







代码地址 Github
Mask R-CNN for Object Detection and Segmentation(matterport/Mask_RCNN)
这篇博客是对 Mask R-CNN 源码(keras + TensorFlow 版本)进行了一定程度的解析,采用了自己的数据集和数据处理方式,将 Mask R-CNN 的头部结构进行了剔除,仅用于目标检测!由于 Mask R-CNN 作者的代码可视化工作做的相当人性化,所以我已此为基础进行了详细的梳理!不过由于中途事务的原因,这篇博客在草稿箱应该沉睡了1年多之久,Mask-RCNN 代码刚开源的时候,我和小伙伴就第一时间研读和修改了,以便用于自己的实验,后期在有空的时间陆陆续续对博文进行了整理与修订,但应该还存在一些错误的标注和注释!
文章目录
- 0 训练
- 1 整体流程
- 2 代码
- 2.1 model.py
- 2.1.1 model.log
- 2.1.2 model.data_generator
- 2.1.3 model.build_rpn_targets
- 2.1.4 model.generate_random_rois
- 2.1.5 model.build_detection_targets
- 2.1.6 model.mold_image
- 2.1.7 model.unmold_image
- 2.1.8 class MaskRCNN()
- 2.1.9 model.build_rpn_model
- 2.1.10 model.rpn_graph
- 2.1.11 class ProposalLayer()
- 2.1.12 model.apply_box_deltas_graph
- 2.1.13 model.clip_boxes_graph
- 2.1.14 model.parse_image_meta_graph
- 2.1.15 class DetectionTargetLayer()
- 2.1.16 model.detection_targets_graph
- 2.1.17 model.trim_zeros_graph
- 2.1.18 model.overlaps_graph
- 2.1.19 model.fpn_classifier_graph
- 2.1.20 class PyramidROIAlign()
- 2.1.21 model.log2_graph
- 2.1.22 rpn_class_loss_graph
- 2.1.23 rpn_bbox_loss_graph
- 2.1.24 batch_pack_graph(x, counts, num_rows):
- 2.1.25 mrcnn_class_loss_graph
- 2.1.26 mrcnn_bbox_loss_graph(target_bbox, target_class_ids, pred_bbox):
- 2.1.27 class DetectionLayer
- 2.1.28 refine_detections(rois[b], mrcnn_class[b], mrcnn_bbox[b], window[b], self.config))
- 2.2 visualize.py
- 2.3 utils.py
- 3 error
- 4 Reference
0 训练
在终端输入
python3 ury.py train --dataset=/root/commonfile/urinary_sediment/cocostyle/ --model=/root/userfolder/Experiment/DenseNet_FPN/logs/mask_rcnn_ury_0050.h5
1 整体流程
1.1 Training


1.2 Inference
1.1 小节图5 nms 6000→2000 变成 nms 6000→1000
将产生的 1000 个 roi 直接丢入 头部,也即少了 1.1 小节图5 中的步骤 ⑥,DetectionTargetLayer(2000 to 200 的过程,正负样本1:3,IoU 0.5为界限),然后 class DetectionLayer 进行筛选
取 softmax 后最大的类别,踢去背景,剔除分数 <0.7 的, 然后对每一个类别做阈值为 0.3 的 NMS,然后截选出DETECTION_MAX_INSTANCES 个样本!!!
精炼一下如下:
0)非背景类
1)iou 阈值 ≥ 0.7
2)逐类进行 nms 0.3
3)截选出 DETECTION_MAX_INSTANCES 个样本
2 代码
2.1 model.py
2.1.1 model.log
输入: 变量的名字和变量
输出: 变量的shape和最大最小值
2.1.2 model.data_generator
调用了utils.generate_pyramid_anchors 、model.build_rpn_targets
augment:数据增强只支持水平翻转
random_rois :Useful if training the Mask RCNN part without the RPN.
Returns a Python generator
def data_generator(dataset, config, shuffle=True, augment=True, random_rois=0,
batch_size=1, detection_targets=False):
"""
A generator that returns images and corresponding target class ids,
bounding box deltas, and masks.
dataset: The Dataset object to pick data from
config: The model config object
shuffle: If True, shuffles the samples before every epoch
augment: If True, applies image augmentation to images (currently only
horizontal flips are supported)
random_rois: If > 0 then generate proposals to be used to train the
network classifier and mask heads. Useful if training
the Mask RCNN part without the RPN.
batch_size: How many images to return in each call
detection_targets: If True, generate detection targets (class IDs, bbox
deltas, and masks). Typically for debugging or visualizations because
in trainig detection targets are generated by DetectionTargetLayer.
Returns a Python generator. Upon calling next() on it, the
generator returns two lists, inputs and outputs. The containtes
of the lists differs depending on the received arguments:
inputs list:
- images: [batch, H, W, C]
- image_meta: [batch, size of image meta]
- rpn_match: [batch, N] Integer (1=positive anchor, -1=negative, 0=neutral)
- rpn_bbox: [batch, N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
- gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs
- gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]
- gt_masks: [batch, height, width, MAX_GT_INSTANCES]. The height and width
are those of the image unless use_mini_mask is True, in which
case they are defined in MINI_MASK_SHAPE.
outputs list: Usually empty in regular training. But if detection_targets
is True then the outputs list contains target class_ids, bbox deltas,
and masks.
"""
2.1.3 model.build_rpn_targets
被调用
rpn_match, rpn_bbox = build_rpn_targets(image.shape, anchors, gt_class_ids, gt_boxes, config)
说明,Given the anchors and GT boxes, compute overlaps and identify positive anchors and deltas to refine them to match their corresponding GT boxes.
调用
utils.compute_overlaps(anchors, gt_boxes)
最后 rpn_bbox 要减均值(RPN_BBOX_STD_MEANS)除以方差(RPN_BBOX_STD_DEV)
def build_rpn_targets(image_shape, anchors, gt_class_ids, gt_boxes, config):
"""Given the anchors and GT boxes, compute overlaps and identify positive
anchors and deltas to refine them to match their corresponding GT boxes.
anchors: [num_anchors, (y1, x1, y2, x2)]
gt_class_ids: [num_gt_boxes] Integer class IDs.
gt_boxes: [num_gt_boxes, (y1, x1, y2, x2)]
Returns:
rpn_match: [N] (int32) matches between anchors and GT boxes.
1 = positive anchor, -1 = negative anchor, 0 = neutral。eg(65472,)
rpn_bbox: [N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas. (256,4)only positive not zero
"""
2.1.4 model.generate_random_rois
without RPN时
90% 在 gt 的九宫格中产生 roi
10% 在 整张图中随机产生 roi
输出(2000,4)
rpn_rois = modellib.generate_random_rois(image.shape, random_rois, gt_class_ids, gt_boxes)
def generate_random_rois(image_shape, count, gt_class_ids, gt_boxes):
"""Generates ROI proposals similar to what a region proposal network
would generate.
image_shape: [Height, Width, Depth]
count: Number of ROIs to generate
gt_class_ids: [N] Integer ground truth class IDs
gt_boxes: [N, (y1, x1, y2, x2)] Ground truth boxes in pixels.
Returns: [count, (y1, x1, y2, x2)] ROI boxes in pixels. eg:(2000,4)
"""
2.1.5 model.build_detection_targets
从2000个中选出200个,positive 和 negative 1:2
positive(RoI 与 GT 的 IoU 大于0.5) 不超过 0.33
negative(RoI 与 GT 的 IoU 小于0.5)不超过 0.66
如果 positive 不足 33%,用negative补
如果 positive + negative 不足 200,且 为0(small chance),报错咯
如果 positive + negative 不足 200,但大于0,positive,negative 不变,再从negative 中重复抽,补齐200
def build_detection_targets(rpn_rois, gt_class_ids, gt_boxes, config):
"""Generate targets for training Stage 2 classifier and mask heads.
This is not used in normal training. It's useful for debugging or to train
the Mask RCNN heads without using the RPN head.
Inputs:
rpn_rois: [N, (y1, x1, y2, x2)] proposal boxes.
gt_class_ids: [instance count] Integer class IDs
gt_boxes: [instance count, (y1, x1, y2, x2)]
Returns:
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] (200,4)
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. (200,)
bboxes: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (y, x, log(h), log(w))]. Class-specific
bbox refinments.(200,8,delta) only positive has delta , negative is zero
"""
2.1.6 model.mold_image
图片减去均值
def mold_image(images, config):
"""Takes RGB images with 0-255 values and subtraces
the mean pixel and converts it to float. Expects image
colors in RGB order.
"""
2.1.7 model.unmold_image
图片加上均值
def unmold_image(normalized_images, config):
"""Takes a image normalized with mold() and returns the original."""
以上 inspect_data.ipynb
2.1.8 class MaskRCNN()
def init(self, mode, config, model_dir)
def __init__(self, mode, config, model_dir):
"""
mode: Either "training" or "inference"
config: A Sub-class of the Config class
model_dir: Directory to save training logs and trained weights
"""
def build(self, mode, config)
# 构建 backbone
def build(self, mode, config):
"""Build Mask R-CNN architecture.
input_shape: The shape of the input image.
mode: Either "training" or "inference". The inputs and
outputs of the model differ accordingly.
"""
backbone

rpn

注意:此图有中 class 和 bbox regression 两条分支的 channels 由如下方式的确定,
r
a
t
i
o
∗
s
c
a
l
e
∗
2
ratio*scale*2
ratio∗scale∗2 和
r
a
t
i
o
∗
s
c
a
l
e
∗
4
ratio*scale*4
ratio∗scale∗4 per feature map in feature pyramid(所以原版 faster rcnn 中对应着
18
=
3
∗
3
∗
2
18 = 3*3*2
18=3∗3∗2 和
36
=
3
∗
3
∗
4
36 = 3*3*4
36=3∗3∗4)
修正:bbox regression 分支的最后一个激活函数,不是 softmax 的,是 linear 的
fpn

rpn到头部之间(26W-6000-2000)
排序,6000,bbox regression、clip、normalize、nms 到 2000
- 注意输出的proposal 进行了归一化(除以[h,w,h,w]—1024)

rpn到头部之间(2000-200)
trim,抽样
- 注意gt_boxes 之前做过归一化处理((除以[h,w,h,w])—1024)
- 注意delta算出来后,需要归一化处理,除以
RPN_BBOX_STD_DEV

2.1.9 model.build_rpn_model
eg: build_rpn_model(1, 3, 256)
keras.models.Model([input_feature_map],[rpn_class_logits,rpn_probs,rpn_bbox],name='rpn_model')
- input_feature_map: [batch,?,?,256], P2, P3, P4, P5, P6
- rpn_class_logits: [batch, h*w*scales*ratios, 2(fg/bg)]
- rpn_probs: [batch, h*w*scales*ratios, 2(fg/bg)]
- rpn_bbox: [batch, h*w*scales*ratios, 4 ( dy,dx,log(dh),log(dw) )]
def build_rpn_model(anchor_stride, anchors_per_location, depth):
"""Builds a Keras model of the Region Proposal Network.
It wraps the RPN graph so it can be used multiple times with shared
weights.
anchors_per_location: number of anchors per pixel in the feature map
anchor_stride: Controls the density of anchors. Typically 1 (anchors for
every pixel in the feature map), or 2 (every other pixel).
depth: Depth of the backbone feature map.
Returns a Keras Model object. The model outputs, when called, are:
rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, W, W, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
"""
里面调用 2.1.11 model.rpn_graph
2.1.10 model.rpn_graph
- feature_map: [batch, height, width, 256]
- anchors_per_location:3
- anchor_stride:1
def rpn_graph(feature_map, anchors_per_location, anchor_stride):
"""Builds the computation graph of Region Proposal Network.
feature_map: backbone features [batch, height, width, depth]
anchors_per_location: number of anchors per pixel in the feature map
anchor_stride: Controls the density of anchors. Typically 1 (anchors for
every pixel in the feature map), or 2 (every other pixel).
Returns:
rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, W, W, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
"""
2.1.11 class ProposalLayer()
ProposalLayer,26W+ to 2000
里面是RPN的 proposal 到 second stage 的中间选框过程,需要注意的是,if not config.USE_RPN_ROIS,则就是90%的 ground truth 九宫格,配合10%的全图随机产生!
class ProposalLayer(KE.Layer):
"""Receives anchor scores and selects a subset to pass as proposals
to the second stage. Filtering is done based on anchor scores and
non-max suppression to remove overlaps. It also applies bounding
box refinment detals to anchors.
Inputs:
rpn_probs: [batch, anchors, (bg prob, fg prob)]
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
Returns:
Proposals in normalized coordinates [batch, rois, (y1, x1, y2, x2)]
"""
def call(self, inputs): # ([rpn_class, rpn_bbox]):
XXX
XXX
XXX
def nms(normalized_boxes, scores):
XXX
def compute_output_shape(self, input_shape):
XXX
26万 → 6000(top scores) → bbox regression (delta) → bbox clip (把anchor限制在window内)→ normalized(四个分别除以(h,w,h,w))→ NMS
引入 non-maximum suppression 的目的在于:根据事先提供的 score 向量,以及 regions(由不同的 bounding boxes,矩形窗口左上和右下点的坐标构成) 的坐标信息,从中筛选出置信度较高的 bounding boxes。
其基本操作流程如下:
- 首先,计算每一个 bounding box 的面积:
(x2-x1+1)x(y2-y1+1) - 根据 scores 进行排序(一般从小到大),将 score 最大的bounding box置于队列,接下来计算其余 bounding box 与当前 score 最大的 bounding box 的 IoU,抑制(忽略也即去除)IoU大于设定阈值(这里设置为了0.7)的 bounding box;
- 重复以上过程,直至候选 bounding boxes 为空;
tf.image.non_max_suppression 例子
tf.image.non_max_suppression
2.1.12 model.apply_box_deltas_graph
def apply_box_deltas_graph(boxes, deltas):
"""Applies the given deltas to the given boxes.
boxes: [N, 4] where each row is y1, x1, y2, x2
deltas: [N, 4] where each row is [dy, dx, log(dh), log(dw)]
"""
2.1.13 model.clip_boxes_graph
window = (top_pad, left_pad, h + top_pad, w + left_pad) 表示原图在缩放+padding后图片(1024*1024)中的坐标
把越界的boxes修剪一下
就是 取anchor的4个坐标与window的右下的最小值,然后取4个坐标与window左上的最大值
def clip_boxes_graph(boxes, window):
"""
boxes: [N, 4] each row is y1, x1, y2, x2
window: [4] in the form y1, x1, y2, x2
"""

y1 = tf.maximum(tf.minimum(y1, wy2), wy1)
x1 = tf.maximum(tf.minimum(x1, wx2), wx1)
y2 = tf.maximum(tf.minimum(y2, wy2), wy1)
x2 = tf.maximum(tf.minimum(x2, wx2), wx1)
2.1.14 model.parse_image_meta_graph
把meta拆分开
def parse_image_meta_graph(meta):
"""Parses a tensor that contains image attributes to its components.
See compose_image_meta() for more details.
meta: [batch, meta length] where meta length depends on NUM_CLASSES
"""
return [image_id, image_shape, window, active_class_ids]
2.1.15 class DetectionTargetLayer()
rpn→head:2000 选 200,并按照 batch 分好
rois, target_class_ids, target_bbox =\
DetectionTargetLayer(config, name="proposal_targets")([
target_rois, input_gt_class_ids, gt_boxes])
class DetectionTargetLayer(KE.Layer):
"""Subsamples proposals and generates target box refinment, class_ids,
and masks for each.
Inputs:
proposals: [batch, N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs. [batch,100]
gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized
coordinates.[batch,100,4]
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
rois: [batch, TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized
coordinates [batch,200,4]
target_class_ids: [batch, TRAIN_ROIS_PER_IMAGE]. Integer class IDs.
target_deltas: [batch, TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw)]
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
def __init__(self, config, **kwargs):
XXX
def call(self, inputs):
XXX
def compute_output_shape(self, input_shape):
XXX
调用 detection_targets_graph
2.1.16 model.detection_targets_graph
return
- roi:positive+negative≤200,不足 padding [0,0,0,0],比例 1:2
- roi_gt_class_ids: only positive≤200,不足 padding 0
- deltas: only positive≤200,不足 padding [0,0,0,0]
def detection_targets_graph(proposals, gt_class_ids, gt_boxes, config):
"""Generates detection targets for one image. Subsamples proposals and
generates target class IDs, bounding box deltas, and masks for each.
Inputs:
proposals: [N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals. (2000,4)
gt_class_ids: [MAX_GT_INSTANCES] int class IDs (100,)
gt_boxes: [MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized coordinates. (100,4)
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates (200,4)
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded. (200,)
deltas: [TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw))] (200,4)
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
调用 trim_zeros_graph
2.1.17 model.trim_zeros_graph
boxes[no_zeros], 把不为[0,0,0,0]的 boxes 选出来
def trim_zeros_graph(boxes, name=None):
"""Often boxes are represented with matricies of shape [N, 4] and
are padded with zeros. This removes zero boxes.
boxes: [N, 4] matrix of boxes.
non_zer
2.1.18 model.overlaps_graph
计算 proposal 与 ground truth 的 IoU,输出 (num_proposal,num_gt)
intersection 就是两个bbox 的 max(max(左上),0)和 max(min(右下),0),外层 max 是 intersection为0 的情况

def overlaps_graph(boxes1, boxes2):
"""Computes IoU overlaps between two sets of boxes.
boxes1, boxes2: [N, (y1, x1, y2, x2)].
"""
c = tf.reshape(tf.tile(tf.expand_dims(boxes1, 1),
[1, 1, tf.shape(boxes2)[0]]), [-1, 4])
# (num_proposal*num_gt,4) 复制的时候num_proposal各行一一复制
d = tf.tile(boxes2, [tf.shape(boxes1)[0], 1])
# (num_proposal*num_gt,4) # 复制的时候,num_gt整体一起复制
c tensor 变化过程
(num_proposal, 1, 4)
(num_proposal, 1, 4* num_gt)
(num_proposal* num_gt, 4)
eg:
boxes1=tf.constant([[ 1., 2., 3., 4.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
boxes2=tf.constant([[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],])
a = tf.expand_dims(boxes1, 1)
with tf.Session() as sess:
print ("tf.expand_dims:\n",sess.run(a),"\n")
b = tf.tile(tf.expand_dims(boxes1, 1),
[1, 1, tf.shape(boxes2)[0]])
with tf.Session() as sess:
print ("tf.tile:\n",sess.run(b),"\n")
c = tf.reshape(tf.tile(tf.expand_dims(boxes1, 1),
[1, 1, tf.shape(boxes2)[0]]), [-1, 4])
with tf.Session() as sess:
print ("tf.reshape:\n",sess.run(c),"\n")
d = tf.tile(boxes2, [tf.shape(boxes1)[0], 1])
with tf.Session() as sess:
print (sess.run(d),"\n")
output
tf.expand_dims:
[[[ 1. 2. 3. 4.]]
[[ 4. 5. 6. 7.]]
[[ 8. 9. 10. 11.]]]
tf.tile:
[[[ 1. 2. 3. 4. 1. 2. 3. 4.]]
[[ 4. 5. 6. 7. 4. 5. 6. 7.]]
[[ 8. 9. 10. 11. 8. 9. 10. 11.]]]
tf.reshape:
[[ 1. 2. 3. 4.]
[ 1. 2. 3. 4.]
[ 4. 5. 6. 7.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[ 8. 9. 10. 11.]]
[[1. 1. 1. 1.]
[2. 2. 2. 2.]
[1. 1. 1. 1.]
[2. 2. 2. 2.]
[1. 1. 1. 1.]
[2. 2. 2. 2.]]
2.1.19 model.fpn_classifier_graph
调用 PyramidROIAlign
def fpn_classifier_graph(rois, feature_maps,
image_shape, pool_size, num_classes):
"""Builds the computation graph of the feature pyramid network classifier
and regressor heads.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from diffent layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
image_shape: [height, width, depth]
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
Returns:
logits: [N, NUM_CLASSES] classifier logits (before softmax) (?,200,8),
probs: [N, NUM_CLASSES] classifier probabilities (?, 200, 8)
bbox_deltas: [N, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes (?, 200, 8, 4)
"""
2.1.20 class PyramidROIAlign()
RPN的 proposal(RoI)做 ROIAlign,核心操作 tf.crop_and_resize
涉及到论文《Feature Pyramid Networks for Object Detection》中 Feature Pyramid Networks for Fast RCNN(根据roi大小,映射到不同特征图上接头部—second stage)
论文公式如下,
k
0
=
4
,
w
∗
h
k_0 = 4,w*h
k0=4,w∗h 是映射到原图 ROI 的大小,对应到代码中是由 roi 计算出h,w后乘上1024(映射回原图)
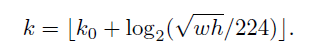
eg 224 映射到 P 4 P_4 P4,也即 224 / 2 4 = 14 224/2^4 = 14 224/24=14
映射伪代码,确保在 P 2 − P 5 P_2-P_5 P2−P5 之间
min(max(2,4 + round( l o g 2 w ⋅ h 224 × 1024 log_{2}^{\frac{\sqrt{w\cdot h}}{224}\times 1024} log2224w⋅h×1024)),5)
注意论文中是向下取整,这里是四舍五入
448 P 5 P_5 P5(边长[317-])
224 P 4 P_4 P4(边长[159,316])
112 P 3 P_3 P3(边长[80,158])
56 P 2 P_2 P2(边长[40,79])

class PyramidROIAlign(KE.Layer):
"""Implements ROI Pooling on multiple levels of the feature pyramid.
Params:
- pool_shape: [height, width] of the output pooled regions. Usually [7, 7]
- image_shape: [height, width, chanells]. Shape of input image in pixels
Inputs:
- boxes: [batch, num_boxes, (y1, x1, y2, x2)] in normalized
coordinates. Possibly padded with zeros if not enough
boxes to fill the array. (batch,200,4)
- Feature maps: List of feature maps from different levels of the pyramid.
Each is [batch, height, width, channels]
Output:
Pooled regions in the shape: [batch, num_boxes, height, width, channels].
The width and height are those specific in the pool_shape in the layer
constructor.
"""
def __init__(self, pool_shape, image_shape, **kwargs):
xxx
def call(self, inputs):
xxx
def compute_output_shape(self, input_shape):
xxx
这个函数操作相当于RoiPooling操作,函数原型是:
tf.crop_and_resize(image, boxes, box_ind, crop_size, method=None,
extrapolation_value=None, name=None):
参数解释:image:表示特征图,最终得到的每个proposal的特征图从这个特征图上得到,eg p2,p3,p4,p5
boxes:表示每个proposal的坐标(N,4)(相对坐标)
box_ind:表示proposal是来自mini_batch中的哪一张图片(N,),[0,0,0,0,0,0,0,0,1,1,1,1,1,1……]
crop_size:表示Roi_pooling之后的大小
剩余的参数用默认的就行
2.1.21 model.log2_graph
log x/ log2
def log2_graph(x):
"""Implementatin of Log2. TF doesn't have a native implemenation."""
2.1.22 rpn_class_loss_graph
rpn_class_loss_graph(input_rpn_match, rpn_class_logits)
- -1:negative
- 0:neutral
- 1:positive
总结一下,就是把 -1,0,1 中的 0 去掉,-1,1 重新归并成 0,1,rpn_class_logits 和 rpn_match 都是如此!然后计算 logits 与 gt 的交叉熵
def rpn_class_loss_graph(rpn_match, rpn_class_logits):
"""RPN anchor classifier loss.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_class_logits: [batch, anchors, 2]. RPN classifier logits for FG/BG.
"""
最后算 loss 的时候代码为 K.sparse_categorical_crossentropy,里面会调用 tf.nn.sparse_softmax_cross_entropy_with_logits(),参考
【TensorFlow】关于tf.nn.sparse_softmax_cross_entropy_with_logits()
logits 2列(fg/bg),gt 1列,先计算 logits 每行两列的 softmax,然后用 fg 的 softmax 结果与 gt 算交叉熵
2.1.23 rpn_bbox_loss_graph
核心代码为 smooth_L1,注意一个操作,就是每个图片的 ground truth,要根据 rpn 产生的 positive anchor 数量来定,也即 Trim target bounding box deltas to the same length as rpn_bbox,反正不担心 gt ,gt 不是 positive 的时候都补为0了!
def rpn_bbox_loss_graph(config, target_bbox, rpn_match, rpn_bbox):
"""Return the RPN bounding box loss graph.
config: the model config object.
target_bbox: [batch, max positive anchors, (dy, dx, log(dh), log(dw))].
Uses 0 padding to fill in unsed bbox deltas.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
"""


2.1.24 batch_pack_graph(x, counts, num_rows):
def batch_pack_graph(x, counts, num_rows):
"""Picks different number of values from each row
in x depending on the values in counts.
"""
outputs = []
for i in range(num_rows): # 对一个 gpu 的每个图片
outputs.append(x[i, :counts[i]]) # 选 batch,然后这个 batch有多少 positive
return tf.concat(outputs, axis=0)
被调用
target_bbox = batch_pack_graph(target_bbox, batch_counts,
config.IMAGES_PER_GPU)
batch_counts 表示每个 batch 中有多少 positive 的 rpn_bbox,config.IMAGES_PER_GPU 根据 GPU 显存大小设置,target_bbox 是 rpn 的 ground truth,里面是 delta,(?,26w,4),仅 positive 才有数值。
每张图 rpn 有多少 positive,就从 gt 选多少positive
2.1.25 mrcnn_class_loss_graph
计算头部的分类损失
def mrcnn_class_loss_graph(target_class_ids, pred_class_logits,
active_class_ids):
"""Loss for the classifier head of Mask RCNN.
target_class_ids: [batch, num_rois]. Integer class IDs. Uses zero
padding to fill in the array. 注意这里是数值标签,不是one-hot标签
pred_class_logits: [batch, num_rois, num_classes] eg [2,200,8]
active_class_ids: [batch, num_classes]. Has a value of 1 for
classes that are in the dataset of the image, and 0
for classes that are not in the dataset. 全部激活的话就都是1
"""
tensorflow 中计算 one-hot 与 logits 的loss 用 softmax_cross_entropy_with_logits,如果用数值标签(eg,0表示背景,1表示目标1,2表示目标2……n表示目标n)则用 sparse_softmax_cross_entropy_with_logits ,两者更详细的差别可以查看
TensorFlow softmax VS sparse softmax 或者 https://tensorflow.google.cn/api_docs/python/tf/losses/softmax_cross_entropy
那么 sparse_softmax_cross_entropy_with_logits 与 softmax_cross_entropy_with_logits 如何转化呢?也即数值标签 和 one-hot 标签如何转化呢?
参考 Tensorflow将标签变为one-hot形式,总结起来也就是
label = tf.one_hot(data,num_class+1)
#然后计算loss
#最后
loss = tf.reduce_mean(loss)
举个例子
import tensorflow as tf
import numpy as np
import random
list0 = []
list1 = []
for i in range(10*2):
list0.append(np.random.choice([0,1,2,3,4,5,6,7,8,9,10]))
for i in range(10*2*11):
list1.append(random.uniform(0,1))
array0 = np.array(list0)
array1 = np.array(list1)
array0 = array0.reshape([2,10]) # batch,num_rois
array1 = array1.reshape([2,10,11]) # batch,num_rois,num_classes+1
target_class_ids = tf.Variable(array0) # 数值标签
mrcnn_class_logits = tf.Variable(array1) # gt
看看数值标签的值
init = tf.initialize_all_variables() # must have if define varible
with tf.Session() as sess:
sess.run(init)
print(target_class_ids.eval())
output
[[ 9 0 6 5 4 10 8 4 6 10]
[ 5 1 0 8 3 0 7 10 1 2]]
用 sparse_softmax_cross_entropy_with_logits 计算一下loss
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=target_class_ids, logits=mrcnn_class_logits)
loss = tf.reduce_mean(loss)
with tf.Session() as sess:
sess.run(init)
print(loss.eval())
ouput 2.453343295259111
转化为 one-hot 的形式
onehot_labels = tf.one_hot(target_class_ids,11)
with tf.Session() as sess:
sess.run(init)
print(onehot_labels.eval())
output
[[[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
[[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]]
用 softmax_cross_entropy_with_logits 计算一下loss
loss = tf.nn.softmax_cross_entropy_with_logits(labels=onehot_labels, logits=mrcnn_class_logits)
loss = tf.reduce_mean(loss)
with tf.Session() as sess:
sess.run(init)
print(loss.eval())
output 2.453343295259111
如果要用 label smoothing 对 loss 进行修改,则可调用 tf.losses.softmax_cross_entropy,
同样的,该 loss 输入需要 one-hot label.(结果不用 reduce_mean)
tf.losses.softmax_cross_entropy(
onehot_labels,
logits,
weights=1.0,
label_smoothing=0,
scope=None,
loss_collection=tf.GraphKeys.LOSSES,
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
)
https://tensorflow.google.cn/api_docs/python/tf/losses/softmax_cross_entropy
2.1.26 mrcnn_bbox_loss_graph(target_bbox, target_class_ids, pred_bbox):
def mrcnn_bbox_loss_graph(target_bbox, target_class_ids, pred_bbox):
"""Loss for Mask R-CNN bounding box refinement.
target_bbox: [batch, num_rois, (dy, dx, log(dh), log(dw))]
target_class_ids: [batch, num_rois]. Integer class IDs.数值标签
pred_bbox: [batch, num_rois, num_classes, (dy, dx, log(dh), log(dw))]
"""
2.1.27 class DetectionLayer
输入为 rpn_roi,mrcnn_class,mrcnn_bbox,inptut_image_meta
class DetectionLayer(KE.Layer):
"""Takes classified proposal boxes and their bounding box deltas and
returns the final detection boxes.
Returns:
[batch, num_detections, (y1, x1, y2, x2,class_id, class_score)] in pixels
"""
里面最核心的操作为 refine_detections
2.1.28 refine_detections(rois[b], mrcnn_class[b], mrcnn_bbox[b], window[b], self.config))
取 softmax 后最大的类别,踢去背景,剔除分数 <0.7 的, 然后对每一个类别做阈值为 0.3 的 NMS,然后截选出DETECTION_MAX_INSTANCES 个样本!!!
def refine_detections(rois, probs, deltas, window, config):
"""Refine classified proposals and filter overlaps and return final
detections.
Inputs:
rois: [N, (y1, x1, y2, x2)] in normalized coordinates
probs: [N, num_classes]. Class probabilities.
deltas: [N, num_classes, (dy, dx, log(dh), log(dw))]. Class-specific
bounding box deltas.
window: (y1, x1, y2, x2) in image coordinates. The part of the image
that contains the image excluding the padding.
Returns detections shaped: [N, (y1, x1, y2, x2, class_id, score)]
"""
2.2 visualize.py
2.2.1 visualize.display_instances
display_instances (image, boxes, class_ids, class_names, scores=None, title="", figsize=(16, 16), ax=None)
boxes: [num_instance, (y1, x1, y2, x2, class_id)] in image coordinates.
class_ids: [num_instances]
class_names: list of class names of the dataset
scores: (optional) confidence scores for each box
figsize: (optional) the size of the image.
画图
2.2.2 visualize.random_colors
2.2.3 visualize.draw_boxes
画RPN
2.2.4 visualize.draw_rois
画ROI
以上 inspect_data.ipynb
2.3 utils.py
2.3.1 utils.resize_image
图片放大的 scale 会选择 min_dim / min(h,w)与 max_dim / max(h,w)中较小者
然后 padding 成 max_dim
def resize_image(image, min_dim=None, max_dim=None, padding=False):
"""
Resizes an image keeping the aspect ratio.
min_dim: if provided, resizes the image such that it's smaller
dimension == min_dim
max_dim: if provided, ensures that the image longest side doesn't
exceed this value.
padding: If true, pads image with zeros so it's size is max_dim x max_dim
Returns:
image: the resized image
window: (y1, x1, y2, x2). If max_dim is provided, padding might
be inserted in the returned image. If so, this window is the
coordinates of the image part of the full image (excluding
the padding). The x2, y2 pixels are not included.
scale: The scale factor used to resize the image
padding: Padding added to the image [(top, bottom), (left, right), (0, 0)]
"""
window = (top_pad, left_pad, h + top_pad, w + left_pad) 表示原图在缩放+padding后图片(1024*1024)中的坐标
2.3.2 utils.resize_bbox
def resize_bbox(bbox, scale, padding):
"""
resize the bbox to correspond to resize image.
bbox :[num_instances, (y1, x1, y2, x2)] origin
scale:the image scale times.
padding: Padding to add to the mask in the form
[(top, bottom), (left, right), (0, 0)]
return:
bbox: [num_instances, (y1, x1, y2, x2)]
"""
按照resize_image的形式,缩放bbox
2.3.3 utils.generate_pyramid_anchors
def generate_pyramid_anchors(scales, ratios, feature_shapes, feature_strides,
anchor_stride):
"""Generate anchors at different levels of a feature pyramid. Each scale
is associated with a level of the pyramid, but each ratio is used in
all levels of the pyramid.
Returns:
anchors: [N, (y1, x1, y2, x2)]. All generated anchors in one array. Sorted
with the same order of the given scales. So, anchors of scale[0] come
first, then anchors of scale[1], and so on.
"""
Anchors
[anchor_count, (y1, x1, y2, x2)]
调用
anchors = utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES,
config.RPN_ANCHOR_RATIOS,
config.BACKBONE_SHAPES,
config.BACKBONE_STRIDES,
config.RPN_ANCHOR_STRIDE)
RPN_ANCHOR_SCALES (32, 64, 128, 256, 512) = scales,特征图上框框映射回原图的大小,
RPN_ANCHOR_RATIOS = [0.5, 1, 2] = ratios # anchor的三种比例
BACKBONE_SHAPES =
[[256 256]
[128 128]
[ 64 64]
[ 32 32]
[ 16 16]] = 图片的大小(1024,1024) 除以strides,5层特征金字塔
BACKBONE_STRIDES = [4, 8, 16, 32, 64] = strides,特征图的缩放比例
RPN_ANCHOR_STRIDE = 2,特征图上框框的步长
里面调用
anchors.append(generate_anchors(scales[i], ratios, feature_shapes[i],
feature_strides[i], anchor_stride))

2.3.4 utils.generate_anchors
utils.generate_anchors(scales[i], ratios, shape[i], feature_stride[i], anchor_stride)
"""
scales: 1D array of anchor sizes in pixels. Example: [32, 64, 128,256,512]
ratios: 1D array of anchor ratios of width/height. Example: [0.5, 1, 2]
shape: [height, width] spatial shape of the feature map over which
to generate anchors.比如第一层256
feature_stride: Stride of the feature map relative to the image in pixels.
anchor_stride: Stride of anchors on the feature map. For example, if the
value is 2 then generate anchors for every other feature map pixel.
"""
2.3.5 utils.compute_overlaps
调用了utils.compute_iou(box, boxes, box_area, boxes_area):
return overlap(N(anchors),N(ground truth)),eg,一张图片产生了65472的anchors,然后有4个ground truth,计算每个anchor与4个ground truth 的 overlap(IOU),(65472,4)
def compute_overlaps(boxes1, boxes2):
"""Computes IoU overlaps between two sets of boxes.
boxes1, boxes2: [N, (y1, x1, y2, x2)].
For better performance, pass the largest set first and the smaller second.
"""
2.3.6 utils.compute_iou
overlap坐标的计算是,取y1,x1的最大值,取y2,x2的最小值
"""Calculates IoU of the given box with the array of the given boxes.
box: 1D vector [y1, x1, y2, x2]
boxes: [boxes_count, (y1, x1, y2, x2)]
box_area: float. the area of 'box'
boxes_area: array of length boxes_count.
Note: the areas are passed in rather than calculated here for
efficency. Calculate once in the caller to avoid duplicate work.
"""
2.3.7 utils.box_refinement

注意 G x 、 G y 、 P x 、 P y G_x、G_y、P_x、P_y Gx、Gy、Px、Py 是 bbox 的 center
def box_refinement(box, gt_box):
"""Compute refinement needed to transform box to gt_box.
box and gt_box are [N, (y1, x1, y2, x2)]. (y2, x2) is
assumed to be outside the box.
"""
2.3.8 utils.apply_box_deltas

这里的 d x ( P ) d_x(P) dx(P)、 d y ( P ) d_y(P) dy(P)、 d h ( P ) d_h(P) dh(P)、 d w ( P ) d_w(P) dw(P) 就是 2.3.7 中的 t x t_x tx、 t y t_y ty、 t h t_h th、 t w t_w tw
利用 deltas 把 boxes 还原
def apply_box_deltas(boxes, deltas):
"""Applies the given deltas to the given boxes.
boxes: [N, (y1, x1, y2, x2)]. Note that (y2, x2) is outside the box.
deltas: [N, (dy, dx, log(dh), log(dw))]
"""
以上 inspect_data.ipynb
2.3.9 utils.batch_slice
inputs = [scores, ix]
graph_fn = lambda x, y: tf.gather(x, y)
output: [batch, scores[ix]]
根据ix从scores中抽出相应元素,按照batch封装组合在一起
def batch_slice(inputs, graph_fn, batch_size, names=None):
"""Splits inputs into slices and feeds each slice to a copy of the given
computation graph and then combines the results. It allows you to run a
graph on a batch of inputs even if the graph is written to support one
instance only.
inputs: list of tensors. All must have the same first dimension length
graph_fn: A function that returns a TF tensor that's part of a graph.
batch_size: number of slices to divide the data into.
names: If provided, assigns names to the resulting tensors.
"""
2.3.10 utils.box_refinement_graph
def box_refinement_graph(box, gt_box):
"""Compute refinement needed to transform box to gt_box.
box and gt_box are [N, (y1, x1, y2, x2)],相同维度
"""
3 error
3.1 import keras 报错
3.2 ImportError: cannot import name ‘_obtain_input_shape’ from keras
I was downgrade keras 2.2.2 to 2.2.0, and the problem was solved.
pip install -U --pre keras==2.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
4 Reference
【1】TimeDistributed的理解和用法(keras)(★★★★★)
【2】如何下载github上的单个文件(★★)
【3】fchollet / deep-learning-models(预训练模型 ★★★★★)
【4】parap1uie-s / Keras-RFCN(RFCN ★★★★★)
【5】qubvel/classification_models(seNet、resNext ★★★★★)
【6】Keras Image Classifiers(keras no group pre-trained)
【7】titu1994/Keras-NASNet(nasnet ★★★★★)
【8】tensorflow里面用于改变图像大小的函数(★★★★★)














 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









