








ICCV-2019 oral presentation
文章目录
1 Background and Motivation
Feature upsampling 操作在现在的 CNN 结构中很常见,eg FPN 中
upsampling 是必要的:
- super resolution, inpainting and semantic segmentation 任务中,high-level / low-res feature map 需要上采样来 match the high-resolution supervision
- 现在的 state-of-art 都有融合 highlevel / low-res feature map 和 low-level / high-res feature map 的操作(eg:FPN,UNet,Stacked Hourglass)
常用的 upsampling 方法:
- nearest neighbor and bilinear interpolations(缺点:only consider sub-pixel neighborhood)
- deconvolution(缺点:同样的卷积 kernel 遍历了全图,无视了 underlying content,难以很好的捕捉 local variations;kernel size 太大的话,计算量就大,太小的话 limiting its expressive power and performance,类似插值)
针对缺点,作者提出 ContentAware ReAssembly of Features (CARAFE) 的上采样操作,优势如下:
- Large field of view(不像双线性差值那样的小感受野)
- Content-aware handling(不像 deconvolution 那样固定的 kernel)
- Lightweight and fast to compute

左边一组 Mask RCNN 右边一组 CARAFE 的 muli-level FPN,可以看出,作者的方法 not only 特征图的上采样,but also learns to enhance 特征的 discrimination
2 Advantages / Contributions
-
提出了CARAFE—— a universal, lightweight and highly, effective feature upsampling operator
-
universal effectiveness——在 object detection, instance/semantic segmentation and inpainting benchmark 中都有一定的提升
3 Method

两步走,第一步 Kernel Prediction Module(生成卷积核),第二步 Content-aware Reassembly Module(新特征图由原特征图和第一步生成的卷积核卷积产生)
对应如下公式的
ψ
\psi
ψ 和
ϕ
\phi
ϕ 操作,
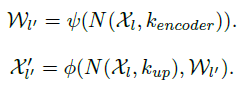
其中
N
(
χ
l
,
k
)
N(\chi _l,k)
N(χl,k) 表示特征图
χ
\chi
χ 上,以位置
l
l
l 为中心的,
k
∗
k
k*k
k∗k 大小的区域,新生成的特征图为
χ
′
\chi'
χ′
3.1 Kernel Prediction Module

- Channel Compressor:1*1 卷积,降低通道数 C → C m C \to C_m C→Cm,减少计算量
- Content Encoder: k e n c o d e r ∗ k e n c o d e r k_{encoder}*k_{encoder} kencoder∗kencoder 卷积, C m → C u p C_m \to C_{up} Cm→Cup, C u p C_{up} Cup 细化一点就是 σ 2 ∗ k u p 2 \sigma^2*k_{up}^2 σ2∗kup2,其中 σ \sigma σ 是上采样倍数, k u p k_{up} kup 是生成新特征图时,在原特征图上采用的卷积核大小(后面会有介绍)。 k e n c o d e r k_{encoder} kencoder 当然是越大越能采集全局信息,但是计算量也会变大,作者实验表明 k e n c o d e r = k u p − 2 k_{encoder} = k_{up}-2 kencoder=kup−2 性价比最高。Content Encoder 目的是 generate reassembly kernels based on the content of input features.
- Kernel Normalizer:用的是 softmax,前面的 reshape(上图中用四个箭头表示的操作) 其实也是很精髓的,把编码的通道信息扩充到分辨率维度!softmax 在 channel 维度上进行,范围 0-1,而不是任意的放大缩小(后续 Content-aware Reassembly Module 中,用学出来的 kernel 和原特征图卷积,kernel 数值范围限定——0~1,所以作者叫 reassembly of feature)
Channel Compressor,Content Encoder 有点像 encoder 和 decoder 模式,达到想要的结果!这三个操作中,最让我惊艳的是里面的 reshape 操作,哈哈!作者好像没有浓墨重彩……
3.2 Content-aware Reassembly Module

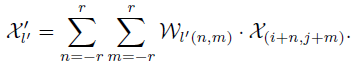
-
χ l ′ ′ \chi_{l'}^{'} χl′′ 表示新特征图 χ ′ \chi^{'} χ′ 的 l ′ ( i ′ , j ′ ) l'(i',j') l′(i′,j′) 位置
-
W W W 表示卷积核
-
χ \chi χ 表示原始特征图
上面是卷积操作,原始特征图以 ( i , j ) (i,j) (i,j)为中心 的 − r -r −r 到 r r r 区域,与对应大小的 W W W 相乘,生成新的特征图
感觉公式中 χ ( i + n , j + m ) \chi_{(i+n,j+m)} χ(i+n,j+m) 表示成 χ l ( i + n , j + m ) \chi_{l_(i+n,j+m)} χl(i+n,j+m) 更好
总结一下:想象原特征图是
H
∗
W
∗
1
H*W*1
H∗W∗1,要生成大小是
2
H
∗
2
W
∗
1
2H*2W*1
2H∗2W∗1的新特征图,新特征图的每个位置的值是由
k
∗
k
k*k
k∗k 大小的原特征图块和learning到的
k
∗
k
k*k
k∗k 大小的卷积核相乘得到!新特征图
k
∗
k
k*k
k∗k区域中心坐标
(
i
′
,
j
′
)
(i',j')
(i′,j′)和原特征图
k
∗
k
k*k
k∗k 区域中心坐标
(
i
,
j
)
(i,j)
(i,j)的映射关系如下:
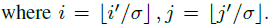
σ
\sigma
σ 是上采样倍数,上面的假设是 2
上面的假设忽略了特征图的通道数,加上通道维度的话 ( H ∗ W ∗ C ) (H*W*C) (H∗W∗C),同样的卷积核要遍历所有的通道数!(这就是 content aware 的由来)
看了上面一个例子,心里第一个感觉?空间注意力?确实很像,作者也对其进行了解释
空间注意力是对分辨率维度进行 scale
CARAFE是对分辨率维度进行区域内的加权平均和
作者总结空间注意力是 CARAFE 的一个特例,也即,当 k u p k_{up} kup 为 1 的时候!!!
了解了细节,我们从宏观上看看,CARAFE 的用武之地

top-down 的双线性差值(上采样)操作,替换成了 CARAFE 模块
4 Experiments
4.1 Datasets
- MS COCO 2017(Object Detection and Instance Segmentation)
- ADE20k(Semantic Segmentation.)
- Places(Image Inpainting)
4.2 Benchmarking Results
Implementation Details
C m = 64 C_m = 64 Cm=64, k e n c o d e r = 3 k_{encoder} = 3 kencoder=3, k u p = 5 k_{up} = 5 kup=5
1)Object Detection&Instance Segmentation
nearest neighbor interpolation vs CARAFE

all scale 通吃,老少皆宜,再感受一下

细腻红润有光泽
华山论剑,傲世群雄(arious upsampling methods)

比 spatial attention 参数量多了好多,不过银烛之火,岂敢与皓月争辉(整个模型的参数量)

消融实验

ADE20k 略
Image Inpainting 略
UperNet 略
4.3 Ablation Study & Further Analysis
Faster RCNN with a ResNet-50 backbone, and evaluate the results on COCO 2017 val.

天花板是 64,表示 channel compressor can speed up the kernel prediction without harming the performance

k
e
n
c
o
d
e
r
=
k
u
p
−
2
k_{encoder} = k_{up}-2
kencoder=kup−2 黄金搭档,前三后五性价比高

normalize the reassembly kernel to be summed to 1 很重要

太扣题了,这个图,content-aware reassembly,实在佩服
5 Conclusion(owns)
只对分辨率维度进行了处理,叫 content-aware,和 spatial attention 的区别在于 reassembly,一个是精装版,一个九合一!动了元器件,普适性很广,行文实验设计的真有说服力!!!















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









