







 本文探讨了在深度估计中结合有监督和无监督学习的方法,特别是在CVPR2017的一篇论文中,作者提出在有限的有监督数据上结合无监督学习来预测深度图。通过使用Berhu函数减少深度残差误差,结合正则项来平滑深度变化并保持边缘不连续性,以及在网络结构中采用skip连接,提高了预测的准确性。研究发现,全面的无监督学习比仅在无标签区域学习效果更好,且Berhu函数在测试集上的表现优于L2损失函数。
本文探讨了在深度估计中结合有监督和无监督学习的方法,特别是在CVPR2017的一篇论文中,作者提出在有限的有监督数据上结合无监督学习来预测深度图。通过使用Berhu函数减少深度残差误差,结合正则项来平滑深度变化并保持边缘不连续性,以及在网络结构中采用skip连接,提高了预测的准确性。研究发现,全面的无监督学习比仅在无标签区域学习效果更好,且Berhu函数在测试集上的表现优于L2损失函数。
CVPR2017_Semi-Supervised Deep Learning for Monocular Depth Map Prediction
这是一篇用双目进行无监督学习估计深度的论文。
对一幅图进行有监督训练进行深度估计时,由于采集设备的局限,并非图像的每个像素都有对应的真实值。于是作者提出在图像有真实值的地方进行监督学习,无真实值的地方进行无监督学习(最终作者发现对整个图像都进行无监督学习+部分地方有监督学习效果最好)。这样的结合,使得无监督学习部分学习起来相对轻松甚至不需要很复杂的价值函数而不用担心陷入局部最优解,使得有监督学习速度能更快。
最后作者达到了state of art的效果。
1.介绍
作者认为当前有监督学习过程中过于依赖真实值,但真实值可能有以下问题:
- 有误差和噪音;
- 雷达等真值采集的测量值很稀疏;
- 需要对图像系统的内外参进行标定。
- 相机和雷达不能很好地对准,特别是两者中心无法很好对准,导致本来在相机视野之外的真值也投影到图片中
2.价值函数
整体流程如图:
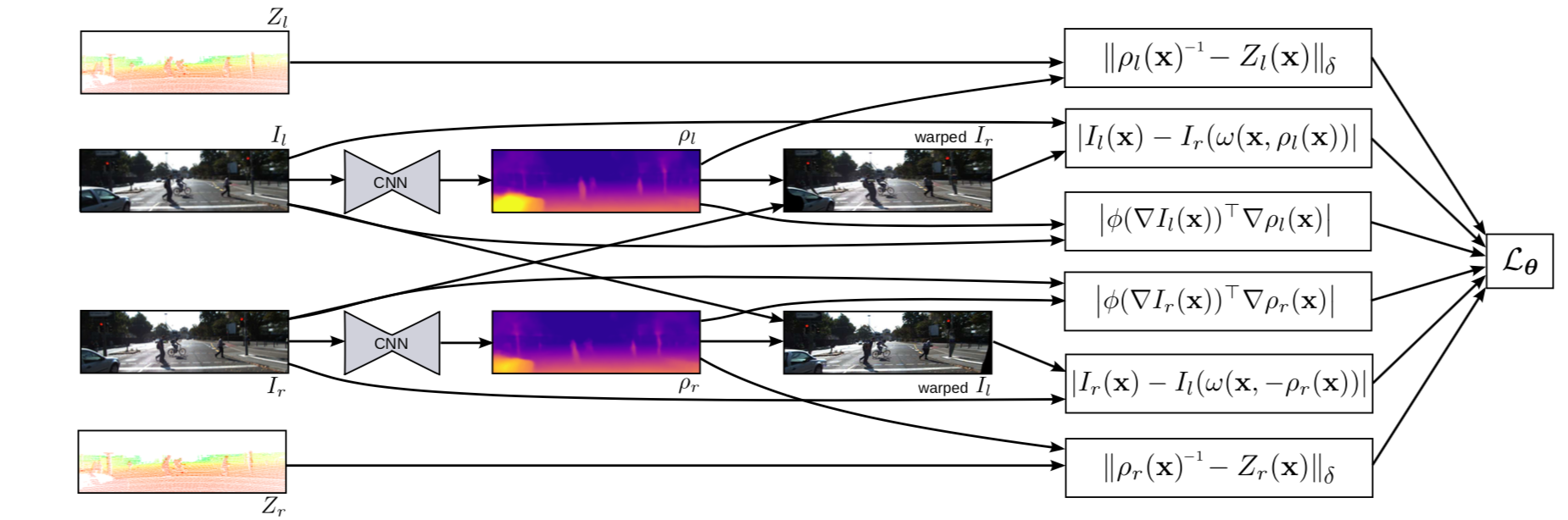
相比前几篇论文,此处作者以预测逆深度为目标。我们知道,整个深度的分布由近及远是一个长尾分布,所以比起直接用深度Z,用反逆深度能更好地表达深度的数值特点。
作者总的价值函数包括有监督深度误差,无监督深度误差和正则化三个部分:
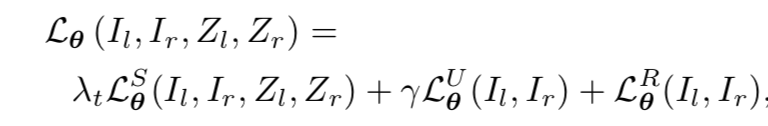
有时会感叹,双目匹配和深度估计在很长一段时间是高度相关的,深度估计也形成了形如双目匹配中 E=E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









