










论文题目:Event Detection using Hierarchical Multi-Aspect Attention
论文来源:WWW 2019 乔治梅森大学,弗吉尼亚理工大学
论文链接:https://doi.org/10.1145/3308558.3313659
代码链接:https://github.com/sumehta/FBMA
关键词:分层注意力,多角度注意力,事件检测,bi-GRU
文章目录
1 摘要
本文解决的是针对网络文本数据的事件检测和事件编码问题。
经典的事件编码和抽取模型依赖于关键词词典和模板,或者需要为短语/句子打标签,不能广泛利用网络上大规模的非结构化文本信息。
事件编码可以看成是分层的任务,底层的粗粒度任务是事件检测(识别出包含某一特定事件的文档),细粒度的任务是对事件进行编码(识别出关键的短语、关键句)。对于这种分层的模型,使用注意力机制是很自然的想法。
本文提出一个因式分解的双线性多角度的注意力机制(FBMA, factorized bilinear multi-aspect attention mechanism ),从不同角度出发构建文本的表示。
实验证明,本文的模型FBMA在检测内乱、军事行动等事件上取得了超越state-of-the-art的效果。
2 引言
(1)任务描述
给定大量的从网络中得到的文本信息,例如新闻、社交媒体、博客和论坛,从中识别出有价值的信息是很有意义的一项研究工作。
问答系统、知识库的构建和命名实体识别等应用可以为国家安全和网络安全提供关键的决策支持,然而这些应用依赖于事件抽取和编码过程。
事件分析指的是从文本中抽取出和某一事件相关的特定信息,可以看为分层的任务:
1)事件检测:识别出有特定事件的文档;
2)事件编码:识别出关键短语以及描述事件相关信息的句子(比如事件类型,事件涉及到的人物的类型,以及这些内容间的关系)。
(2)面临的挑战
- 事件领域的多样性
- 大量的数据
- 细粒度标签的缺乏
(3)已有工作的不足
先前的事件编码工作聚焦于:抽取实体;检测触发词;在预定义的模板上进行槽匹配。然而这些方法有一些不足:
1)它们依赖于有细粒度标签的训练数据,对于多个领域以及多种类型的事件,或者细粒度的标签是很困难的。相比而言,文档级别的标签更易获得;
2)它们使用去掉上下文信息的句子嵌入,会导致false negatives(真实值是positive,模型认为是negative),因为判断事件的发生通常不能只考虑一个句子。
有学者提出了多实例学习(MIL, multiple instance learning )方法,在一定程度上缓解了上述问题。MIL方法将文档看成是bags of sentences,在句子层面做预测,对选定的几个句子聚合句子级别的概率,从而得到文档级别的预测概率。
标准的MIL形式是:实例级别的标签是不可得的,只在group/bag级别有标签。若bag中至少有一个正(positive)的实例,则给bag正的标签,否则为bag分配负标签。
(4)作者提出
利用文本语料中的隐式层次结构,在一个统一的框架中对新闻文章中的事件检测和关键句识别任务进行建模,而且不需要使用句子级别的显式标签。对于这种分层的模型,使用注意力机制是很自然的想法。注意力机制可以在构建文档表示时,对不同重要程度的单词和句子分配不同的注意力。
作者使用了基于RNN的层次结构,并使用了注意力机制,以构建句子和文档的表示。句子的表示是使用句中所有单词的信息构建的,文档的表示考虑了文档中所有句子的信息。
由于一个句子可能包含和事件相关的多角度的信息(例如起因,地点等),所以作者采用了有层次的注意力网络模型。模型使用了多角度的注意力机制,对一个句子中的单词计算多个注意力分布,每个分布都从不同角度对句子进行了考虑。而且只需要使用更易获取的文档级别的标签。
(5)贡献
1)提出了因式分解的双线性多角度注意力机制FBMA,使用多个注意力分布构建句子的表示,并且使用有层次结构的模型提高了EE的性能;
2)在使用两种语言的两个不同领域的3个事件数据集上取得了state-of-the-art的效果。
3 模型
事件检测问题定义为:给定一个包含 N N N个新闻文章 { x 1 , x 2 , . . . , x N } {\{x_1, x_2, ..., x_N}\} {x1,x2,...,xN}的语料,每一个文章都有一个事件标签 y ∈ { 0 , 1 } y\in {\{0, 1}\} y∈{0,1},1表示文章中含有一个事件。我们的目标是预测出每个新闻文章的标签,即预测文章中是否有事件。
3.1 序列编码器
假定一篇新闻文章中有 n n n个句子,每个句子中有 T T T个单词,一个句子由单词的tokens w i t , t ∈ [ 0 , T ] w_{it}, t\in [0, T] wit,t∈[0,T]组成。
使用预训练的嵌入矩阵 W e ∈ R d × ∣ V ∣ \mathbf{W}_e\in R^{d\times|V|} We∈Rd×∣V∣,得到每个单词的向量表示 x i t = W e w i t \mathbf{x}_{it}=\mathbf{W}_e\mathbf{w}_{it} xit=Wewit。其中 d d d是嵌入维度, V V V是词表。
使用bi-GRU RNN对句子进行编码,捕获到两个方向上的上下文信息。

其中, h i t \mathbf{h}_{it} hit是通过拼接正反两个方向的隐层表示得到的。
3.2 单词级别的注意力
对于事件抽取,某些单词的出现增加了该句含有事件的可能性。在计算句子表示时,应该为这些单词分配更高的注意力权重。由于和事件相关的触发词可能出现在句中的任何位置,所以作者使用了全局的注意力机制,对句中所有单词进行考量,以得到句子的表示。
3.2.1 双线性注意力
令 h i t \mathbf{h}_{it} hit是单词 x i t \mathbf{x}_{it} xit的表示。首先使用一层感知机(MLP)将 h i t \mathbf{h}_{it} hit转换为隐层表示 u i t \mathbf{u}_{it} uit:
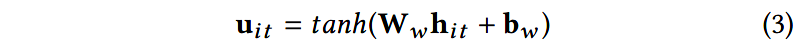
然后,使用一个双线性模型计算 u i t \mathbf{u}_{it} uit和单词级别的上下文向量 u w \mathbf{u}_w uw的分值,以衡量单词的重要程度:
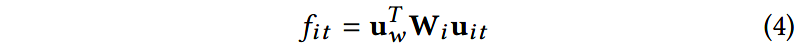
这里的 W i \mathbf{W}_i Wi是一个双线性映射矩阵; u w \mathbf{u}_w uw是随机初始化的,在训练时使用其他参数对其进行学习。 u w \mathbf{u}_w uw可以看成是一个高维表示,蕴含了有信息含量的单词的表示信息。
使用softmax函数计算单词 x i t \mathbf{x}_{it} xit的注意力权重:
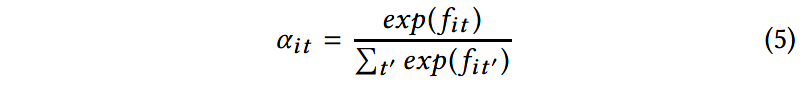
3.2.2 因式分解的双线性多角度注意力
上述所展示的注意力分布只能从一个角度对句子进行考虑,例如一组特别的触发词或短语,因此只能反映句子中一方面的语义或一部分的语义信息。但是事件中可能会描述多个角度的语义信息,比如参与事件的任务、事件的起因、事件的发生地点等。所以作者提出了FBMA。
假定从一个句子中抽取出 m m m个角度,我们就需要 m m m个单词表示 u i t \mathbf{u}_{it} uit和上下文向量 u w \mathbf{u}_w uw间对齐的分数。为了得到 m m m维的输出 f i t \mathbf{f}_{it} fit,我们需要学习到参数 W = [ W 1 , . . . , W m ] ∈ R l × s h × m \mathbf{W} = [\mathbf{W}_1, ..., \mathbf{W}_m]\in \mathbf{R}^{l\times sh\times m} W=[W1,...,Wm]∈Rl×sh×m。
虽然双线性模型可以有效地捕获到交互信息,但是它需要大量的参数,计算量很大。受多模态低秩双线性池化方法(multi-modal low rank bilinear pooling )以及矩阵分解方法的启发,作者提出双线性映射矩阵 W i \mathbf{W}_i Wi可以分解成两个秩为1的矩阵 P \mathbf{P} P和 Q \mathbf{Q} Q。因此,式(4)可以重写为:
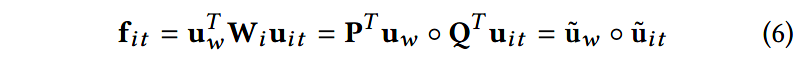
其中 P ∈ R l × m , Q ∈ R 2 h × m \mathbf{P}\in \mathbb{R}^{l\times m}, \mathbf{Q}\in \mathbb{R}^{2h\times m} P∈Rl×m,Q∈R2h×m是两个秩为1的矩阵, m m m是考虑的角度数量。 f i t ∈ R m \mathbf{f}_{it}\in \mathbb{R}^m fit∈Rm是对于单词 x i t \mathbf{x}_{it} xit的多角度的对齐向量。上式中的"圈"代表Hadamard乘积或者其他的元素级别的乘积。
注意,参照已有的工作,在过softmax之前,先对 f i t \mathbf{f}_{it} fit使用一层tanh。由于元素级别的乘积间差异很大,所以在Hadamard乘积后使用 l 2 l_2 l2正则层: f i t ← f i t ∣ ∣ f i t ∣ ∣ \mathbf{f}_{it}\leftarrow \frac{\mathbf{f}_{it}}{||\mathbf{f}_{it}||} fit←∣∣fit∣∣fit
然后,针对某一句子使用softmax函数计算多角度的注意力向量 α i t ∈ R m \mathbf{\alpha}_{it}\in \mathbb{R}^m αit∈Rm:
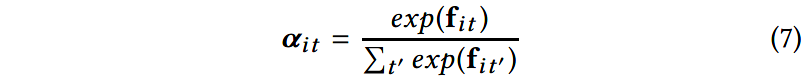
3.2.3 句子表示
令句子中所有单词的表示为 H i = ( h i 1 , h i 2 , . . . , h i T ) \mathbf{H}_i = (\mathbf{h}_{i1}, \mathbf{h}_{i2}, ..., \mathbf{h}_{iT}) Hi=(hi1,hi2,...,hiT)矩阵, H i ∈ R T × 2 h \mathbf{H}_i\in \mathbb{R}^{T\times 2h} Hi∈RT×2h。
令 A i = ( α i 1 , α i 2 , α i T ) \mathbf{A}_i=(\alpha_{i1}, \alpha_{i2}, \alpha_{iT}) Ai=(αi1,αi2,αiT)是句子多角度的注意力矩阵, A i ∈ R m × T \mathbf{A}_i\in \mathbb{R}^{m\times T} Ai∈Rm×T。
对于角度 j j j,给定 α i j = { α j 1 , α j 2 , . . . , α j T } \alpha_{ij} = {\{\alpha_{j1},\alpha_{j2},...,\alpha_{jT} }\} αij={αj1,αj2,...,αjT},在角度 j j j下句子的表示可以通过对所有的单词表示加权求和得到:
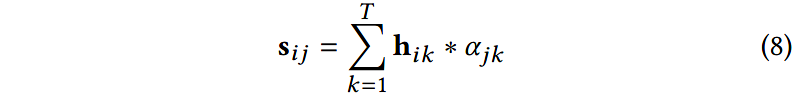
对所有的角度进行考虑,就可以得到句子最终的表示:
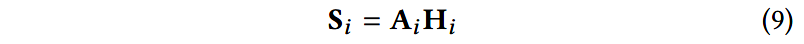
其中 S i ∈ R m × 2 h \mathbf{S}_i\in \mathbb{R}^{m\times 2h} Si∈Rm×2h是句子嵌入的矩阵,每一行表示在某一角度下句子的表示,每一行都包含在一个新角度下的注意力分布。将矩阵 S i \mathbf{S}_i Si拉平,所有行拼接起来得到 s i s_i si,以进行进一步的处理。
3.3 句子级别的注意力
一篇新闻文章由许多句子组成,只有一部分句子描述了事件,其他的只是阐述了事实,和事件相关的句子应该被赋予较高的权重。
以往的MIL方法采取的方式是:选取出top K个句子,并将它们的信息聚合。作者采用的是方式是:在句子上使用全局的注意力机制,以得到文档的表示。
给定文档的句子嵌入 { s 1 , . . . , s i , . . . , s n } {\{s_1, ..., s_i, ..., s_n }\} {s1,...,si,...,sn},首先进行如下的计算,得到句子的表示 h i \mathbf{h}_i hi:

然后,在所有句子上使用注意力机制,得到文档的表示:

其中, u s \mathbf{u}_s us是随机初始化的句子级别的上下文向量,在训练过程中会使用其他模型参数对其进行学习; d \mathbf{d} d是总结了文章中所有信息的文档表示。
给定文档的表示 d \mathbf{d} d,作者使用有2层隐层的MLP和dropout机制,以得到分类的分值:
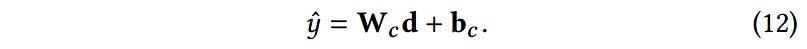
损失函数是标准的交叉熵损失:

对于句子的嵌入表示,如果注意力机制总是为 m m m个角度提供相似的权重,则式(9)可能会有冗余问题。为了关注每个角度一小部分的触发词以及增强多个角度的多样性,作者参考前人的工作,使用了一个惩罚项:
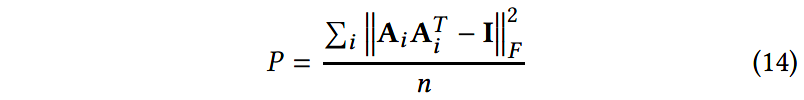
其中 ∣ ∣ ⋅ ∣ ∣ F ||\cdot||_F ∣∣⋅∣∣F表示矩阵的Frobenius范数,并针对文档中所有的句子求和。因此,最终的训练损失为:
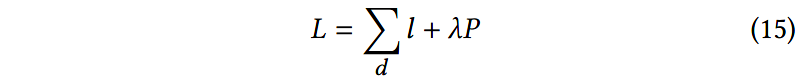
4 实验
(1)数据集

- MA(Military Actions):军队、警察或安全机构的行为
- NSA(Non-State Actor):无政府组织或个人的行为
(2)对比方法

(3)实验结果

BSA表示双线性单角度的注意力机制。


5 总结
本文解决的是事件检测(ED)问题。
本文使用了基于有层次的注意力机制的模型处理这一任务,这样可以生成单词和句子两个级别的表示。
使用这一有层次的模型,作者还提出了FBMA机制,在单词上计算得到多个注意力分布,生成含有上下文信息的句子表示和文档表示。
实验结果显示这一机制的表现效果优于其他方法,尤其是使用单角度注意力机制的方法。
而且,这一模型比其他的相似的方法使用的参数更少,可扩展性更好。
未来工作:对于每个角度的注意力权重,是否可以引入一些限制,以捕获到事件元素间共现的模式。这样就可以得到在不同角度上的更广泛的分布,有助于更准确地进行事件抽取。
本文的亮点在于使用了多角度的注意力机制,可以捕获到句子和文档中的多种语义信息。
模型的思路也很简单清晰,先使用多角度的注意力机制学习到句子级别的表示,然后再使用句子级别的表示采用相同的方式得到文档的表示。在建模过程中还使用到了bi-GRU,捕获前向和后向的上下文特征。
为了减少模型参数,提高可扩展性,作者借鉴了多模态低秩双线性池化和矩阵分解的思想,将双线性映射参数矩阵分解为两个秩为1的矩阵。
我认为不足之处在于:本文的模型目的是为文档预测标签,如果文档中有存在事件则标签为正。这样的话只能检测出文档中有没有事件,不能检测出文档中事件的个数。















 3688
3688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









