









