







随着人工智能技术的不断发展,人工智能作曲已经成为可能。现有的神经网络作曲方法,主要是基于循环神经网络,变分自动编码器或生成对抗网络实现的。其中,RNN是专门处理序列数据的网络,但是标准RNN无法解决长期依赖问题。Hochreiter和Schmidhuber在标准RNN的基础上进行了改进,提出了长短时记忆网络(LSTM),很好地解决了长期依赖问题。
本次实验通过LSTM实现了一个能自动生成音乐的作曲机,以一首莫扎特的Krebs乐曲为训练数据,生成了数曲风格类似,还算动听的音乐。实验主要分为五大步骤,分别为MIDI音乐文件的解析,数据集的准备,神经网络的建立,训练网络以及音乐的生成。本实验采用三通道拼接+拆分的网络结构,还通过改进的损失函数缓解了模型的过拟合问题。
实验环境:Python3.8,torch 1.11.0+cu113,mido1.2.10,代码在Google colab上运行。
一、网络简介
1、整体架构
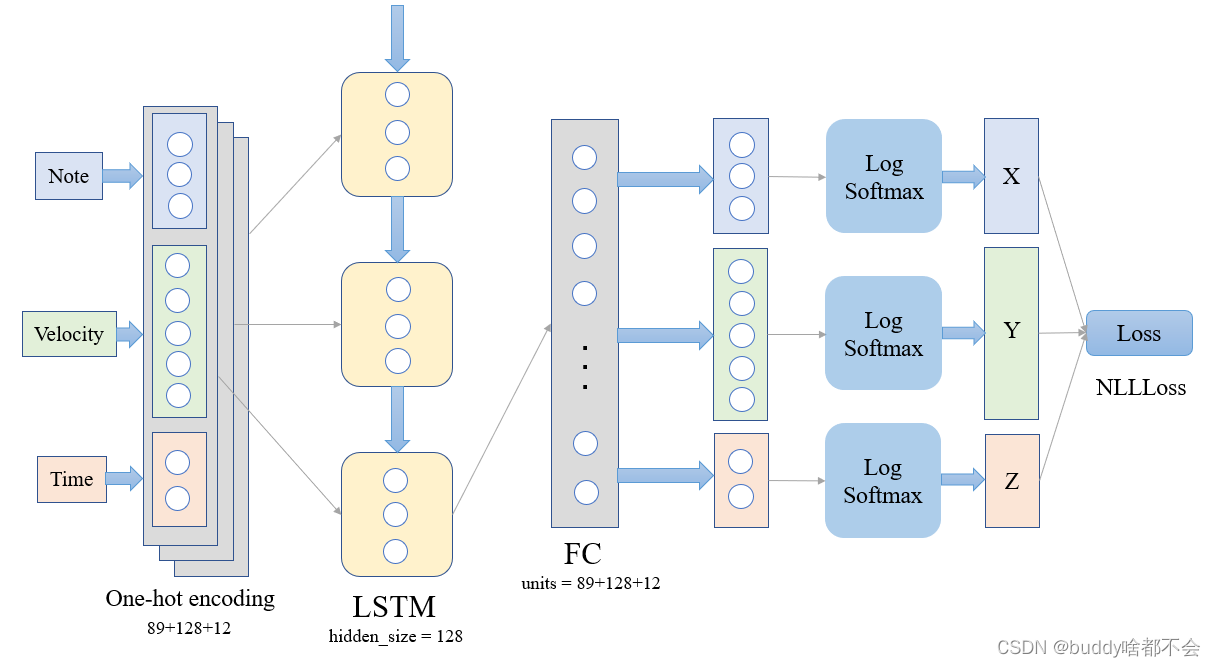
网络的输入由音符、速度、时间三个编码后的向量拼接而成,经过一层LSTM和一层全连接层,三个分量被重新切分开,分别进行LogSoftmax并计算损失,这种三通道拼接+拆分的方法有利于模型捕获不同序列之间的关系。
2、LSTM结构
LSTM的关键是细胞状态Ct,也就是图中顶端水平线上传送的向量。LSTM可以通过“门”结构对细胞单元中的信息进行删除或添加,门是一个可以让信息选择性通过的结构,通常由一个sigmoid函数和一个按位乘运算组成,sigmoid函数可以理解成门开的大小,决定了信息通过量。

用LSTM自动作曲具有以下优点:1.不需要提前计算时间序列的参数;2.对时间序列数据的性质没有过多要求,适用范围较广;3.可以学习到时间序列内部复杂的规律,而不只是机械的针对某些固定因素;4.可以捕捉时间序列的长期依赖关系。
3、损失函数
实验中定义的损失函数如下,包括三个分量的损失之和,还添加了L1正则项,防止模型的过拟合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4125
4125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









