








ICCV-2017
【Knee Landmark】《KNEEL:Knee Anatomical Landmark Localization Using Hourglass Networks》 一文中有涉及到这篇论文,描述的是基于 bottleneck 的改进,有利于 gradient flow,从而提升特征点定位的能力,今天有空来看看!
文章目录
1 Background and Motivation

近年来,CNN 的发展使得特征点定位任务有了革命性的提升,在最具挑战性的人体姿态估计(human pose estimation)和人脸对齐(face alignment)数据集上展示了卓越的准确性!
然而目前基于 CNN 的特征点定位方法是 computationally expensive(费 GPU,模型较大),离达到实时性或应用到移动端还有一定的距离。
作者采用二值化卷积神经网络,设计新的残差模块(residual block)来弥补二值化带来的精度损失(而不是从设计量化方法的角度来展开)!保证精度的同时,大幅度压缩了网络的计算量!让“旧时王谢堂前燕”,得以“飞入寻常百姓家”
2 Advantages / Contributions
-
first to study the effect of neural network binarization on localization tasks(是 dense prediction 问题,而不是在 classification 任务上)
-
提出了 a novel hierarchical, parallel and multi-scale residual architecture(HPM),比 ResNet 原有的 bottleneck 结构更高效,弥补了二值化网络和正常网络之间的 gap
-
在许多人体姿态检测和人脸对齐数据集上取得了state-of-the-art
3 Method


hierarchical, parallel and multi-scale(HPM),相比于 ResNet 结构
- 增加了原有 bottleneck 中的感受野大小
- 提高了 gradient flow
- 和原来的 bottleneck 参数一样
- 不包含 1×1 conv
- 是从提升 binary 网络的 performance 和 efficiency 角度设计的
用的单个 hourglass Network,没有用 Stacked 版!predicts a set of heatmaps (one for each landmark)
3.1 Binarized HG
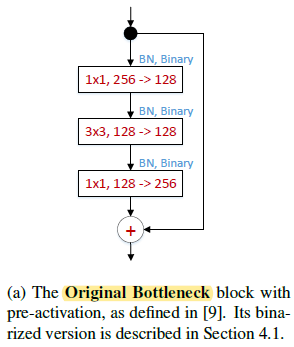
用 ResNet-2.0 版本(《Identity mappings in deep residual networks》,改变了 BN、relu、Conv 的堆叠顺序) 的 bottleneck 作为 Hourglass Network(HG)的 block,用 《XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks》中的二值化网络方法替换了 HG,结果如 Table 1 所示

评价指标用的 PCKh
PCK - Percentage of Correct Keypoints(计算检测的关键点与其对应的 groundtruth 间的归一化距离小于设定阈值的比例——the percentage of detections that fall within a normalized distance of the ground truth!PCKh,MPII 数据集中是以头部长度(head length)作为归一化参考(人体关键点检测的评价度量PCK, PCKh, PDJ)
我就纳闷了,权重都二值化,乘法变成 XNOR,参数量还能一样,是写错了吗?还是说增加了二值化网络的特征图个数,让参数量和正常网络相当?那效果也有差距啊,显得二值化网络一无是处了(可能是计算量下降了很多?速度快了?应该吧,有空我去看看原文)
看看二值化 HG 表现较差的例子


3.2 On the Width of Residual Blocks

相比于 Fig.4(a)增加了特征图的个数(channels),增加了二值化网络的信息量,当然这种改变也会增加 computational cost
3.3 On MultiScale Filtering

不同于实数网络,二值化网络的 conv filter 只有
2
k
2^k
2k 种取值,
k
k
k 是 filter size,为了解决二进制情况下 3×3 滤波器的有限表示能力问题,作者借鉴 【Inception-v4】《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》 的思想,通过并联更大 filter size 和 max pooling 分支,使得同一 block 的感受野不再单一,实现了 multi-scale filter!

可以看到,比 Fig.4(a)、Fig.4(b)效果都好。
注意 table 2 是 binary HG Network 的结果!!!
3.4 On 1 × 1 Convolutions


作者认为二值化网络中的 1×1卷积 have a very limited learning power(对原来特征的只能进行 limited modification,如下图所示),所以决定替换掉 Fig.4(c)中的所有 1×1 卷积,全部采用 3×3 卷积!


效果如下表所示

可以看到,Fig.4(b)方法参数量比 Fig.4(d)多,效果还差,印证了 1×1 在二值化网络中的局限性很大
总结 Fig.4(b)、(c)、(d)的经验分别如下:
- the block should preserve its width as much as possible (avoiding large drops in the number of channels
- multi-scale filters should be used.
- no convolutional layers with 1×1 filters should be used
3.5 On Hierarchical, Parallel & MultiScale
二值网络对 fading gradient 问题更加敏感,实验中作者观察到二值化网络比实数网络的梯度要小10倍以上!于是在 Fig.4(b)、(c)、(d)的基础上设计了如 Fig.4(e)所示的 hierarchical, parallel multi-scale structure(HPM Block),每层结构有两个分支,最短的分支都是 identity,能确保 gradient information 流动时保持通畅!三层结构,最大的感受野能堆叠到类似
7
∗
7
7*7
7∗7 卷积的效果!采用的是 concatenation,避免了 add 操作(参考【ShuffleNet V2】《ShuffleNet V2:Practical Guidelines for Efficient CNN Architecture Design》 中的第四条设计准则)


结果如下

可以看到,效果提升还是蛮明显的!
4 Experiments
4.1 Datasets
- MPII Human Pose Dataset

- AFLW:Annotated Facial Landmarks in the Wild,25993 faces annotated with up to 21 landmarks

- AFLW-PIFA:grey-scale subset of AFLW,5200 images,annotated with 34 points from a 3D perspective.
- AFLW2000-3D:subset of AFLW re-annotated by 《Face alignment across large poses: A 3d solution》,有 68 points
4.2 HPM Block vs Bottleneck
1)Binary 条件下

把 bottleneck 中 11 全部替换成 33,改变 width(channels)使其和 HPM Block 参数量匹配,对比下效果发现,还是作者提出的 HPM 猛,说明 gradient 顺畅的 flow 和 multi-scale 相当重要
作者也通过改变 HPM Block 的 width,达到原版 bottleneck 的参数量,来比较效果
结果如下:

还是作者提出的 HPM 比较猛
2)Real 条件下

可以看到,还是作者的 HPM 较好,相比于 binary 版本,HPM 提升的更少,说明 HPM 在 binary 的情况下,设计的很到位!!!
4.3 Ablation studies
1)Is Augmentation required?
前人们 suggested that binarization is an extreme case of regularization,作者想探讨下,二值化自带先验知识(regularization),加数据增强还有提升空间不?
作者采用了如下几种数据增强方式
- rotation (between -40o and 40o degrees),
- flipping
- scale jittering (between 0.7 and 1.3)

数据增强有用
2)The effect of loss

- Gaussian around the correct location of each landmark and trains using a pixel-wise L2 loss
- Sigmoid cross-entropy pixel-wise loss
前者在实数网络中梯度就很小,变成二值化网络后,梯度更小
3)Pooling type
max-pooling 比 average pooling 好了 4%
4)ReLUs
卷积后加 relu,效果提升了 2%
4.4 Comparison with state-of-the-art
1)Human Pose Estimation

文献 [20] 是 Stacked Hourglass Network,由 8 个 Hourglass 结构堆叠而成!
可以看出 Ours, bin. 和 Ours[1x], real 还有不小的差距(78.1 vs 85.5),说明 HPM 的设计还有提升的空间!
Ours[8x], real 比 Stacked Hourglass Network 还强,也印证了 HPM 的有效性
Stacked Hourglass Network

2)Face alignment

0,30,60,90 是应该是脸偏离的度数
NME 是 normalization mean error 的意思,具体参考下面这张图片
68 是特征点的个数, D e y e s D_{eyes} Deyes 就是以眼睛的距离作为归一化的参考
参考:归一化均方误差

作者的方法比当前最好的方法好
再看看在另外两个人脸对齐数据集上的表现


均比 the state-of-the-art 方法好
5 Conclusion(own)
- non-rigid deformation:刚性变换就是图像的平移加旋转,非刚性就是比这更复杂的变换,如伸缩,仿射,透射,多项式等一些比较复杂的变换。
- we describe multiple orthogonal ways to boost performance;
- face alignment 是人脸对齐,但是人脸检测和人脸关键点检测是对齐的前提条件。其主要思路是通过检测人脸关键点,然后作仿射变换等进行人脸对齐
- PCK - Percentage of Correct Keypoints(计算检测的关键点与其对应的 groundtruth 间的归一化距离小于设定阈值的比例——the percentage of detections that fall within a normalized distance of the ground truth!PCKh,MPII 数据集中是以头部长度(head length)作为归一化参考(人体关键点检测的评价度量PCK, PCKh, PDJ)
- 1×1 卷积在二值化网络中表达能力很有限
- HPM Block 采用的是 concatenation,避免了 add 操作















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









