







免责声明
本项目仅供学习和研究使用,使用者应遵守相关法律法规,任何由使用者因违法使用所产生的后果,与本项目无关。爬虫违法违规案例
目录
话不多说,先看效果
playwright爬取豆瓣Tv和Explore页面效果演示
- 爬取目标:豆瓣Tv页面和豆瓣Explore页面
- 如果你希望爬取豆瓣电影排行榜
- 可以去看我新发布发布的博客:python爬虫:基于异步Playwright并发爬取豆瓣电影排行榜(豆瓣Chart页面),包含完整源码
完整代码已经上传到github项目,如果只考虑使用,不在乎原理的话,直接访问github项目,按照里面的简陋使用方法进行操作即可,推荐看完这篇博客,对实现原理有大致理解后再去尝试
(一)使用的包
# playwright版本
pip install playwright==1.43.0
# 安装好后你需要运行playwright install来下载对应版本的浏览器
playwright install
(二)页面分析
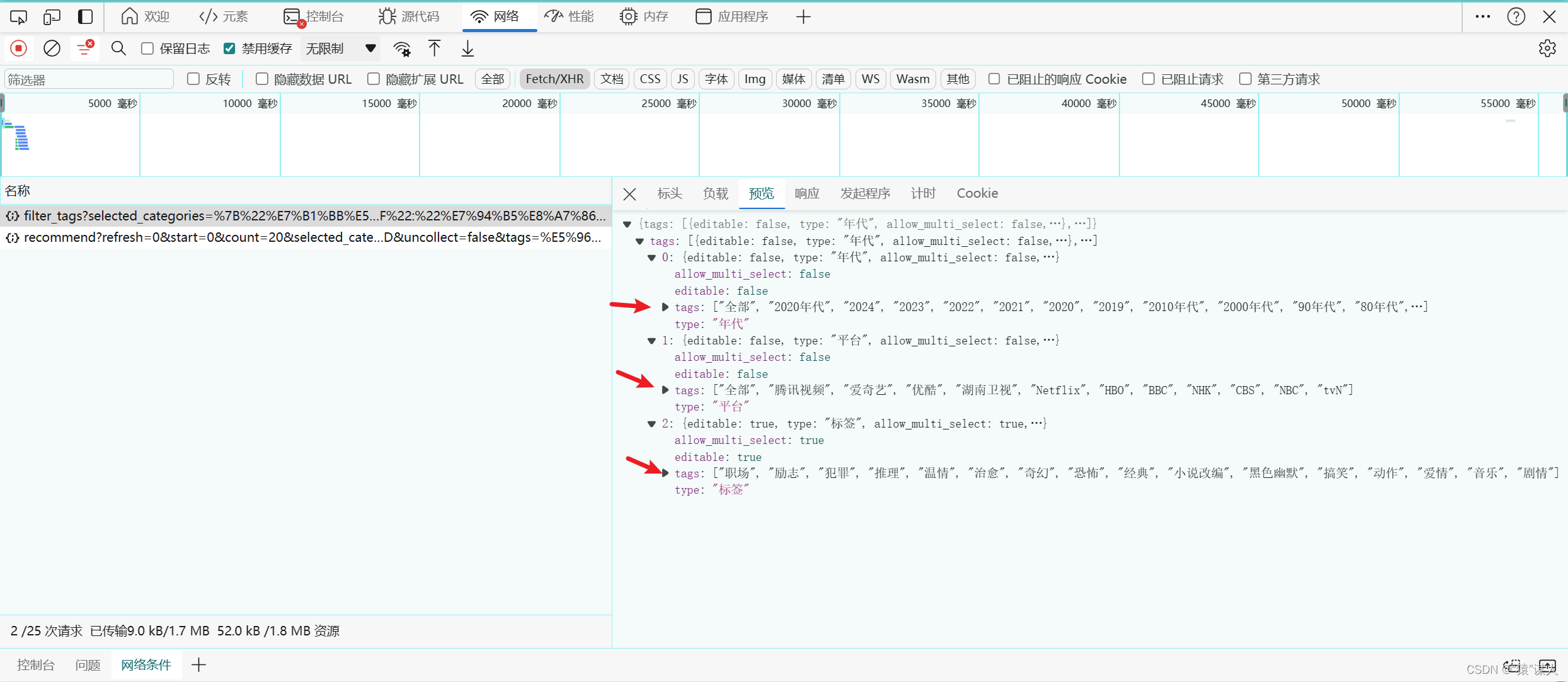
- 选择一个类型后,利用浏览器抓包,在xhr页面中获取到2个文件:
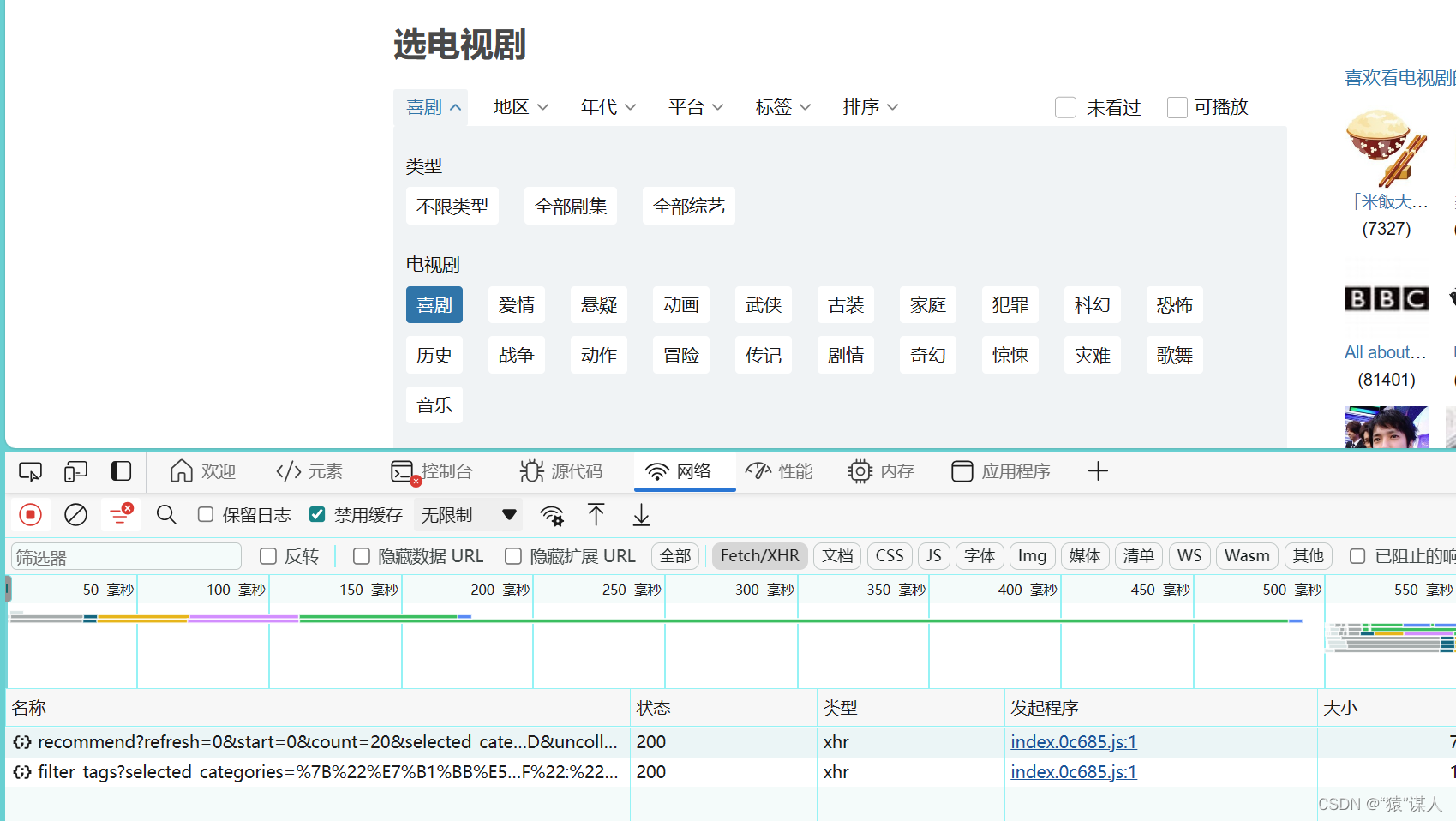
- 观察recommend?refresh文件,在items中是我们需要的电视剧/电影的信息(详情页不进行爬取!)
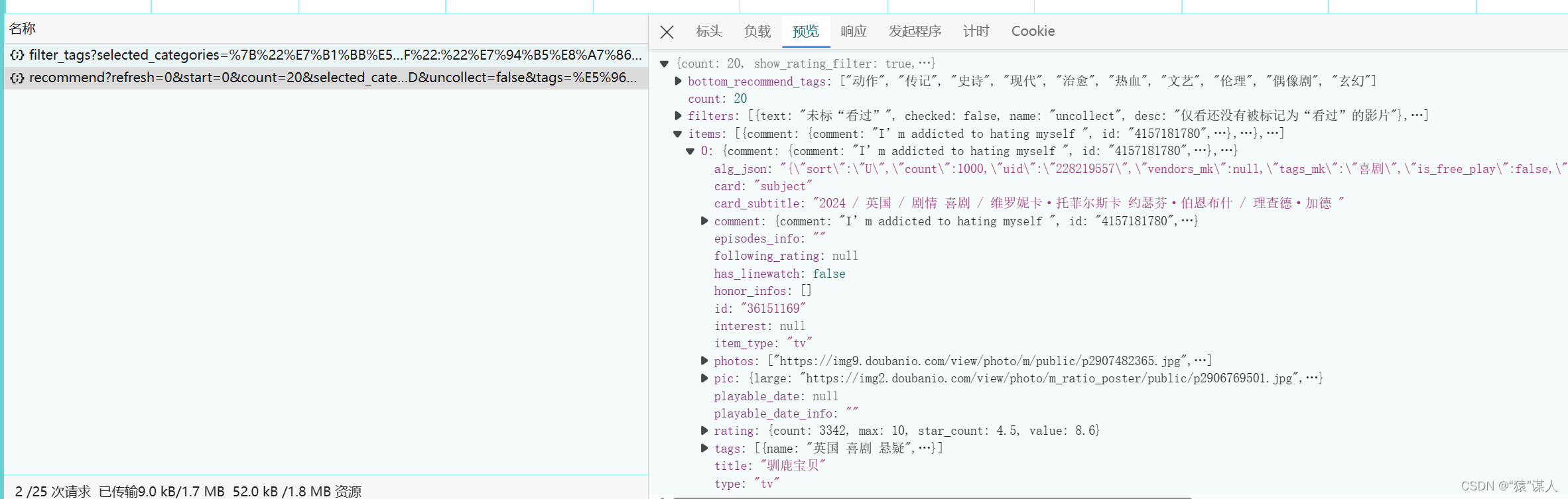
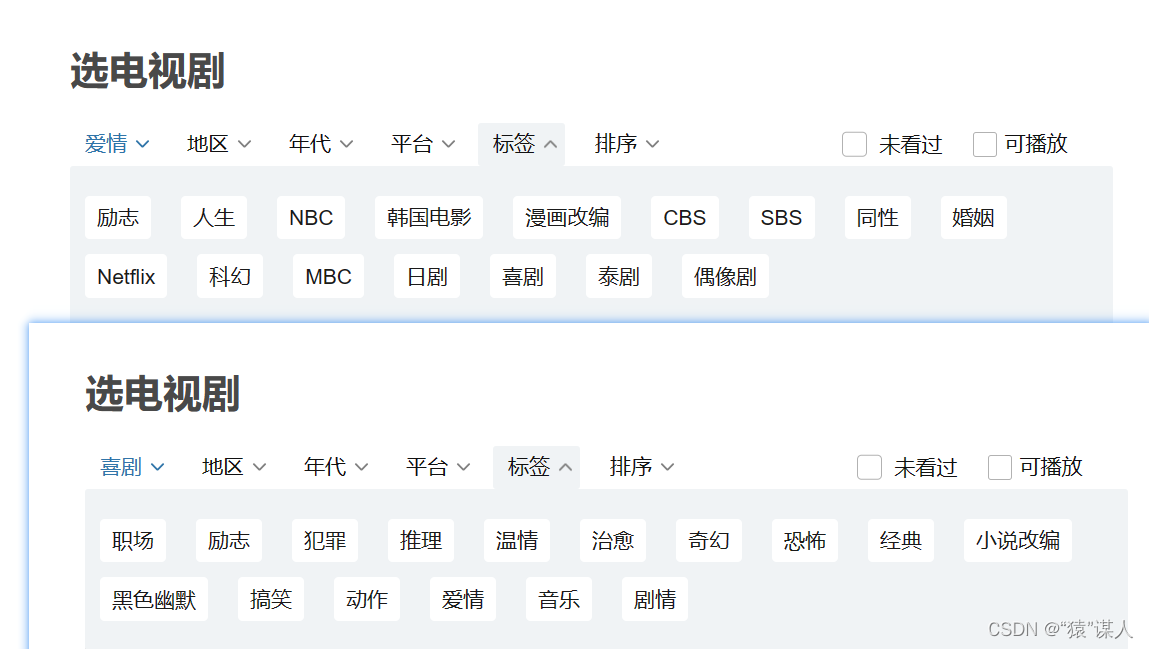
- 选择不同的类型时,地区、年代、平台(explore页面无此选项)、标签、排序,会出现变化,需要对其进行动态爬取
比如:类型选中喜剧和爱情,对应的标签是不一样的
- 地区,排序——在recommend?refresh文件中
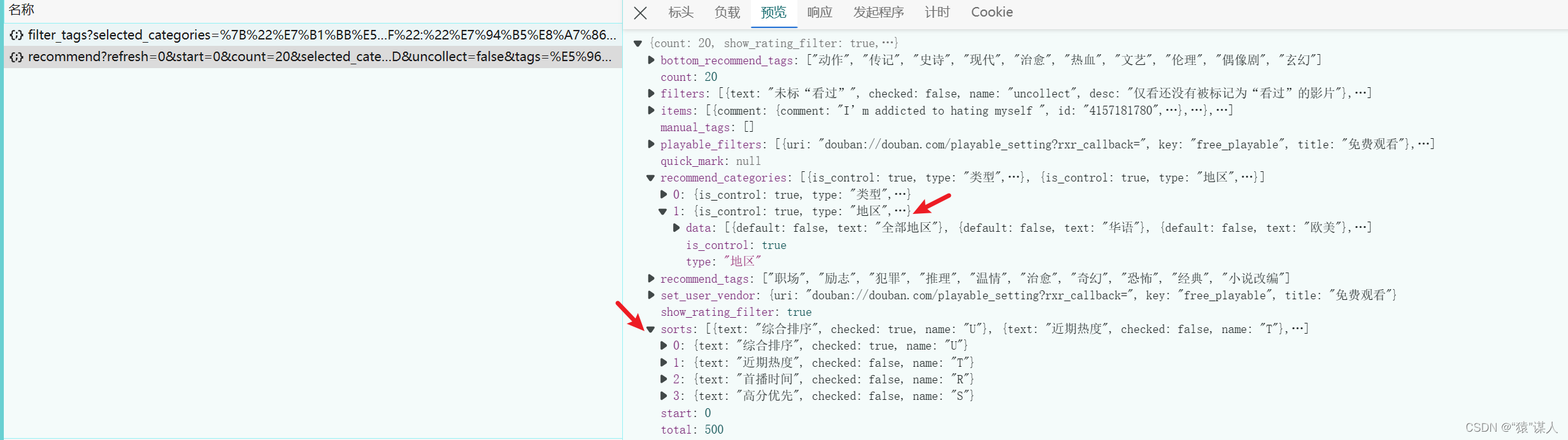
- 年代、平台、标签——在recommend/filter_tags文件中
(三)进行爬取
(1)大致构想:
- 使用异步Playwright打开浏览器,点击类型进行选择
- 选择完成后,等待recommend?refresh和recommend/filter_tags文件加载成功
- 然后动态获取,所选类型对应的:地区、年代、平台(explore页面无此选项)、标签、排序,中的内容
- 在同一类型下,选择不同年代,标签……可以爬取到不同资源
- 最后一直往下滑,点击“加载更多”的按钮,不断加载数据,直到按钮消失,或无法加载新的数据(“加载更多”的按钮存在,但items为空)
(2)具体实现:
根据以上构想,实现的代码比较长,可以分为2个类,父类用于定义一些数据,对数据进行处理并实现页面爬取之外的功能,子类用于自动化操作浏览器
注意:
- 如果爬取速度过快,豆瓣会封ip
- 使用登入过豆瓣的浏览器,进行爬取,封ip概率会小很多
- 采用了并发处理,为了避免对目标服务器造成过大压力,请勿设置过高的并发数
2.1打开浏览器
# 打开浏览器
async def open_browser(self): # 打开浏览器
"""
打开浏览器
"""
if await self.isSaveType(): # 如果已经爬取过目标类型
all_save = await self.getSavaJson()
if (
not all_save
): # 如果保存的分组数据已经爬取完成,列表为空,那么无需再次爬取
logging.info(f"{self.dict}已经爬取完成,无需再次爬取")
return
logging.info("打开浏览器中……")
async with async_playwright() as p:
if self.isLogin: # 如果选择登录,设置用户数据目录
self.browser = await p.chromium.launch_persistent_context(
user_data_dir=self.isLogin_user_data_path,
headless=self.isHeadless,
ignore_default_args=[
"--enable-automation"
], # 禁止弹出Chrome正在受到自动软件的控制的通知
)
else:
self.browser = await p.chromium.launch(
headless=self.isHeadless,
ignore_default_args=[
"--enable-automation"
], # 禁止弹出Chrome正在受到自动软件的控制的通知
)
logging.info(f"浏览器已经打开,即将打开页面")
await self.open_page() # 打开页面
由于异步Playwright需要在async with async_playwright() as p:的上下文管理器中启动浏览器,因此所有依赖于浏览器的后续操作都需要在此上下文范围内执行。
2.2自定义页面
# 获取一个新的页面
async def get_page(self):
"""
获取打开目标url的页面
"""
page = await self.browser.new_page()
if self.isLogin and self.isLogin_isWait:
if self.isLogin_wait_url:
await page.goto(self.isLogin_wait_url)
await asyncio.sleep(self.isLogin_wait_time)
await self.close_browser()
sys.exit()
await page.route(
"**/*.{png,jpg,jpeg,gif,svg,ico}", lambda route, request: route.abort()
) # 禁止加载图片
await page.route(
"**/*.woff2", lambda route, request: route.abort()
) # 禁止加载字体
# await page.route(
# "**/*.css", lambda route, request: route.abort()
# ) # 禁止加载CSS
# await page.route(
# "**/*.js", lambda route, request: route.abort()
# ) # 禁止加载JavaScript
await page.add_init_script( # 添加初始化脚本
'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
)
await page.goto(self.url) # 打开目标url
await page.wait_for_load_state("load") # 等待页面加载完成
# await page.wait_for_load_state("networkidle") # 等待网络空闲
await self.random_sleep()
return page
由于异步爬取过程中需要处理多个页面,将页面处理逻辑单独封装成一个函数。这样做可以提高代码的可读性和可维护性,方便对页面进行整体的处理。此页面我已经进行了一些处理,有需要可以自行修改。
2.3打开页面
# 打开页面
async def open_page(self): # 打开页面
"""
打开页面
"""
logging.info(f"打开页面:{self.url} 中……")
async def on_request(response):
if "/recommend/filter_tags" in response.url and response.status == 200:
data = await response.json()
await self.handle_tags_data(data) # 处理tags数据
if "/recommend?refresh=0&start=" in response.url and response.status == 200:
data = await response.json()
if not self.region_list:
for category in data["recommend_categories"]:
# 如果type是"地区",那么提取data中的text
if category["type"] == "地区":
for item in category["data"]:
self.region_list.append(item["text"])
# 遍历sorts列表
for sort in data["sorts"]:
# 提取text
self.sort_list.append(sort["text"])
try:
page = await self.get_page()
await asyncio.sleep(5) # 等待5秒,等待数据加载完成
page.on("response", on_request)
except Exception as e:
if self.error_count >= self.max_error_count:
logging.error(
f"打开页面出现错误:{e}\n类型:{type(e)}\n堆栈跟踪:\n{traceback.format_exc()}"
)
logging.info("错误次数过多,即将关闭浏览器")
# await self.close_browser() # 手动关闭浏览器
return
logging.error(
f"打开页面出现错误:{e}\n类型:{type(e)}\n堆栈跟踪:\n{traceback.format_exc()}"
)
logging.info("即将重新打开页面")
self.error_count += 1
await self.open_page()
return
logging.info("页面已经打开,首先获取所有的组合")
await self.trySaveAllCombinations(page) # 获取所有的组合
await page.close() # 获取后,关闭当前页面
self.all_combinations_dicts = await self.getSavaJson() # 获取保存的json数据,也就是之前获取的组合
logging.info(
f"获取所有的组合完成,即将并发[并发量:{self.CONCURRENCY}]爬取————所有组合的数据"
)
if not self.all_combinations_dicts:
logging.info(f"{self.dict}无组合,已经爬取完成,即将关闭浏览器")
# await self.close_browser() # 手动关闭浏览器
return
combinations_dicts = self.all_combinations_dicts # 取所有组合数据
tasks = [
asyncio.ensure_future(self.drop_down_selection(combinations_dict))
for combinations_dict in combinations_dicts
]
# 使用asyncio.gather并发地运行所有的任务
await asyncio.gather(*tasks)
logging.info(f"{self.dict}————已经全部获取,立即关闭浏览器,程序运行完成。")
程序主体,实现了以下功能:
- 首先打开提供的页面,等待5秒后,再为页面添加
page.on("response", on_request)功能
async def on_request(response):
if "/recommend/filter_tags" in response.url and response.status == 200:
data = await response.json()
await self.handle_tags_data(data) # 处理tags数据
if "/recommend?refresh=0&start=" in response.url and response.status == 200:
data = await response.json()
if not self.region_list:
for category in data["recommend_categories"]:
# 如果type是"地区",那么提取data中的text
if category["type"] == "地区":
for item in category["data"]:
self.region_list.append(item["text"])
# 遍历sorts列表
for sort in data["sorts"]:
# 提取text
self.sort_list.append(sort["text"])
# await self.handle_tags_data(data) # 处理tags数据
async def handle_tags_data(self, data):
"""
处理tags数据
"""
if not self.label_list:
# 遍历tags列表
for tag in data["tags"]:
# 如果type是"年代",那么提取tags的内容
if tag["type"] == "年代":
self.era_list = tag["tags"]
if tag["type"] == "平台":
self.platform_list = tag["tags"]
if tag["type"] == "标签":
self.label_list = tag["tags"]
这个功能可以抓取页面的xhr文件,用于动态获取,所选类型对应的:地区、年代、平台(explore页面无此选项)、标签、排序,中的内容。
2. 然后调用await self.trySaveAllCombinations(page)
# 获取所有的组合
async def trySaveAllCombinations(self, page) -> None:
"""
获取所有的组合
"""
logging.info(f"获取所有{self.dict}的组合中……")
if not await self.isSaveType():
await page.click('//div[@class="explore-sticky"]//*[text()="类型"]')
await self.random_sleep()
await page.click(f'//div[@class="explore-sticky"]//*[text()="{self.type}"]')
await page.wait_for_load_state("load") # 等待页面加载完成
await asyncio.sleep(5) # 等待5秒,等待数据加载完成
await self.saveAllCombinationsDict()
- 这个功能会先用
await self.isSaveType()检测提供的self.type的组合是否已经保存过了 - 如果不存在,在页面上点击
类型按钮,然后再点击提供的self.type类型,这时会加载选择self.type后的数据 - 而
page.on("response", on_request)功能会自动抓取到加载后的数据,然后从中提取到地区、年代、平台(explore页面无此选项)、标签、排序的数据。 - 最后调用
await self.saveAllCombinationsDict(),对抓取的数据进行保存。
# await self.saveAllCombinationsDict()
# 保存所有的组合到文件中
async def saveAllCombinationsDict(self):
"""
生成所有的组合,并保存到文件中
"""
all_list = f"""
地区:{self.region_list}
年代:{self.era_list}
平台:{self.platform_list}
标签:{self.label_list}
排序:{self.sort_list}
"""
logging.info(f"所有的列表:{all_list}")
# 将生成的组合转换为字典
all_combinations_dicts = []
if self.platform_list: # tv选择电视剧
waitSortList = ["region", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
waitSortList = ["era", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
waitSortList = ["platform", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
waitSortList = ["label", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
# waitSortList = ["era", "label", "sort"]
# await self.quickSaveCombination(waitSortList, all_combinations_dicts)
# waitSortList = ["platform", "label", "sort"]
# await self.quickSaveCombination(waitSortList, all_combinations_dicts)
else: # explore选择电影
waitSortList = ["region", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
waitSortList = ["era", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
waitSortList = ["label", "sort"]
await self.quickSaveCombination(waitSortList, all_combinations_dicts)
# waitSortList = ["era", "label", "sort"]
# await self.quickSaveCombination(waitSortList, all_combinations_dicts)
# 将数据保存到文件中
if self.url == "https://movie.douban.com/tv/":
loacl_path = f"{self.doubanWaitToSpider}/tv/{self.type}.json"
elif self.url == "https://movie.douban.com/explore":
loacl_path = f"{self.doubanWaitToSpider}/explore/{self.type}.json"
with open(loacl_path, "w", encoding="utf-8") as f:
json.dump(all_combinations_dicts, f, ensure_ascii=False, indent=4)
该功能会创建一个列表,用于储存一些数据的分组情况,对数据进行分组由await self.quickSaveCombination功能实现,并保存到列表中,完成后会将其保存到json文件,以待下次调用。
await self.quickSaveCombination代码如下:
# 快速保存组合
async def quickSaveCombination(self, waitSortList, all_combinations_dicts):
"""
快速保存组合,dict{lsdt_name: list……}
"""
# 将字典生成组合,list_name是key,list是value
dict_all = {
"region": self.region_list if "region" in waitSortList else [None],
"era": self.era_list if "era" in waitSortList else [None],
"platform": self.platform_list if "platform" in waitSortList else [None],
"label": self.label_list if "label" in waitSortList else [None],
"sort": self.sort_list if "sort" in waitSortList else [None],
}
# 生成所有的组合
all_combinations = list(
itertools.product(
dict_all["region"],
dict_all["era"],
dict_all["platform"],
dict_all["label"],
dict_all["sort"],
)
)
for combination in all_combinations:
combination_dict = {
"region": combination[0],
"era": combination[1],
"platform": combination[2],
"label": combination[3],
"sort": combination[4],
}
all_combinations_dicts.append(combination_dict)
该功能会对提供的waitSortList = ["label", "sort"],结合之前保存的数据,然后调用itertools.product()函数,用于计算迭代器的笛卡尔积。它会生成所有可能的元组对。
比如:
[
{
"region": null,
"era": null,
"platform": null,
"label": "灵异",
"sort": "高分优先"
},
{
"region": null,
"era": null,
"platform": null,
"label": "悬疑",
"sort": "综合排序"
},
{
"region": null,
"era": null,
"platform": null,
"label": "悬疑",
"sort": "近期热度"
},
……
self.all_combinations_dicts = await self.getSavaJson() # 获取保存的json数据
logging.info(
f"获取所有的组合完成,即将并发[并发量:{self.CONCURRENCY}]爬取————所有组合的数据"
)
if not self.all_combinations_dicts:
logging.info(f"{self.dict}无组合,已经爬取完成,即将关闭浏览器")
# await self.close_browser() # 手动关闭浏览器
return
await self.getSavaJson()功能会加载之前保存的json文件,获取所有保存的组合- 然后使用:
combinations_dicts = self.all_combinations_dicts # 取所有数据
tasks = [
asyncio.ensure_future(self.drop_down_selection(combinations_dict))
for combinations_dict in combinations_dicts
]
# 使用asyncio.gather并发地运行所有的任务
await asyncio.gather(*tasks)
- 首先,从
self.all_combinations_dicts中获取所有的数据组合。 - 然后,为每一个数据组合创建一个异步任务,这个任务会调用
self.drop_down_selection(combinations_dict)方法。 - 所有的异步任务被存储在
tasks列表中。 - 最后,使用
asyncio.gather(*tasks)来并发地运行所有的任务。
2.4下拉框选择
# 下拉框选择,选择类型、地区、年代、平台、标签、排序
async def drop_down_selection(self, combinations_dict):
"""
下拉框选择,选择类型、地区、年代、平台、标签、排序
"""
async with self.semaphore:
isAll = [False]
# 处理response
async def on_request(response):
"""
获取Ajax数据,并进行处理+保存数据
"""
if (
"/recommend?refresh=0&start=" in response.url
and response.status == 200
):
try:
data = await response.json()
if not data["items"]:
isAll[0] = True
return
await self.save_data(data) # 处理+保存数据
except Exception as e:
logging.error(
f"处理+保存数据出现错误:{e}\n类型:{type(e)}\n堆栈跟踪:\n{traceback.format_exc()}"
)
logging.info(
f"选择下拉框选项:type:{self.type},dict:{combinations_dict}中……"
)
try:
page = await self.get_page()
await page.click('//div[@class="explore-sticky"]//*[text()="类型"]')
await self.random_sleep()
await page.click(
f'//div[@class="explore-sticky"]//*[text()="{self.type}"]'
)
await self.random_sleep()
page.on("response", on_request) # 处理response
if combinations_dict.get("region"):
await page.click('//div[@class="explore-sticky"]//*[text()="地区"]')
await self.random_sleep()
await page.click(
f'//div[@class="explore-sticky"]//*[text()="{combinations_dict["region"]}"]'
)
await self.random_sleep()
if combinations_dict.get("era"):
await page.click('//div[@class="explore-sticky"]//*[text()="年代"]')
await self.random_sleep()
await page.click(
f'//div[@class="explore-sticky"]//*[text()="{combinations_dict["era"]}"]'
)
await self.random_sleep()
if combinations_dict.get("platform"):
await page.click('//div[@class="explore-sticky"]//*[text()="平台"]')
await self.random_sleep()
await page.click(
f'//div[@class="explore-sticky"]//*[text()="{combinations_dict["platform"]}"]'
)
await self.random_sleep()
if combinations_dict.get("label"):
await page.click('//div[@class="explore-sticky"]//*[text()="标签"]')
await self.random_sleep()
await page.click(
f'//div[@class="explore-sticky"]//*[text()="{combinations_dict["label"]}"]'
)
await self.random_sleep()
if combinations_dict.get("sort"):
await page.click('//div[@class="explore-sticky"]//*[text()="排序"]')
await self.random_sleep()
await page.click(
f'//div[@class="explore-sticky"]//*[text()="{combinations_dict["sort"]}"]'
)
await self.random_sleep()
except Exception as e:
if self.error_count >= self.max_error_count:
logging.error(
f"选择下拉框选项出现错误:{e}\n类型:{type(e)}\n堆栈跟踪:\n{traceback.format_exc()}"
)
logging.info("错误次数过多,即将关闭当前页面")
await page.close()
return
logging.error(
f"选择下拉框选项出现错误:{e}\n类型:{type(e)}\n堆栈跟踪:\n{traceback.format_exc()}"
)
logging.info("即将关闭页面,重新打开后,进行下拉选择")
await page.close()
self.error_count += 1
await self.drop_down_selection(combinations_dict) # 重新选择选项
return
await self.slip_down(
page=page, isAll=isAll, combinations_dict=combinations_dict
) # 向下滑动页面
根据提供的字典数据,依次选择对应的地区、年代、平台(explore无此选项)和标签。
每个选择操作都是通过点击页面上对应的元素来实现的,这里使用了xpath,如果有需要,可以自行修改。
在每次点击操作之后,都会等待一段随机的时间。
选择完成后,调用await self.slip_down进行下滑,并点击“加载更多”按钮,实现数据加载。
2.5数据获取
# 向下滑动页面
async def slip_down(self, page, isAll, combinations_dict):
"""
向下滑动页面,加载数据
"""
try:
while True:
# 创建一个 Locator 对象
load_more_button = page.locator("text=加载更多")
# 检查按钮是否存在
if await load_more_button.count() > 0:
# 按钮存在,可以执行操作
await load_more_button.focus(timeout=4000)
await self.random_sleep()
await load_more_button.click(timeout=8000)
await self.random_sleep()
await load_more_button.focus(timeout=4000)
else:
break
if isAll[0]:
break
except Exception as e:
pass
finally:
logging.info(f"组合:{combinations_dict}————已全部获取")
await self.popOneCombination(combinations_dict)
isAll[0] = False
try:
# await page.wait_for_load_state("load") # 等待页面加载完成
await asyncio.sleep(1) # 延迟关闭页面,防止response未完成
await page.close()
except Exception as e:
logging.error(
f"页面关闭时出现错误:{e}\n类型:{type(e)}\n堆栈跟踪:\n{traceback.format_exc()}"
)
2.6数据保存
# 保存爬取的json数据
async def save_data(self, data):
"""
保存爬取的json数据
"""
if not data["items"]:
return
items = data.get("items")
for item in items:
if not item.get("pic"):
continue
id = item.get("id") # 豆瓣id,唯一
title = item.get("title") # 名称,一般为中文名
try:
year = int(item.get("year")) # 上映年份
except Exception as e:
year = None
douban_link = f"https://movie.douban.com/subject/{id}/" # 豆瓣链接
try:
pic_normal = item.get("pic").get("normal") # 普通图片链接
except Exception as e:
pic_normal = None
try:
pic_large = item.get("pic").get("large") # 大图片链接
except Exception as e:
pic_large = None
try:
comment = item.get("comment").get("comment") # 一条评论
except Exception as e:
comment = ""
try:
score_num = int(item.get("rating").get("count")) # 评分人数
except Exception as e:
score_num = 0
try:
score = float(item.get("rating").get("value")) # 评分
except Exception as e:
score = 0.0
try:
card_subtitle = item.get("card_subtitle") # 副标题
parts = card_subtitle.split(" / ") # 分割副标题
country = parts[1].split(" ") # 国家
genres = parts[2].split(" ") # 类型
directors = parts[3].split(" ") # 导演
actors = parts[4].split(" ") # 演员
except Exception as e:
country = []
genres = []
directors = []
actors = []
try:
item_type = item.get("type") # 类型:tv或者movie
except Exception as e:
item_type = None
# 保存数据,自行选择保存方式
all_data = {
"id": id,
"标题": title,
"上映年份": year,
"豆瓣链接": douban_link,
"普通图片链接": pic_normal,
"大图片链接": pic_large,
"一条评论": comment,
"评分人数": score_num,
"评分": score,
"国家": country,
"类型": genres,
"导演": directors,
"演员": actors,
"tv or movie类型": item_type,
}
我提取了一些数据,根据需要,自行实现数据储存的功能(适合有python基础的人学习,不过你都看到这了,应该有基础吧?),数据量很大,非常推荐用数据库进行储存。
(四)完整代码
完整代码已经上传到github项目
这里只对主要功能,进行了分析,如果需要使用,可以去github项目上下载代码,里面有比较简陋的使用方法,但能用……该项目中的代码大多都写了注释,能理解是最好的。
第一次写博客,如有不好,请多见谅……















 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









