







Co-training 最早在 1998 年提出, 是基于分歧的方法, 其假设每个数据可以由不同的视图(View)表示, 不同视图可以训练出不同的分类器, 利用这些分类器对无标签样本进行分类, 再挑选最自信的无标签样本加入训练集中. 这种多视图的方法需要满足两个假设:
- 每个视图都包含足够产生最优学习器的信息, 此时对其中任一视图来说, 另一个视图则是冗余的, 即冗余性.
- 两个数据 x 1 x_1 x1 和 x 2 x_2 x2 在给定标签的情况下是条件独立的. 即给定标记时每个属性集都条件独立于另一个属性集.
不过该假设非常强, 大多现实数据无法满足此假设, 或很难划分出冗余的视图. 于是便有了其他协同训练的变种: 由多视图转变为多学习器. 例如 Co-forest 等, 核心思想为在一个视图上训练多个不同的学习器, 这些学习器之间存在一定的差异. 另外也有方法通过去构建多个充分独立的视图模型来近似 Co-training 假设, 如 Deep Co-training 等.
blog 文章传送门:
- Co-training
- COREG
- Democratic Co-Learning
- CoBCReg
- Deep Co-training
- Tri-training
- Disagreement Tri-training
- Tri-net
- Tri-TS
1. Co-training
定义一个实例空间
X
=
X
1
×
X
2
X=X_1 \times X_2
X=X1×X2, 其中
X
1
X_1
X1,
X
2
X_2
X2 对应于同一实例的两个不同"视图". Co-training 算法流程如下:

- 步骤1: 定义带标签的训练集 L \mathbf{L} L 和无标签数据集 U \mathbf{U} U.
- 步骤2: 从 U \mathbf{U} U 中随机选择 u u u 个实例来创建样本缓冲池 U ′ \mathbf{U}' U′. U = U \ U ′ \mathbf{U}=\mathbf{U} \backslash \mathbf{U}' U=U\U′.
- 步骤3: 分别考虑两个视图 x 1 x_1 x1 和 x 2 x_2 x2, 使用 L \mathbf{L} L 训练出分类器 h 1 h_1 h1 和 h 2 h_2 h2.
- 步骤4: 用 h 1 h_1 h1 对 U ′ \mathbf{U}' U′ 中所有元素进行标记, 从中选出置信度高的 p p p 个正标记和 n n n 个负标记, h 2 h_2 h2 同理. U ′ = U ′ \ { U p ′ ∪ U n ′ } \mathbf{U}'=\mathbf{U}' \backslash \{\mathbf{U_p}' \cup \mathbf{U_n}'\} U′=U′\{Up′∪Un′}.
- 步骤5: 将这些标记实例加入到 L L L 中, 即 h 1 h_1 h1 选出的 p + n p+n p+n 个标记实例加入到 x 2 x_2 x2 中, h 2 h_2 h2 选出的 p + n p+n p+n 个标记实例加入到 x 1 x_1 x1 中. 再随机从 U \mathbf{U} U 中选择 2 p + 2 n 2p+2n 2p+2n 个样本到 U ′ \mathbf{U}' U′ 中.
- 步骤3到步骤5迭代 k k k 次.
2. COREG
COREG 既不假设有两个视图, 也不假设使用不同的学习算法. 在这里, 回归器 h 1 h_1 h1 和 h 2 h_2 h2 都采用 k k k-NN 算法. 不过这两个 k k k-NN 回归器通过用不同的距离度量或不同的 k k k 值来实例化, 借此来实现多样性. 在学习过程中, 每个回归器都为另一个回归器标记未标记示例.
选择 k k k-NN 回归器理由如下:
- k k k-NN 算法是一种惰性学习方法, 不需要单独的训练阶段.
- 为了选择合适的未标记示例进行标记, 应估计标记置信度, 在 COREG 中, 置信度估计使用了训练示例的邻近属性, 可以很容易地与 k k k-NN 回归器耦合.
COREG 算法流程如下:

- 首先通过不同的参数设置初始化两个 k k k-NN 回归器 h 1 h_1 h1, h 2 h_2 h2, 两个回归器的训练集分别为 L 1 L_1 L1, L 2 L_2 L2. 注意这两个初始训练集为原始训练集 L L L 的副本.
- 对于每个未标记数据集 U ′ U' U′ 中的 x u \mathbf{x}_u xu, 计算其邻居示例得到集合 Ω u \Omega_u Ωu.
- 利用回归器 h j h_j hj, j ∈ { 1 , 2 } j \in \{1,2\} j∈{1,2} 对 x u \mathbf{x}_u xu 进行预测, 得到预测结果 y ^ u \hat{\mathbf{y}}_u y^u. 并将其添加到训练集 L j L_j Lj 中, 然后重新训练一个 k k k-NN 回归器 h j ′ h_j' hj′.
- 接着计算 MSE: δ x u = ∑ x i ∈ Ω u ( ( y i − h ( x i ) ) 2 − ( y i − h ′ ( x i ) ) 2 ) \delta_{x_u} = \sum_{x_i \in \Omega_u}((y_i-h(\mathbf{x}_i))^2-(y_i-h'(\mathbf{x}_i))^2) δxu=∑xi∈Ωu((yi−h(xi))2−(yi−h′(xi))2).
- 完成上述工作后, 如果存在 δ x u > 0 \delta_{\mathbf{x}_u} > 0 δxu>0, 则最大化 δ x u \delta_{\mathbf{x}_u} δxu 得到 x ~ j \tilde{\mathbf{x}}_j x~j, 利用 h j h_j hj 对其预测得到 y ~ j \tilde{\mathbf{y}}_j y~j, 将 { ( x ~ j , y ~ j ) } \{(\tilde{\mathbf{x}}_j,\tilde{\mathbf{y}}_j)\} {(x~j,y~j)} 添加到 π j \pi_j πj 中, 并将 x ~ j \tilde{\mathbf{x}}_j x~j 从 U ′ U' U′ 中去除.
- 经过一些列迭代, 最终得到 π 1 \pi_1 π1, π 2 \pi_2 π2, 并将 π 1 \pi_1 π1 添加到 L 2 L_2 L2 中, π 2 \pi_2 π2 添加到 L 1 L_1 L1 中. 利用最新的数据集 L 1 L_1 L1, L 2 L_2 L2 重新训练回归器得到 f 1 f_1 f1, f 2 f_2 f2. 最终的预测结果为两个回归器和的平均值.
3. Democratic Co-Learning
Democratic Co-Learning 也是采用单视图多学习器的策略, 像是民主投票, 以多数票的形式进行数据挑选.
定义
L
\mathbf{L}
L 为标记数据集,
U
\mathbf{U}
U 为无标记数据集,
A
1
,
…
,
A
n
A_1,\dots,A_n
A1,…,An 为分类器, 每个分类器对
U
\mathbf{U}
U 中的未标记数据
x
x
x 预测一个类别
c
i
∈
C
=
{
c
1
,
…
,
c
r
}
c_i \in \mathcal{C}=\{c_1,\dots,c_r\}
ci∈C={c1,…,cr}, 并令
c
k
c_k
ck 表示多数分类器预测一致的结果(将这些分类器的集合称为多数团体(Majoritty Group)). 将这些结果加入到
L
\mathbf{L}
L 中, 然后继续进行训练, 直到满足没有可挑选的未标记数据为止. Democratic Co-Learning 算法如下图所示:

初始阶段, 初始化模型:
- 使用不同学习算法 A i A_i Ai 在 L i \mathbf{L_i} Li 上训练分类器 H i H_i Hi.
- 使用
H
i
H_i
Hi 为
U
\mathbf{U}
U 上的每个示例
x
x
x 预测一个标签值
c
j
c_j
cj, 令
c
k
c_k
ck 为
majority prediction.
民主优先采样阶段, 选择未标记示例给专家标记, 并加入对应训练集:
- 计算 H i H_i Hi 在 L \mathbf{L} L 上的 95% 置信区间 [ l i , h i ] [l_i,h_i] [li,hi] 和平均置信度 ( l i + h i ) / 2 (l_i+h_i)/2 (li+hi)/2.
- 初始化 n n n 个 L ′ \mathbf{L}' L′, 如果多数团体的平均置信值之和大于少数团体的平均置信值之和, 则将 ( x , c k ) (x,c_k) (x,ck) 加入到 L i ′ \mathbf{L_i}' Li′ 中.
评估阶段, 评估将 L i ′ \mathbf{L_i}' Li′ 添加到 L i \mathbf{L_i} Li 中是否提升准确率:
- 计算 H i H_i Hi 在 L i \mathbf{L}_i Li 上的 95% 置信区间 [ l i , h i ] [l_i,h_i] [li,hi], 然后分别计算在 L i \mathbf{L}_i Li, L i ′ \mathbf{L}'_i Li′ 和 L i ∪ L i ′ \mathbf{L}_i \cup \mathbf{L}'_i Li∪Li′ 上的错误率 q i q_i qi, e i ′ e'_i ei′ 和 q i ′ q'_i qi′.
- 如果 q i ′ > q i q'_i>q_i qi′>qi 则将 L i ′ \mathbf{L_i}' Li′ 添加到 L i \mathbf{L_i} Li 中
重复以上操作直到 L 1 , ⋯ L n \mathbf{L}_1,\dotsm\mathbf{L}_n L1,⋯Ln 不再变化为止. 最终通过 Combine 函数返回一组分类器.
4. CoBCReg
CoBCReg 的思想与 Democratic Co-Learning 非常类似, CoBCReg 中使用了一个预测器委员会来预测未标记的示例.
CoBCReg 算法如下所示:

- 步骤1. 遍历委员会中的每一个回归器, 对标记数据集使用随机采样获得 { L i , V i } \{L_i,V_i\} {Li,Vi}, 其中 L i L_i Li 为包内数据, 即选择的用于训练的数据, V i V_i Vi 为包外数据(用于测试集). 利用 RBFNN 训练得到回归器 h i h_i hi.
- 步骤2. 对于每次迭代 i i i, 从 U U U 中随机抽取 u u u 个示例到缓冲池 U ′ U' U′. 应用 SelectRelevantExamples 方法使同伴委员会 H i H_i Hi (除 h i h_i hi 之外的所有成员组成)估计 U ′ U' U′ 中每个未标记示例的输出, 并返回最有意义的未标记示例 π i \pi_i πi.
- 步骤3. 对于每次迭代 i i i, 如果 π i \pi_i πi 不为空, 则将其加入到 L i L_i Li, 然后利用更新后的 L i L_i Li 通过 RBFNN 重新训练回归器 h i h_i hi.
- 重复步骤2, 3, 直到达 t t t 到最大迭代次数 T T T 或 U U U 变为空.
- 最终返回回归器 H ( x ) H(x) H(x), 即委员会所有回归器的加权和.
其中 SelectRelevantExamples 算法如下:

- 首先计算 h j h_j hj 在验证集 V j V_j Vj 上的 RMSE ϵ j \epsilon_j ϵj.
- 对于 U ′ U' U′ 中每个未标记示例 x u x_u xu, 对委员会中的所有回归器(除去 h j h_j hj)的预测结果取均值, 得到 { x u , H j ( x u ) } \{x_u,H_j(x_u)\} {xu,Hj(xu)}, 并将其加入到 L j L_j Lj 中.
- 利用更新后的 L j L_j Lj 通过 RBFNN 重新训练回归器 h j ′ h_j' hj′. 然后 h j ′ h'_j hj′ 计算在验证集 V j V_j Vj 上的 RMSE ϵ j ′ \epsilon'_j ϵj′.
- 接着计算 Δ x u ← ( ϵ j − ϵ j ′ ) / ϵ j \Delta_{x_u} \leftarrow (\epsilon_j-\epsilon'_j)/ \epsilon_j Δxu←(ϵj−ϵj′)/ϵj.
- 对 U ′ U' U′ 迭代完成后, 定义空集合 π \pi π.
- 通过 g r gr gr 次迭代, 选择 g r gr gr 个使 Δ x u \Delta_{x_u} Δxu 最大的结果对应的未标记示例 x u x_u xu, 将其加入到 π j \pi_j πj 中.
- 最后返回 π j \pi_j πj.
5. Deep Co-training
Co-Training 假设
D
=
S
∪
U
\mathcal{D}=\mathcal{S} \cup \mathcal{U}
D=S∪U 中的每个数据
x
x
x 有两个视图, 即
x
=
(
v
1
,
v
2
)
x = (v_1, v_2)
x=(v1,v2), 每个视图
v
i
v_i
vi 都足以学习一个有效的模型. 其中
S
\mathcal{S}
S,
U
\mathcal{U}
U 分别表示标记数据集和未标记数据集. 给定
D
\mathcal{D}
D 的分布
X
\mathcal{X}
X, Co-Training 假设表示如下:
f
(
x
)
=
f
1
(
v
1
)
=
f
2
(
v
2
)
,
∀
x
=
(
v
1
,
v
2
)
∼
X
f(x)=f_1(v_1)=f_2(v_2),\forall x=(v_1,v_2) \sim\mathcal{X}
f(x)=f1(v1)=f2(v2),∀x=(v1,v2)∼X
-
在 Deep Co-training 中, v 1 ( x ) v_1(x) v1(x) 和 v 2 ( x ) v_2(x) v2(x) 是 x x x 在最终全连接层 f i ( ⋅ ) f_i(·) fi(⋅) 之前的卷积表示. 在标记数据集 S \mathcal{S} S 上的标准交叉熵损失函数定义为:
L s u p ( x , y ) = H ( y , f 1 ( v 1 ( x ) ) ) + H ( y , f 2 ( v 2 ( x ) ) ) \mathcal{L}_{\mathrm{sup}}(x,y)=H(y,f_1(v_1(x)))+H(y,f_2(v_2(x))) Lsup(x,y)=H(y,f1(v1(x)))+H(y,f2(v2(x)))
其中 H ( p , q ) H(p,q) H(p,q) 表示交叉熵. 而对于未标记数据集 U \mathcal{U} U, 基于 Co-Training 假设, 期望 f 1 ( v 1 ( x ) ) f_1(v_1(x)) f1(v1(x)) 和 f 2 ( v 2 ( x ) ) f_2(v_2(x)) f2(v2(x)) 有相似的预测, 使用 JS 散度来进行 f 1 ( v 1 ( x ) ) f_1(v_1(x)) f1(v1(x)) 和 f 2 ( v 2 ( x ) ) f_2(v_2(x)) f2(v2(x)) 之间的相似性度量, 损失函数定义如下:
L c o t ( x ) = H ( 1 2 ( f 1 ( v 1 ( x ) ) + f 2 ( v 2 ( x ) ) ) ) − 1 2 ( H ( f 1 ( v 1 ( x ) ) ) + H ( f 2 ( v 2 ( x ) ) ) ) \mathcal{L}_{\mathrm{cot}}(x)=H(\frac{1}{2}(f_1(v_1(x))+f_2(v_2(x))))-\frac{1}{2}(H(f_1(v_1(x)))+H(f_2(v_2(x)))) Lcot(x)=H(21(f1(v1(x))+f2(v2(x))))−21(H(f1(v1(x)))+H(f2(v2(x))))
其中 H ( p ) H(p) H(p) 表示 p p p 的熵. -
利用 g ( x ) g(x) g(x) 从 D \mathcal{D} D 中生成对抗样本数据集 D ′ \mathcal{D}' D′, 在 D ′ \mathcal{D}' D′ 中 f 1 ( v 1 ( g ( x ) ) ) ≠ f 2 ( v 2 ( g ( x ) ) ) f_1(v_1(g(x))) \neq f_2(v_2(g(x))) f1(v1(g(x)))=f2(v2(g(x))). 希望 g ( x ) g(x) g(x) 与 x x x 之间足够小, 以便于对抗样本还能保持自然的图像特征. 不过当 g ( x ) − x g(x)-x g(x)−x 很小时, 有很大概率会出现 f 1 ( v 1 ( g ( x ) ) = f 1 ( v 1 ( x ) ) f_1(v_1(g(x))=f_1(v_1(x)) f1(v1(g(x))=f1(v1(x)) 和 f 2 ( v 2 ( g ( x ) ) = f 2 ( v 2 ( x ) ) f_2(v_2(g(x))=f_2(v_2(x)) f2(v2(g(x))=f2(v2(x)), 这就与我们的想法违背. 即希望当 f 1 ( v 1 ( g ( x ) ) = f 1 ( v 1 ( x ) ) f_1(v_1(g(x))=f_1(v_1(x)) f1(v1(g(x))=f1(v1(x)) 出现时, 需满足 f 2 ( v 2 ( g ( x ) ) ≠ f 2 ( v 2 ( x ) ) f_2(v_2(g(x))\neq f_2(v_2(x)) f2(v2(g(x))=f2(v2(x)). 通过交叉熵来训练网络 f 1 f_1 f1, f 2 f_2 f2, 使得可以抵抗相互的对抗示例:
L d i f ( x ) = H ( f 1 ( v 1 ( x ) ) , f 2 ( v 2 ( g 1 ( x ) ) ) ) + H ( f 1 ( v 1 ( g 2 ( x ) ) ) , f 2 ( v 2 ( x ) ) ) \mathcal{L}_{\mathrm{dif}}(x)=H(f_1(v_1(x)), f_2(v_2(g_1(x))))+H(f_1(v_1(g_2(x))), f_2(v_2(x))) Ldif(x)=H(f1(v1(x)),f2(v2(g1(x))))+H(f1(v1(g2(x))),f2(v2(x)))
最终的损失函数定义为:
L = E ( x , y ) ∈ S L s u p ( x , y ) + λ c o t E x ∈ U L c o t ( x ) + λ d i f E x ∈ D L d i f ( x ) \mathcal{L}=\mathbb{E}_{(x,y)\in\mathcal{S}}\mathcal{L}_{\mathrm{sup}}(x,y)+\lambda_{\mathrm{cot}}\mathbb{E}_{x\in\mathcal{U}}\mathcal{L}_{\mathrm{cot}}(x)+\lambda_{\mathrm{dif}}\mathbb{E}_{x\in\mathcal{D}}\mathcal{L}_{\mathrm{dif}}(x) L=E(x,y)∈SLsup(x,y)+λcotEx∈ULcot(x)+λdifEx∈DLdif(x)
6. Tri-training
Tri-training 核心思想简述如下: 假设除了分类器
h
1
h_1
h1 和
h
2
h_2
h2 之外, 利用标记数据再训练了一个分类器
h
3
h_3
h3. 那么, 对于任何分类器, 只要其他两个分类器同意这个示例的标签, 则可以将其标记起来, 而分类器标记的置信度不需要明确测量. 例如, 如果
h
2
h_2
h2 和
h
3
h_3
h3 同意示例
x
x
x 的标记结果, 则可以将标记
x
x
x 加入到
h
1
h_1
h1 中. 其具体算法如下:

首先利用 Bootstrap 重采样, 从有标签数据集
L
L
L 里采样三个子数据集
S
i
S_i
Si,
S
j
S_j
Sj,
S
k
S_k
Sk. 利用三个子数据集训练三个基分类器
h
i
h_i
hi,
h
j
h_j
hj,
h
k
h_k
hk. 并初始化
e
i
′
=
0.5
e_i'=0.5
ei′=0.5,
l
i
′
=
0
l_i'=0
li′=0. 这里
e
i
′
e_i'
ei′ 表示
h
j
&
h
k
h_j \& h_k
hj&hk 的分类错误率的上界, 即
h
j
h_j
hj 和
h
k
h_k
hk 组合得出的假设的错误率.
l
i
′
l_i'
li′ 用作与挑选的未标记示例集
L
i
L_i
Li 的大小做比较.
接着迭代每个分类器, 首先, 初始化挑选数据集 L i = ∅ L_i=\empty Li=∅; 使用 MeasureError 函数计算 e i e_i ei; 初始化分类器 h i h_i hi 的更新标志 u p d a t e i = F A L S E update_i=FALSE updatei=FALSE.
当满足
e
i
<
e
i
′
e_i < e_i'
ei<ei′ 时, 对于分类器
h
i
h_i
hi, 使用另外两个分类器预测所有未标注数据集, 挑选出其中预测结果相同的样本, 作为新的有标签数据
(
x
,
h
j
(
x
)
)
(x,h_j(x))
(x,hj(x)), 并加入到分类器
h
i
h_i
hi 的训练集
L
i
L_i
Li 中. 当
l
i
′
=
0
l_i'=0
li′=0 时(即刚初始化,
h
i
h_i
hi 还没经过训练进行更新), 通过下式计算
l
i
′
l_i'
li′:
l
i
′
=
⌊
e
i
e
i
′
−
e
i
+
1
⌋
l_i'=\lfloor\frac{e_i}{e_i'-e_i}+1\rfloor
li′=⌊ei′−eiei+1⌋
当
l
i
′
<
∣
L
i
∣
l_i' < \vert L_i\vert
li′<∣Li∣ 时, 如果
e
i
∣
L
i
∣
<
e
i
′
l
i
′
e_i\vert L_i\vert < e_i'l_i'
ei∣Li∣<ei′li′, 则表示分类器
h
i
h_i
hi 已更新:
u
p
d
a
t
e
i
=
T
r
u
e
update_i=True
updatei=True, 如果
l
i
′
>
e
i
e
i
′
−
e
i
l_i'>\frac{e_i}{e_i'-e_i}
li′>ei′−eiei, 则通过函数 Subsample 从
L
i
L_i
Li 中随机选择
∣
L
i
∣
−
⌈
e
i
e
i
′
−
e
i
+
1
⌉
\vert L_i\vert-\lceil \frac{e_i}{e_i'-e_i}+1\rceil
∣Li∣−⌈ei′−eiei+1⌉ 个示例删除, 同时更新
u
p
d
a
t
e
i
=
T
r
u
e
update_i=True
updatei=True.
迭代完成后, 检查每个分类器的更新状态, 如果分类器 i i i 已更新, 则将与之对应的 L i L_i Li 加入到 L L L 中, 利用扩增的数据集 L L L 更新分类器 i i i, 同时用 e i e_i ei 更新 e i ′ e_i' ei′, ∣ L ∣ \vert L\vert ∣L∣ 更新 l i ′ l_i' li′.
重复上述分类器迭代过程, 直到每个分类器不在变化为止. 最终得到三个训练完成的分类器, 通过 arg max y ∈ l a b e l ∑ h i ( x ) = y 1 \argmax_{y\in label} \sum_{h_i(x)=y}1 y∈labelargmax∑hi(x)=y1 来预测结果, 即投票原则.
7. Disagreement Tri-training
带分歧的 Tri-training 只对 Tri-training 进行简单改动, 如下所示:

非常容易理解, 如果分类器
c
j
c_j
cj 和
c
k
c_k
ck 都同意对数据
x
x
x 的预测, 但
c
i
c_i
ci 不同意, 就可以自然的认为
x
x
x 是
c
i
c_i
ci 的弱点. 并希望通过
x
x
x 来加强
c
i
c_i
ci.
8. Tri-net
Tri-net 的训练过程如下图:
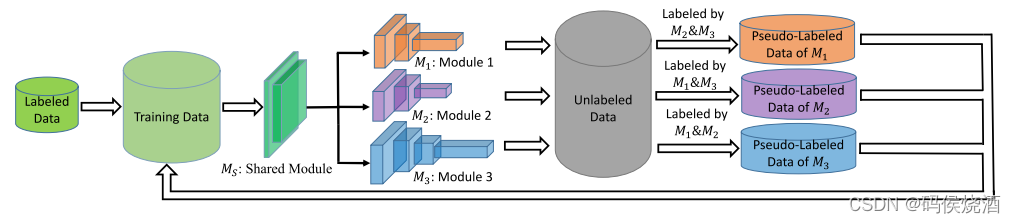
阶段1: 初始化
Tri-net 的第一步是生成三个多样的模型. Tri-net 由一个共享模型
M
S
M_S
MS 和另外三个不同的模型
M
1
M_1
M1,
M
2
M_2
M2 和
M
3
M_3
M3 组成. 为了得到三个准确多样的模型, 使用 Output Smearing 来生成三个不同的标记数据集:
L
o
s
1
\mathcal{L}^1_{os}
Los1,
L
o
s
2
\mathcal{L}^2_{os}
Los2 和
L
o
s
3
\mathcal{L}^3_{os}
Los3. 在三个数据集上同时训练
M
S
M_S
MS,
M
1
M_1
M1,
M
2
M_2
M2 和
M
3
M_3
M3. 网络结构如下:

阶段2: 训练
和 tri-training 思想一样, 如果两个模型对未标记示例的预测达成一致, 并且预测可靠且稳定, 则将这个具有伪标签示例加入到第三个模型的训练集中. 然后用增强的训练集细化第三个模型. 由于模型之间相互挑选增加了训练集, 所以三个模型会越来越相似. 为了解决这个问题, 对标记数据上的模型进行微调, 以在某些特定轮次中增加它们之间的多样性. 整个训练过程如下所示:

- 步骤1. 在 L \mathcal{L} L 上使用 Output Smearing 生成三个不同的标记数据集: L o s 1 \mathcal{L}^1_{os} Los1, L o s 2 \mathcal{L}^2_{os} Los2 和 L o s 3 \mathcal{L}^3_{os} Los3.
- 步骤2. 在 L o s 1 \mathcal{L}^1_{os} Los1, L o s 2 \mathcal{L}^2_{os} Los2 和 L o s 3 \mathcal{L}^3_{os} Los3 上训练 M S M_S MS, M 1 M_1 M1, M 2 M_2 M2, M 3 M_3 M3.
- 步骤3. 训练 M v , v = 1 , 2 , 3 M_v, v=1,2,3 Mv,v=1,2,3. 初始化挑选样本集 P L v \mathcal{PL}_v PLv, 首先通过 Labeling 函数让另外两个模型挑选出置信示例, 并添加到 P L v \mathcal{PL}_v PLv 中, 接着, 利用 DES 方法对 P L v \mathcal{PL}_v PLv 进行更新, 最后得到 M v M_v Mv 的训练样本 L ^ v = L ∪ P L v \hat{\mathcal{L}}_v=\mathcal{L} \cup \mathcal{PL}_v L^v=L∪PLv. 注意, 如果刚开始训练 M 1 M_1 M1 时, 模型 M S M_S MS 和 M 1 M_1 M1 一同通过 L ^ v \hat{\mathcal{L}}_v L^v 训练, 其他两个模型进行训练时则不需要再对 M S M_S MS 进行训练.
- 重复步骤3 T T T 次, 最终返回训练完成的 M S M_S MS, M 1 M_1 M1, M 2 M_2 M2, M 3 M_3 M3.
9. Tri-TS
同 Tri-Training, 首先从标记数据集 L L L 中用 bootstrap 采样获得三个不同的数据集 S i S_i Si, S j S_j Sj, S k S_k Sk, 这样做的目的是增加多样性, 然后分别训练三个分类器 m i m_i mi, m j m_j mj, m k m_k mk. 对于未标记数据集 U U U 中的示例 x x x, 每个分类器对其的预测结果分别为 c i c_i ci, c j c_j cj, c k c_k ck, 以及对应的概率 p i ( c i ∣ x ) p_i(c_i\vert x) pi(ci∣x), p j ( c j ∣ x ) p_j(c_j\vert x) pj(cj∣x), p k ( c k ∣ x ) p_k(c_k\vert x) pk(ck∣x).
与原始 Tri-Training 中为
x
x
x 分配多数投票标签的策略不同, 在 Teacher-Student 中, 从师生的角度对学习任务进行建模. 在迭代过程中, 如果
p
j
(
c
j
∣
x
)
p_j(c_j\vert x)
pj(cj∣x),
p
k
(
c
k
∣
x
)
p_k(c_k\vert x)
pk(ck∣x) 同时大于 teacher 的阈值
τ
t
\tau_t
τt, 则将
m
j
m_j
mj,
m
k
m_k
mk 视作 teacher, 如果另一个分类器
m
i
m_i
mi 的预测概率小于 student 的阈值
τ
s
\tau_s
τs, 则将其视为 student. 未标记样本
x
x
x 只有在被判别为可被教导(Teachable)后才会被分配一个标签. 选择 Teachable 样本的算法如下所示:

其标准如下:
- 分类器 m j m_j mj, m k m_k mk 互相认同对方的分类结果 c k c_k ck, c j c_j cj.
- 两个 teacher 的预测置信度 p j p_j pj, p k p_k pk 必须同时大于 τ t \tau_t τt, 同时 student 的预测置信度 p i p_i pi 必须小于 τ s \tau_s τs.
完整的 Teacher Student Tri-training 算法如下所示:


















 7009
7009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









