







Tri-net 将 tri-training 与深度学习模型相结合. 首先学习三个初始模型, 然后使用每个模型来预测一个未标记数据池, 其中两个模型为另一个模型标记一些未标记实例. Tri-net 中涉及三个关键技术: 模型初始化、多样性增强和伪标签编辑.
论文地址: Tri-net for Semi-Supervised Deep Learning
代码地址: http://www.lamda.nju.edu.cn/code_Tri-net.ashx?AspxAutoDetectCookieSupport=1
会议: IJCAI 2018
任务: 分类
关键技术如下:
- Output Smearing: 使用输出调制法(output smearing)生成多样化和准确的初始模型.
- Diversity Augmentation: 在标记数据的某些特定轮次中对模块进行微调, 增加它们之间的多样性.
- Pseudo-Label Editing: 基于稳定伪标签更可靠的直觉, 提出名为 DES 的数据编辑方法.
Tri-net 算法
定义 L = { ( x l , y l ) ∣ l = 1 , … , L } \mathcal{L}=\{(x_l,y_l) \vert l=1,\dots,L\} L={(xl,yl)∣l=1,…,L} 为标记数据集, U = { ( x u ) ∣ u = 1 , … , U } \mathcal{U}=\{(x_u)\vert u=1,\dots,U\} U={(xu)∣u=1,…,U} 为未标记数据集, 标签 y l = ( y l 1 , … , y l C ) y_l=(y_{l1},\dots,y_{lC}) yl=(yl1,…,ylC) 表示 C C C 个类别, 如果 y l c = 1 y_{lc}=1 ylc=1, 则表示当前实例属于第 c c c 个类别, 而 y l c = 0 y_{lc}=0 ylc=0 时则不是, 即 one-hot 编码的形式.
Tri-net 的训练过程如下图:
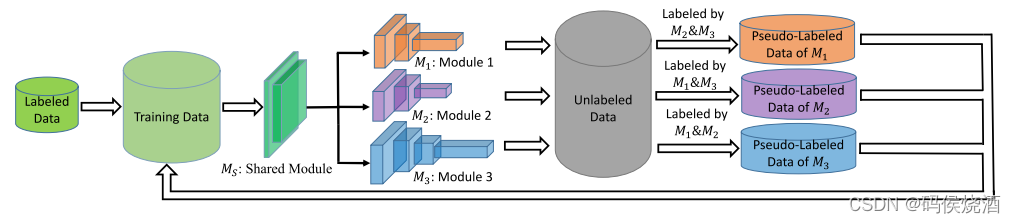
阶段1: 初始化
Tri-net 的第一步是生成三个多样的模型. Tri-net 由一个共享模型
M
S
M_S
MS 和另外三个不同的模型
M
1
M_1
M1,
M
2
M_2
M2 和
M
3
M_3
M3 组成. 为了得到三个准确多样的模型, 使用 Output Smearing 来生成三个不同的标记数据集:
L
o
s
1
\mathcal{L}^1_{os}
Los1,
L
o
s
2
\mathcal{L}^2_{os}
Los2 和
L
o
s
3
\mathcal{L}^3_{os}
Los3. 在三个数据集上同时训练
M
S
M_S
MS,
M
1
M_1
M1,
M
2
M_2
M2 和
M
3
M_3
M3. 网络结构如下:

阶段2: 训练
和 tri-training 思想一样, 如果两个模型对未标记示例的预测达成一致, 并且预测可靠且稳定, 则将这个具有伪标签示例加入到第三个模型的训练集中. 然后用增强的训练集细化第三个模型. 由于模型之间相互挑选增加了训练集, 所以三个模型会越来越相似. 为了解决这个问题, 对标记数据上的模型进行微调, 以在某些特定轮次中增加它们之间的多样性. 整个训练过程如下所示:

- 步骤1. 在 L \mathcal{L} L 上使用 Output Smearing 生成三个不同的标记数据集: L o s 1 \mathcal{L}^1_{os} Los1, L o s 2 \mathcal{L}^2_{os} Los2 和 L o s 3 \mathcal{L}^3_{os} Los3.
- 步骤2. 在 L o s 1 \mathcal{L}^1_{os} Los1, L o s 2 \mathcal{L}^2_{os} Los2 和 L o s 3 \mathcal{L}^3_{os} Los3 上训练 M S M_S MS, M 1 M_1 M1, M 2 M_2 M2, M 3 M_3 M3.
- 步骤3. 训练 M v , v = 1 , 2 , 3 M_v, v=1,2,3 Mv,v=1,2,3. 初始化挑选样本集 P L v \mathcal{PL}_v PLv, 首先通过 Labeling 函数让另外两个模型挑选出置信示例, 并添加到 P L v \mathcal{PL}_v PLv 中, 接着, 利用 DES 方法对 P L v \mathcal{PL}_v PLv 进行更新, 最后得到 M v M_v Mv 的训练样本 L ^ v = L ∪ P L v \hat{\mathcal{L}}_v=\mathcal{L} \cup \mathcal{PL}_v L^v=L∪PLv. 注意, 如果刚开始训练 M 1 M_1 M1 时, 模型 M S M_S MS 和 M 1 M_1 M1 一同通过 L ^ v \hat{\mathcal{L}}_v L^v 训练, 其他两个模型进行训练时则不需要再对 M S M_S MS 进行训练.
- 重复步骤3 T T T 次, 最终返回训练完成的 M S M_S MS, M 1 M_1 M1, M 2 M_2 M2, M 3 M_3 M3.
Diversity Augmentation 多样性增强
为了防止 collapsed neural networks 问题, 还会在某些 epoch 中继续使用 Output Smearing. 即在步骤3中, 训练 M v M_v Mv 之前, 利用 Output Smearing 再次生成 L o s 1 \mathcal{L}^1_{os} Los1, L o s 2 \mathcal{L}^2_{os} Los2 和 L o s 3 \mathcal{L}^3_{os} Los3, 并训练 M S M_S MS, M 1 M_1 M1, M 2 M_2 M2, M 3 M_3 M3. Tri-net 中选择的 epoch 时机为: 在 N t = U N_t=U Nt=U 且 m o d ( t , 4 ) = = 0 mod(t, 4) == 0 mod(t,4)==0 时进行操作. 这里 N t N_t Nt 表示数据缓冲池的大小, 缓冲池用来存放从 U \mathcal{U} U 中选择的未标记数据, 这个思想来自 Co-Training.
Output Smearing 输出调制
类似数据增强(数据增强是将噪声添加到标记数据集中), Output Smearing 通过将随机噪声注入到真实标签来构造不同的训练集, 并分别从不同的训练集中生成模型:
y
^
l
c
=
y
l
c
+
R
e
L
U
(
z
l
c
×
s
t
d
)
\hat{y}_{lc}=y_{lc} + \mathrm{ReLU}(z_{lc} \times std)
y^lc=ylc+ReLU(zlc×std)
其中
z
l
c
z_{lc}
zlc 是在标准正态分布进行的独立采样,
s
t
d
std
std 是标准偏差,
R
e
L
U
\mathrm{ReLU}
ReLU 是一个函数, 确保
y
^
l
c
\hat{y}_{lc}
y^lc 非负, 其在神经网络中常用来做激活函数:
R
e
L
U
(
a
)
=
{
a
a
>
0
0
a
≤
0
\mathrm{ReLU}(a)= \begin{cases} a & a>0 \\ 0 & a\leq 0 \end{cases}
ReLU(a)={a0a>0a≤0
然后对
y
^
l
c
\hat{y}_{lc}
y^lc 进行归一化(相当于是转化为了概率形式):
y
^
l
=
(
y
^
l
1
,
…
,
y
^
l
C
)
/
∑
c
=
1
C
y
^
l
c
\hat{y}_{l}=(\hat{y}_{l1},\dots,\hat{y}_{lC})/\sum_{c=1}^C\hat{y}_{lc}
y^l=(y^l1,…,y^lC)/c=1∑Cy^lc
通过 Output Smearing, 生成三个训练集
L
o
s
v
=
{
(
x
l
,
y
^
l
)
∣
1
≤
l
≤
L
}
(
v
=
1
,
2
,
3
)
\mathcal{L}_{os}^v=\{(x_l,\hat{y}_l)\vert 1\leq l \leq L\}(v=1,2,3)
Losv={(xl,y^l)∣1≤l≤L}(v=1,2,3), 并利用其初始化
M
1
M_1
M1,
M
2
M_2
M2,
M
3
M_3
M3, 损失函数如下:
L
o
s
s
=
1
L
∑
l
=
1
L
{
L
y
(
M
1
(
M
S
(
x
l
)
)
,
y
^
l
1
)
+
L
y
(
M
2
(
M
S
(
x
l
)
)
,
y
^
l
2
)
+
L
y
(
M
3
(
M
S
(
x
l
)
)
,
y
^
l
3
)
}
Loss=\frac{1}{L}\sum_{l=1}^L\{L_y(M_1(M_S(x_l)),\hat{y}_l^1)+L_y(M_2(M_S(x_l)),\hat{y}_l^2)+L_y(M_3(M_S(x_l)),\hat{y}_l^3)\}
Loss=L1l=1∑L{Ly(M1(MS(xl)),y^l1)+Ly(M2(MS(xl)),y^l2)+Ly(M3(MS(xl)),y^l3)}
其中,
L
y
L_y
Ly 为标准 softmax 交叉熵损失函数.
Pseudo-Label Editing 伪标签编辑
新标注样本的伪标签可能不正确, 这些不正确的伪标签会降低性能(相当于在训练集中添加噪声). 在半监督学习中的一些数据编辑方法通常是基于图的, 由于高维度而难以在 DNN 中使用. 在这里, 使用一种用于具有 dropout 的 DNN 的新数据编辑方法(也是作者团队在2014年提出的).
对于每个 ( x i , y ‾ i ) (x_i, \overline{y}_i) (xi,yi)( y ‾ i \overline{y}_i yi 是测试模式下的伪标签), 使用模型预测 x i x_i xi 的标签 K K K 次, 并记录预测与 y ‾ i \overline{y}_i yi 不同的频率 k k k. 如果 k > K 3 k > \frac{K}{3} k>3K, 则认为 x i x_i xi 的伪标签 y ‾ i \overline{y}_i yi 是一个不稳定的伪标签. 可以理解为如果 x i x_i xi 的多次预测的伪标签相同, 则这个伪标签是稳定的.
后验概率
Tri-net 的后验概率为三个模型的后验概率的平均值. 未标记示例
x
x
x 以最大后验概率进行分类:
y
=
arg max
c
∈
{
1
,
…
,
C
}
{
p
(
M
1
(
M
S
(
x
)
)
=
c
∣
x
)
+
p
(
M
2
(
M
S
(
x
)
)
=
c
∣
x
)
+
p
(
M
3
(
M
S
(
x
)
)
=
c
∣
x
)
}
y=\argmax_{c\in\{1,\dots,C\}}\{p(M_1(M_S(x))=c|x)+p(M_2(M_S(x))=c|x)+p(M_3(M_S(x))=c|x)\}
y=c∈{1,…,C}argmax{p(M1(MS(x))=c∣x)+p(M2(MS(x))=c∣x)+p(M3(MS(x))=c∣x)}

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









