







提出一种基于虚拟对抗损失的新正则化方法, 虚拟对抗性损失被定义为每个输入数据点周围的条件标签分布对局部扰动的鲁棒性. 与对抗训练不同, VAT 方法在没有标签信息的情况下定义了对抗方向, 因此适用于半监督学习.
论文地址: Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
代码地址: https://github.com/takerum/vat_tf
vat_chainer: https://github.com/takerum/vat_chainer
期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence (2018)
任务: 分类
正则化通常为使用所谓的正则化项来扩展损失函数, 可以防止模型过拟合. 从贝叶斯的角度来看, 正则化项可以解释为一个先验分布. 大多数自然系统的输出在空间/或时间输入方面是平滑的, 可用微分方程的平滑模型进行描述. 所以, 基于这这种信念, 文中将条件标签概率约束成平滑的, 在输入 x x x 变化很小时, 输出 p ( y ∣ x ) p(y\vert x) p(y∣x) 也变化很小.
实际上, 基于平滑假设, 标签传播(label propagation)中将类标签分配给未标记的训练样本来提高分类器的性能. 此外对于神经网络(NNs), 可以通过对每个输入应用随机扰动以生成人工输入点, 保证相似的输入通过同一神经网络能得到相似的输出. 但是 NNs 存在一个缺陷, 即 NNs 很容易受到输入微小变动的影响, 当输入变动一点, 输出都会有很大的变化. 因此, 文中引入虚拟对抗的概念用于解决此问题.
1. 对抗训练
对抗训练(adversarial training)是增强神经网络鲁棒性的重要方式. 在对抗训练的过程中, 样本会被混合一些微小的扰动(改变很小, 但是很可能造成误分类), 然后使神经网络适应这种改变, 从而对对抗样本具有鲁棒性(或防御能力). 这些样本称为对抗样本, 生成对抗样本有以下几种常见方式:
- 基于梯度法: Explaining and Harnessing Adversarial Examples
- 基于超平面分类: DeepFool: a simple and accurate method to fool deep neural networks
- 对抗攻击: 在模型原始输入上添加对抗扰动, 构建对抗样本从而使模型产生错误判断的过程. 而在这一过程中, 对抗扰动的选择和产生是关键, 需要满足扰动是微小的甚至是肉眼难以观测到的, 以及添加的扰动必须有能力使得模型产生错误的输出.
Goodfellow 等人引入对抗方向, 在输入数据点处, 可以最大程度地降低模型正确分类的概率, 或者是可以最大程度地"偏离"模型预测与正确标签的方向. 与对抗方向不同, VAT 中引入虚拟对抗方向, 即使在没有标签信息的情况下, 也可以在未标记的数据点上定义虚拟对抗方向, 就好像有一个"虚拟"标签一样.
通过虚拟对抗方向的定义, 可以在不使用监督信号的情况下量化模型在每个输入点的局部各向异性. 将Local Distributional Smoothness (LDS)定义为针对虚拟对抗方向的模型基于散度的分布鲁棒性. 提出了一种新颖的训练方法, 该方法使用有效的近似值来最大化模型的似然性, 同时在每个训练输入数据点上提升模型的 LDS. 将此方法称为虚拟对抗训练(Virtual Adversarial Training, VAT).
2. VAT 方法
文中符号定义如下:
- x ∈ R I x \in R^I x∈RI, y ∈ Q y \in Q y∈Q 分别为输入向量及输出向量. 其中 I I I 为输入维度, Q Q Q 为标签空间
- p ( y ∣ x , θ ) p(y\vert x, \theta) p(y∣x,θ) 为输出分布, θ \theta θ 为参数.
- θ ^ \hat{\theta} θ^ 为某一步训练之后的模型参数.
- D l = { x l ( n ) , y l ( n ) ∣ n = 1 , … , N l } \mathcal{D}_l=\{x_l^{(n)},y_l^{(n)}\vert n=1,\dots,N_l\} Dl={xl(n),yl(n)∣n=1,…,Nl} 表示带标签数据集.
- D u l = { x u l ( m ) , y u l ( m ) ∣ m = 1 , … , N u l } \mathcal{D}_{ul}=\{x_{ul}^{(m)},y_{ul}^{(m)}\vert m=1,\dots,N_{ul}\} Dul={xul(m),yul(m)∣m=1,…,Nul} 表示不带标签数据集.
- 使用 D l \mathcal{D}_{l} Dl, D u l \mathcal{D}_{ul} Dul 训练模型 p ( y ∣ x , θ ) p(y\vert x,\theta) p(y∣x,θ).
2.1 对抗训练
adversarial training 的损失函数定义如下:
L
a
d
v
(
x
l
,
θ
)
:
=
D
[
q
(
y
∣
x
l
)
,
p
(
y
∣
x
l
+
r
a
d
v
,
θ
)
]
(1)
L_{adv}(x_l,\theta):=D[q(y\vert x_l),p(y\vert x_l+r_{adv},\theta)] \tag{1}
Ladv(xl,θ):=D[q(y∣xl),p(y∣xl+radv,θ)](1)
r
a
d
v
:
=
arg max
r
;
∣
∣
r
∣
∣
≤
ϵ
D
[
q
(
y
∣
x
l
)
,
p
(
y
∣
x
l
+
r
,
θ
)
]
(2)
r_{adv}:=\underset{r;\vert\vert r\vert\vert \leq \epsilon}{\argmax} D[q(y\vert x_l),p(y\vert x_l+r,\theta)] \tag{2}
radv:=r;∣∣r∣∣≤ϵargmaxD[q(y∣xl),p(y∣xl+r,θ)](2)
其中
D
[
p
,
p
′
]
D[p,p']
D[p,p′] 为两个分布之间的差异度量函数, 可以使用交叉熵:
−
∑
i
p
i
log
p
i
′
-\sum_ip_i\log p'_i
−∑ipilogpi′.
r
a
d
v
r_{adv}
radv 称为对抗扰动,
q
q
q 是输出标签的真实分布, 是未知的, 这个损失函数的目标就是通过参数模型
p
p
p 逼近真实分布
q
q
q. adversarial training 中
q
(
y
∣
x
,
θ
)
q(y\vert x,\theta)
q(y∣x,θ) 用的标签的 one-hot 编码.
通常, 我们无法获得精确对抗性扰动的闭式解, 不过我们可以通过式(2)中的度量
D
D
D 来线性近似
r
r
r. 当使用
L
2
L_2
L2 正则时, 对抗扰动可以通过下面式子近似:
r
a
d
v
≈
ϵ
g
∣
∣
g
∣
∣
2
(3)
r_{adv} \approx \epsilon \frac{g}{\vert\vert g \vert\vert_2} \tag{3}
radv≈ϵ∣∣g∣∣2g(3)
当使用
L
∞
L_\infty
L∞ 正则时, 对抗扰动可以通过下面式子近似:
r
a
d
v
≈
ϵ
sin
(
g
)
(4)
r_{adv} \approx \epsilon \sin(g) \tag{4}
radv≈ϵsin(g)(4)
g
=
∇
x
l
D
[
h
(
y
;
y
l
)
,
p
(
y
∣
x
l
,
θ
)
]
g= \nabla_{x_l}D[h(y; y_l),p(y\vert x_l,\theta)]
g=∇xlD[h(y;yl),p(y∣xl,θ)]
在 NNs 中
g
g
g 可通过反向传播进行计算. 从上可以看出, 对抗方法得到的扰动方向, 比随机找一个扰动更好.
2.2 虚拟对抗训练
对抗训练适用于带标签的有监督问题, 在没有那么多标签啊的 SSL 中并不是很适用, 这里便引入 VAT. 将
x
l
x_l
xl,
x
u
l
x_{ul}
xul 同时表示为
x
∗
x_*
x∗, VAT 中的损失函数如下:
D
[
q
(
y
∣
x
∗
)
,
p
(
y
∣
x
∗
+
r
q
a
d
v
,
θ
)
]
D[q(y\vert x_*),p(y\vert x_*+r_{qadv},\theta)]
D[q(y∣x∗),p(y∣x∗+rqadv,θ)]
r
q
a
d
v
:
=
arg max
r
;
∣
∣
r
∣
∣
≤
ϵ
D
[
q
(
y
∣
x
∗
)
,
p
(
y
∣
x
∗
+
r
,
θ
)
]
r_{qadv} :=\underset{r;\vert\vert r\vert\vert \leq \epsilon}{\argmax} D[q(y\vert x_*),p(y\vert x_*+r,\theta)]
rqadv:=r;∣∣r∣∣≤ϵargmaxD[q(y∣x∗),p(y∣x∗+r,θ)]
实际上我们没有关于
q
(
y
,
x
u
l
)
q(y,x_{ul})
q(y,xul) 的直接信息, 因此采取策略用
p
(
y
∣
x
,
θ
)
p(y\vert x,\theta)
p(y∣x,θ) 替换
q
(
y
,
x
)
q(y,x)
q(y,x). 如果带标签的样本比较多时,
p
(
y
∣
x
,
θ
)
p(y\vert x,\theta)
p(y∣x,θ) 会逼近
q
(
y
∣
x
)
q(y\vert x)
q(y∣x), 即用
p
(
y
∣
x
,
θ
)
p(y\vert x,\theta)
p(y∣x,θ) 生成的虚拟标签代替不知道的标签, 并根据虚拟标签计算对抗方向, 因此
q
(
y
∣
x
)
q(y\vert x)
q(y∣x) 用上一步的
p
(
y
∣
x
,
θ
^
)
p(y\vert x,\hat{\theta})
p(y∣x,θ^) 替代, 损失函数更新如下:
L
D
S
(
X
∗
,
θ
)
:
=
D
[
p
(
y
∣
x
∗
,
θ
^
)
,
p
(
y
∣
x
∗
+
r
v
a
d
v
,
θ
)
]
(5)
{\rm LDS}(X_*,\theta):=D[p(y\vert x_*,\hat{\theta}),p(y\vert x_*+r_{vadv},\theta)] \tag{5}
LDS(X∗,θ):=D[p(y∣x∗,θ^),p(y∣x∗+rvadv,θ)](5)
r
v
a
d
v
:
=
arg max
r
;
∣
∣
r
∣
∣
≤
ϵ
D
[
p
(
y
∣
x
∗
,
θ
^
)
,
p
(
y
∣
x
∗
+
r
)
]
(6)
r_{vadv} :=\underset{r;\vert\vert r\vert\vert \leq \epsilon}{\argmax} D[p(y\vert x_*,\hat{\theta}),p(y\vert x_*+r)] \tag{6}
rvadv:=r;∣∣r∣∣≤ϵargmaxD[p(y∣x∗,θ^),p(y∣x∗+r)](6)
综上, 给整个目标函数加上损失函数, 这里损失函数取平均, 最终得到完整的目标函数, 如下所示:
R
v
a
d
v
(
D
l
,
D
u
l
,
θ
)
:
=
1
N
l
+
N
u
l
∑
x
∗
∈
D
l
,
D
u
l
L
D
S
(
x
∗
,
θ
)
(7)
\mathcal{R}_{vadv}(\mathcal{D}_l,\mathcal{D}_{ul},\theta):=\frac{1}{N_l+N_{ul}}\sum_{x_*\in \mathcal{D}_l,\mathcal{D}_{ul}} {\rm LDS}(x_*,\theta) \tag{7}
Rvadv(Dl,Dul,θ):=Nl+Nul1x∗∈Dl,Dul∑LDS(x∗,θ)(7)
l
o
s
s
=
L
(
D
l
,
θ
)
+
α
R
v
a
d
v
(
D
l
,
D
u
l
,
θ
)
(8)
loss = \mathcal{L}(\mathcal{D}_l,\theta)+\alpha \mathcal{R}_{vadv}(\mathcal{D}_l,\mathcal{D}_{ul},\theta) \tag{8}
loss=L(Dl,θ)+αRvadv(Dl,Dul,θ)(8)
其中
L
(
D
l
,
θ
)
\mathcal{L}(\mathcal{D}_l,\theta)
L(Dl,θ) 为带标签数据的负对数似然函数. 整个正则化过程中, 只有两个超参数: 正则化系数:
α
\alpha
α, 对抗方向的范数约束:
ϵ
\epsilon
ϵ, 实际上, 论文中的实验将
α
\alpha
α 固定为1, 只用到了
ϵ
\epsilon
ϵ.
下图显示了 VAT 如何在二维合成数据集上进行半监督学习:
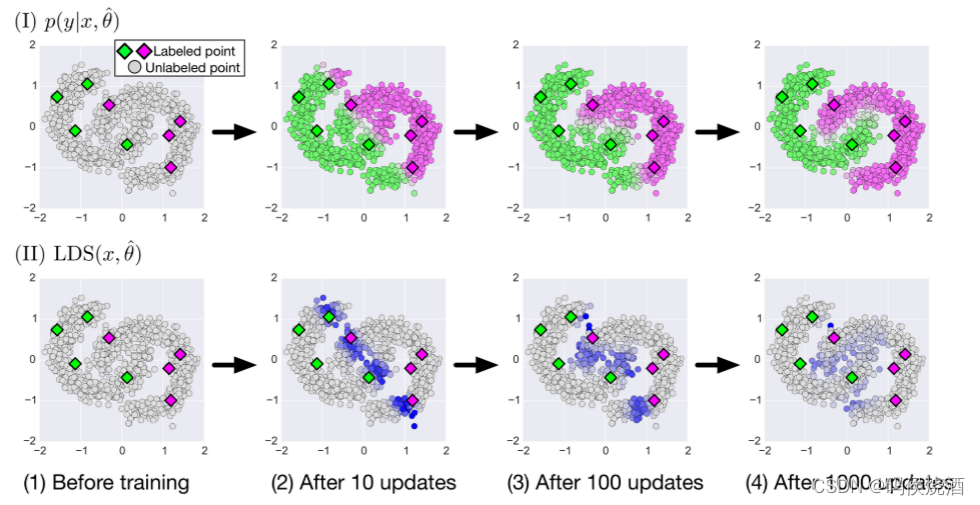
在二维空间中生成了 8 个标记数据点(
y
=
1
y = 1
y=1 和
y
=
0
y =0
y=0 分别为绿色和紫色), 以及1000个未标记数据点. 第一行 (I) 中的面板表示在算法不同阶段的未标记输入点上的预测
p
(
y
=
1
∣
x
,
θ
)
p(y=1\vert x,\theta)
p(y=1∣x,θ). 使用连续颜色来指定
p
(
y
=
1
∣
x
,
θ
)
p(y=1\vert x,\theta)
p(y=1∣x,θ) 的预测值, 其中绿色、灰色和紫色分别对应值 1.0、0.5 和 0.0. 第二行 (II) 中的面板是正则化项
L
D
S
(
x
,
θ
^
)
LDS(x,\hat{\theta})
LDS(x,θ^) 在输入点上的热图. 与灰色点相比, 蓝色点上的
L
D
S
LDS
LDS 值相对较高, 我们使用 KL 散度来选择式(5)中的
D
D
D.
2.3 快速逼近 r v a d v r_{vadv} rvadv 的方法
记
D
[
p
(
y
∣
x
∗
,
θ
^
)
,
p
(
y
∣
x
∗
+
r
,
θ
)
]
D[p(y\vert x_*,\hat{\theta}),p(y\vert x_*+r,\theta)]
D[p(y∣x∗,θ^),p(y∣x∗+r,θ)] 为
D
(
r
,
x
,
θ
^
)
D(r,x,\hat{\theta})
D(r,x,θ^). 当
r
=
0
r =0
r=0 时,
D
(
r
,
x
,
θ
^
)
D(r,x,\hat{\theta})
D(r,x,θ^) 永远为0, 所以需要对
D
(
r
,
x
,
θ
^
)
D(r,x,\hat{\theta})
D(r,x,θ^) 进行二阶泰勒展开:
D
(
r
,
x
,
θ
^
)
≈
1
2
r
T
H
(
x
,
θ
^
)
r
(9)
D(r,x,\hat{\theta}) \approx \frac{1}{2}r^{\mathrm{T}}H(x,\hat{\theta})r \tag{9}
D(r,x,θ^)≈21rTH(x,θ^)r(9)
其中
H
(
x
,
θ
^
)
=
∇
∇
r
D
(
r
,
x
,
θ
^
)
∣
r
=
0
H(x,\hat{\theta})=\nabla\nabla_rD(r,x,\hat{\theta})\vert_{r=0}
H(x,θ^)=∇∇rD(r,x,θ^)∣r=0 为海森矩阵, 简写为
H
H
H, 在这种近似下,
r
v
a
d
v
r_{vadv}
rvadv 便为
H
(
x
,
θ
^
)
H(x,\hat{\theta})
H(x,θ^) 在
ϵ
\epsilon
ϵ 下的主特征向量, 即最大特征值对应的特征向量. 计算:
r
v
a
d
v
≈
arg max
r
{
r
T
H
r
;
∣
∣
r
∣
∣
2
≤
ϵ
}
=
ϵ
u
(
x
,
θ
^
)
‾
(10)
\begin{aligned} r_{vadv} &\approx \underset{r}{\argmax}\{r^{\mathrm{T}}Hr;\vert\vert r\vert\vert_2 \leq \epsilon\} \\ &=\overline{\epsilon u(x,\hat{\theta})} \tag{10} \end{aligned}
rvadv≈rargmax{rTHr;∣∣r∣∣2≤ϵ}=ϵu(x,θ^)(10)
其中
u
(
x
,
θ
^
)
‾
=
u
(
x
,
θ
^
)
∣
∣
u
(
x
,
θ
^
)
∣
∣
2
\overline{u(x,\hat{\theta})}=\frac{u(x,\hat{\theta})}{\vert\vert u(x,\hat{\theta}) \vert\vert_2}
u(x,θ^)=∣∣u(x,θ^)∣∣2u(x,θ^) 为单位向量. 接下来, 通过幂迭代法和有限差分法用近似值来计算海森矩阵的特征向量. 令
d
d
d 为随机采样的单位向量, 如果
d
d
d 不垂直于主特征向量
u
u
u, 则进行迭代计算:
d
←
H
d
‾
(11)
d \leftarrow \overline{Hd} \tag{11}
d←Hd(11)
让
d
d
d 收敛到
u
u
u, 关于
H
H
H 也是用近似替代直接计算:
H
d
≈
∇
r
D
(
r
,
x
,
θ
^
)
∣
r
=
ξ
d
−
∇
r
D
(
r
,
x
,
θ
^
)
∣
r
=
0
ξ
=
∇
r
D
(
r
,
x
,
θ
^
)
∣
r
=
ξ
d
ξ
(12)
\begin{aligned} Hd &\approx \frac{\nabla_rD(r,x,\hat{\theta})\vert_{r=\xi d}-\nabla_rD(r,x,\hat{\theta})\vert_{r=0}}{\xi}\\ &= \frac{\nabla_rD(r,x,\hat{\theta})\vert_{r=\xi d}}{\xi} \end{aligned} \tag{12}
Hd≈ξ∇rD(r,x,θ^)∣r=ξd−∇rD(r,x,θ^)∣r=0=ξ∇rD(r,x,θ^)∣r=ξd(12)
其中
ξ
≠
0
\xi \neq 0
ξ=0, 这样就可以重复计算
d
←
∇
r
D
(
r
,
x
,
θ
^
)
∣
r
=
ξ
d
‾
d \leftarrow \overline{\nabla_rD(r,x,\hat{\theta})\vert_{r=\xi d}}
d←∇rD(r,x,θ^)∣r=ξd 来近似
r
v
a
d
v
r_{vadv}
rvadv.
r
v
a
d
v
r_{vadv}
rvadv 在形式上同式(3):
r
v
a
d
v
≈
ϵ
d
(14)
r_{vadv} \approx \epsilon d \tag{14}
rvadv≈ϵd(14)
d
=
g
∣
∣
g
∣
∣
2
d=\frac{g}{\vert\vert g \vert\vert_2}
d=∣∣g∣∣2g
g
=
∇
r
D
[
p
(
y
∣
x
,
θ
^
)
,
p
(
y
∣
x
+
r
,
θ
^
)
]
∣
r
=
ξ
d
(15)
g= \nabla_{r}D[p(y\vert x,\hat{\theta}),p(y\vert x+r,\hat{\theta})]\vert_{r=\xi d} \tag{15}
g=∇rD[p(y∣x,θ^),p(y∣x+r,θ^)]∣r=ξd(15)
迭代算法如下:

4. 实验
下图为不同
ϵ
\epsilon
ϵ 的值下: (I) 为对半监督学习性能的影响. (II)
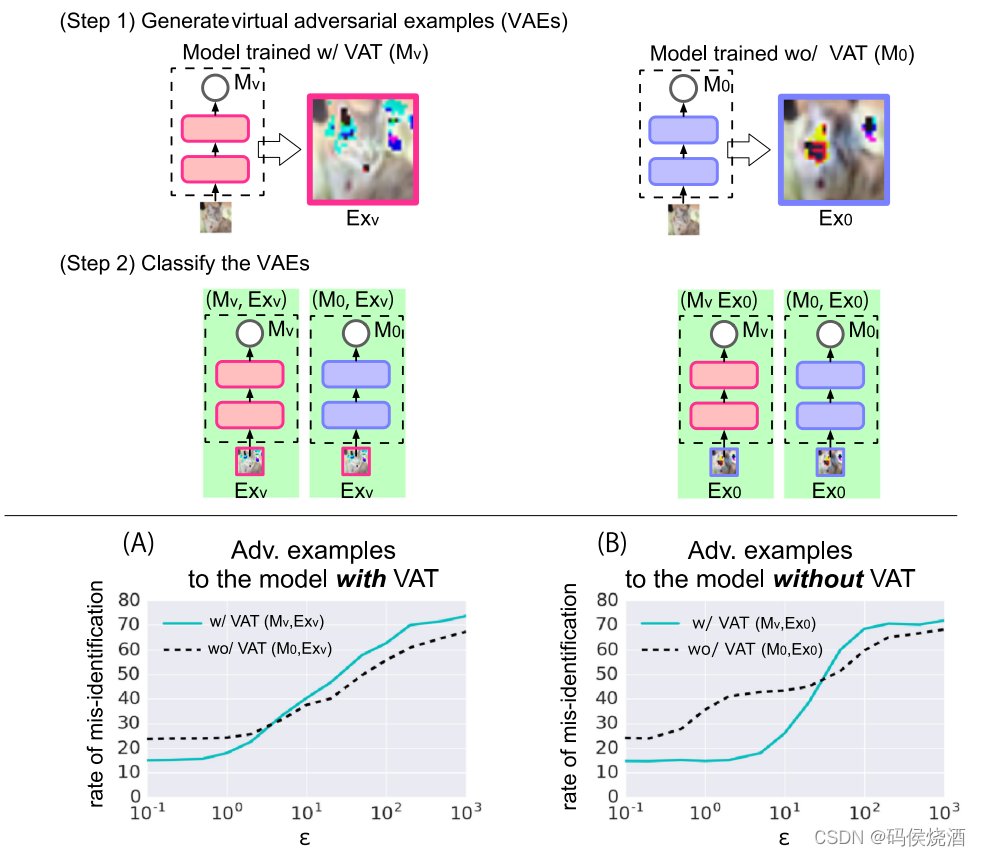
用 VAT 训练的模型生成的一组典型的虚拟对抗样本.

下图显示了两个模型(w/VAT 和 wo/VAT)识别由不同幅度的虚拟对抗扰动破坏的图像的错误率. 中间面板中的图(A)显示了对使用 VAT 训练的模型生成的虚拟对抗样本的识别错误率. 图(B)则为没有 VAT 的情况. 图(A)和(B)下方显示的示例图片是从一组图像中生成的对抗性示例, 显示了这些图像是否被使用了 VAT 模型和没有 VAT 模型正确识别.

在 MNIST数据集上超参数搜索范围:
- RPT: ϵ = [ 1.0 , 50.0 ] \epsilon=[1.0, 50.0] ϵ=[1.0,50.0].
- adversarial training (with L ∞ L_{\infty} L∞ norm constraint): ϵ = [ 0.05 , 0.1 ] \epsilon=[0.05 ,0.1] ϵ=[0.05,0.1].
- adversarial training (with L 2 L_2 L2 norm constraint): ϵ = [ 0.05 , 5.0 ] \epsilon=[0.05, 5.0] ϵ=[0.05,5.0].
- VAT: ϵ = [ 0.05 , 5.0 ] \epsilon=[0.05, 5.0] ϵ=[0.05,5.0].
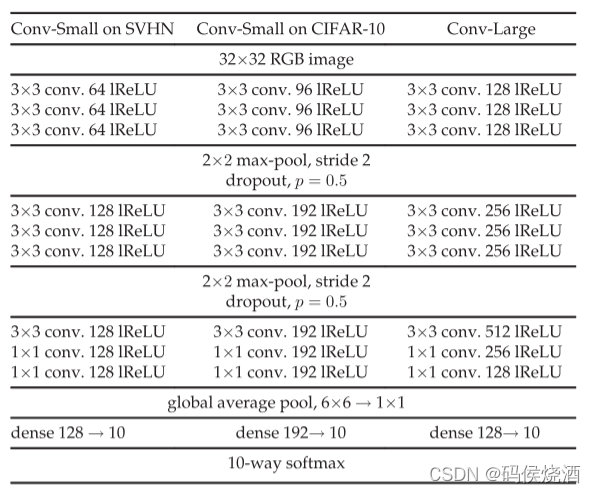
在 CIFAR-10 上的网络架构:














 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









