







第一课 初识Pascal语言
信息学奥林匹克竞赛是一项益智性的竞赛活动,核心是考查选手的智力和使用计算机解题的能力。选手首先应针对竞赛中题目的要求构建数学模型,进而构造出计算机可以接受的算法,之后要写出高级语言程序,上机调试通过。程序设计是信息学奥林匹克竞赛的基本功,在青少年朋友参与竞赛活动的第一步必须掌握一门高级语言及其程序设计方法。
一、Pascal 语言概述
PASCAL语言也是一种算法语言,它是瑞士苏黎世联邦工业大学的N.沃思(Niklaus Wirth)教授于1968年设计完成的,1971年正式发表。1975年,对PASCAL语言进行了修改,作为"标准PASCAL语言"。
PASCAL语言是在ALGOL 60的基础上发展而成的。它是一种结构化的程序设计语言,可以用来编写应用程序。它又是一种系统程序设计语言,可以用来编写顺序型的系统软件(如编译程序)。它的功能强、编译程序简单,是70年代影响最大一种算法语言。
二、Pascal 语言的特点
从使用者的角度来看,PASCAL语言有以下几个主要的特点:
⒈它是结构化的语言。PASCAL语言提供了直接实现三种基本结构的语句以及定义"过程"和"函数"(子程序)的功能。可以方便地书写出结构化程序。在编写程序时可以完全不使用GOTO语句和标号。这就易于保证程序的正确性和易读性。PASCAL语言强调的是可靠性、易于验证性、概念的清晰性和实现的简化。在结构化这一点上,比其它(如BASIC,FORTRAN77)更好一些。
⒉有丰富的数据类型。PASCAL提供了整数、实型、字符型、布尔型、枚举型、子界型以及由以上类型数据构成的数组类型、集合类型、记录类型和文件类型。此外,还提供了其它许多语言中所没有的指针类型。沃思有一个著名的公式:"算法+数据结构=程序"。指出了在程序设计中研究数据的重要性。丰富的数据结构和上述的结构化性质,使得PASCAL可以被方便地用来描述复杂的算法,得到质量较高的程序。
⒊能适用于数值运算和非数值运算领域。有些语言(如FORTRAN 66,ALGOL 60)只适用于数值计算,有些语言(如COBOL )则适用于商业数据处理和管理领域。PASCAL的功能较强,能广泛应用于各种领域。PASCAL语言还可以用于辅助设计,实现计算机绘图功能。
⒋PASCAL程序的书写格式比较自由。不象FORTRAN和COBOL那样对程序的书写格式有严格的规定。PASCAL允许一行写多个语句,一个语句可以分写在多行上,这样就可以使PASCAL程序写得象诗歌格式一样优美,便于阅读。
由于以上特点,许多学校选PASCAL作为程序设计课程中的一种主要的语言。它能给学生严格而良好的程序设计的基本训练。培养学生结构化程序设计的风格。但它也有一些不足之处,如它的文件处理功能较差等。三、Pascal语言程序的基本结构
任何程序设计语言都有着一组自己的记号和规则。PASCAL语言同样必须采用其本身所规定的记号和规则来编写程序。尽管不同版本的PASCAL语言所采用的记号的数量、形式不尽相同,但其基本成分一般都符合标准PASCAL的规定,只是某些扩展功能各不相同罢了。下面我们首先来了解Pascal语言的程序基本结构。
为了明显起见先举一个最简单的PASCAL程序例子: 【例1】
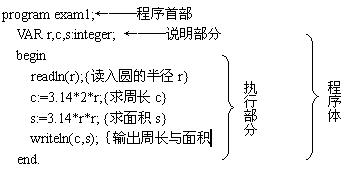
从这个简单的程序可以看到:
⒈一个PASCAL程序分为两个部分:程序首部和程序体(或称分程序)。
⒉程序首部是程序的开头部分,它包括:
⑴程序标志。用"program"来标识"这是一个PASCAL 程序"。PASCAL规定任何一个PASCAL程序的首部都必须以此字开头。在turbo pascal语言中,首部也可省略。
⑵程序名称。由程序设计者自己定义,如例中的exam1。
在写完程序首部之后,应有一个分号。
⒊程序体是程序的主体,在有的书本里也称"分程序"。程序体包括说明部分(也可省略)和执行部分两个部分。
⑴说明部分用来描述程序中用到的变量、常量、类型、过程与函数等。本程序中第二行是"变量说明",用来定义变量的名称、类型。
PASCAL规定,凡程序中用到所有变量、符号常量、数组、标号、过程与函数、记录、文件等数据都必须在说明部分进行定义(或称"说明")。也就是说,不允许使用未说明先使用。
⑵执行部分的作用是通知计算机执行指定的操作。如果一个程序中不写执行部分,在程序运行时计算机什么工作也不做。因此,执行部分是一个PASCAL程序的核心部分。
执行部分以"begin"开始,以"end"结束,其间有若干个语句,语句之间以分号隔开。
执行部分之后有一个句点,表示整个程序结束。
⒋PASCAL程序的书写方法比较灵活。当然,书写不应以节省篇幅为目的,而应以程序结构清晰、易读为目的。在编写程序时尽量模仿本书中例题程序格式。
⒌在程序中,一对大括号间的文字称为注释。注释的内容由人们根据需要书写,可以用英语或汉语表示。注释可以放在任何空格可以出现的位置。执行程序时计算机对注释不予理睬。
四、Turbo Pascal语言系统的使用
目前,常用的Pascal语言系统有Turbo Pascal7.0与Borland Pascal 7.0,下面我们就来学习Turbo Pascal 7.0系统的使用。 1. 系统的启动
在运行系统目录下的启动程序TURBO.EXE,即可启动系统。屏幕上出现如图1所示的集成环境。
2. Turbo Pascal系统集成环境简介
最顶上一行为主菜单。中间蓝色框内为编辑窗口,在它个编辑窗口内可以进行程序的编辑。最底下一行为提示行,显示出系统中常用命令的快捷键,如将当前编辑窗口中文件存盘的命令快捷键为F2,获得系统帮助的快捷键为F1,等等。
3. 新建程序窗口
按F10进行主菜单,选择FILE菜单,执行其中New命令。就可建立一个新的程序窗口(默认文件名为Noname00.pas或Noname01.pas等)。
4. 程序的输入、编辑与运行
在当前程序窗口中,一行一行的输入程序。事实上,程序窗口是一个全屏幕编辑器。所以对程序的编辑与其它编辑器的编辑方法类似,这里不再重复。
当程序输入完毕之后,一般要先按Alt+F9(或执行compile菜单中compile命令)对程序进行编译。如果程序有语法错误,则会在程序窗口的第一行处显示第一个红色错误信息。若无语法错误,则窗口正中央会出现一个对话框,提示编译成功。接下来,我们可以运行程序了。
程序的运行可以通过按ALT+R打开RUN菜单中的RUN命令,或直接按快捷键CTRL+F9。则可以在用户窗口中输出运行结果。通常在程序运行结束后系统回到Pascal系统的集成环境,因此要查看运行结果,要按ALT+F5将屏幕切换到用户屏幕。
5.程序的保存与打开
当我们想把程序窗口中的程序存入磁盘时,可以通过按F2键(或执行File菜单中的save命令)来保存程序。第一次保存文件时屏幕上会出现一个对话框要求输入文件名(默认扩展名为.pas)。
当我们要将磁盘上的程序文件中的PASCAL程序装入窗口时,可按F3(或执行File菜单中的Open命令)来装入程序,此时系统也会弹出一个对话框要求输入要打开的文件名,或直接在文件对话框列表中选择所要的文件,然后回到打开文件。
五、第一个程序
下面程序在运行时,会提示输入一个圆的半径,然后会在屏幕上画一个圆。按回车后程序结束回到程序窗口。
Program ex1;
Uses graph;
Var Gm,Gd,R :integer;
Begin
Gd:=0;
Write('Please enter the radius:');readln(R);
Initgraph(Gm,Gd,' ');
Setcolor(Green);
Circle(320,240,R);
Readln;
Closegraph;
End.
注意,如果上面程序运行时会出现初始化图形错误,请将系统目录下BGI子目录EGAVGA.BGI和UNITS子目录中的Graph.tpu拷贝到系统目录下BIN目录即可。
请输入上面的程序,并练习将其存盘、打开与运行上面程序。
上节课,我们学习了Pascal语言的程序基本结构,在一个程序中,所有的操作都由执行部分来完成,而执行部分又都是由一个个语句组成的。因此,下面开始我们要学习pascal语言的基本语句,并且在学习过程中逐步学会程序设计的基本方法。
这节课我们要学习两种语句,即赋值语句与输出语句。在语句学习之前我们要先了解一些pascal语言的基础知识。
一、 常量、变量与算术表达式
(一)常量
在程序运行过程中,其值不能被改变的量称为常量。如123,145.88,'abc',true等。
⒈整型常量
整型常量采用我们平常使用的十进制整数表示。如138,0,-512等都是整型常量,而18.或18.0都不是整型常量。
pascal中有一个标准标识符Maxint,它代表所使用的计算机系统允许的最大整型数,而最小的整型数即为-Maxint-1。
一个整型数据用来存放整数。Turbo Pascal支持五种预定义整型,它们是shortint(短整型)、 integer(整型)、 longint(长整型)、 byte(字节型)和 word(字类型),Turbo Pascal分别用相同的名字作为他们的表识符。每一种类型规定了相应的整数取值范围以及所占用的内存字节数。
类型 数值范围 占字节数 格式
shortint -128..128 1 带符号8位
inteter -32768..32767 2 带符号16位
longint -2147483648..2147483647 4 带符号32位
byte 0..255 1 带符号8位
word 0..65535 2 带符号16位
Turbo Pascal规定了两个预定义整型常量表识符maxint和maxlonint,他们各表示确定的常数值,maxint为32767, maxlongint为2147483647,他们的类型分别是integer 和longint。
⒉实型常量
实型常量包括正实数、负实数和实数零。pascal中表示实型常量的形式有两种。
⑴十进制表示法
这是人们日常使用的带小数点的表示方法。
如0.0,-0.0,+5.61,-8.0,-6.050等都是实型常量,而0.,.37都不是合法的实数形式。
⑵科学记数法
科学记数法是采用指数形式的表示方法,如1.25×105可表示成1.25E+05。在科学记数法中,字母"E"表示10这个"底数",而E之前为一个十进制表示的小数,称为尾数,E之后必须为一个整数,称为"指数"。 如-1234.56E+26 , +0.268E-5 , 1E5是合法形式,而.34E12 , 2.E5 , E5 ,E,1.2E+0.5都不是合法形式的实数。
无论实数是用十进制表示法还是科学表示法,它们在计算机内的表示形式是一样的,总是用浮点方式存储。
和整数相比,实数能表示的范围大得多,但值得注意的是实数的运算整数的运算速度慢且无法像整数那样精确表示,只能近似表示。
一个实型数据用类存放实数。Turbo Pascal支持五种预定义实型,它们是real(基本实型)、 single(但精度实型)、double(双精度实型)、extended(扩展实型)、comp(装配实型),Turbo Pascal分别用相同的名字作为他们的表识符。每一种类型规定了相应的实数取值范围、所占用的内存字节数以及它们所能达到的精度。
类型 数值范围 占字节数 有效位数
real 2.9e-39..1.7e38 6 11..12
single 1.5e-45..3.4e38 4 7..8
double 5.0e-324..1.7e308 8 15..16
extended 3.4e-4932..1.1e4932 10 19..20
comp -2**63+1..2**63-1 8 19..20
Turbo Pascal支持两种用于执行实型运算的代码生成模式:软件仿真模式和80x87浮点模式。除了real可以在软件仿真模式下直接运行以外,其他类型必须在80x87浮点模式下运行。
⒊字符常量
在Pascal语言中,字符常量是由单个字符组成,所有字符来自ASCII字符集,共有256个字符。在程序中,通常用一对单引号将单个字符括起来表示一个字符常量。如:'a','A','0'等。特殊地,对于单引号字符,则要表示成''''。对于ASCII字符集中,按每个字符在字符集中的位置,将每个字符编号为0-255,编号称为对应字符的序号。
4.布尔常量
布尔型常量仅有两个值,真和假,分别用标准常量名true和false表示。它们的序号分别为1和0。
5.符号常量
一个常量即可以直接用字面形式表示(称为直接常量, 如 124,156.8),也可以用一个标识符来代表一个常量,称为"符号常量"。但符号常量必须在程序中的说明部分定义,也就是说先定义,后使用。
定义符号常量的一般格式:
CONST
<常量标识符>=<常量>
说明:常量说明部分以关键字const开头, 后面的标识符为常量标识符,其中"="号后的常量为整数、实数、字符、 字符串(字符、字符串常量在后面章节中将作介绍)。而且,在常量说明部分可以将几个常量说明成符号常量,共用一个关键字"const"。例如:

则在本程序中pi和zero作为符号常量,分别代表实数3.14159和整数0。也就是说,常量说明部分既定义了常量名及其值,又隐含定义了常量的类型。 关于符号常量,应注意下列几点:
⑴符号常量一经定义,在程序的执行部分就只能使用该常量标识符,而不能修改其值。
⑵使用符号常量比直接用数值更能体现"见名知义"的原则,也便于修改参数,故一个较好的程序中,应尽量使用符号常量,在执行部分基本上不出现直接常量。
(二)变量
变量代表了一个存储单元,其中的值是可变的,故称为变量。如游戏"魂斗罗"中玩者命的个数最初为3,当你死了一次命减少一,这里命的个数就是一个变量(或者说命的个数存储在一个存储单元中)。即在程序运行过程中,其值可以改变的量,称为变量。
变量有三个要素是:变量名、变量类型、变量值。
一个程序中可能要使用到若干个变量,为了区别不同的变量,必须给每个变量(存贮单元)取一个名(称为变量名),该变量(存贮单元)存放的值称为变量的值,变量中能够存放值的类型为变量的类型。例如 "魂斗罗"游戏中用于存放"命"的变量,在游戏程序中的名字可取为N,它的类型为整型,游戏初始时这个变量的值为3。
1.变量名
用一个合法的标识符代表一个变量。如n,m,rot,total 等都是合法变量名。在程序中用到的变量必须在说明部分加以说明,变量名应遵循自定义标识符的命名规则,并注?quot;见名知义"的原则,即用一些有意义的单词作为变量名。
"自定义标识符"的命名规则为:自定义标识符必须以字母(包含下划线"_")开头,后面的字符可以是字母或数字。标识符长度不超过63个字符。
2.变量的类型
常量是有类型的数据,变量在某一固定时刻用来存放一个常量,因此也应有相应的类型。如整型变量用来存放整数,实型变量用来存放实数。
3.变量说明
在程序中若要使用变量,变量的名称及类型在程序的变量说明部分加以定义,变量的值则在程序的执行部分中才能赋给。
变量说明的一般格式:
VAR
<变量标识符>[,<变量标识符>]:<类型>;
(中括号内部分表示可省,下同)
其中VAR是pascal保留字,表示开始一个变量说明段, 每个变量标识符或由逗号隔开的多个变量标识, 必须在它的冒号后面说明成同一类型。一个程序中,可以说明许多不同类型的变量,每种类型变量之间用分号隔开,共用一个VAR符号。
例如:
var
age,day:integer;
amount,average:real;
其中,Integer(整型)、Real(实型)是标准标识符, 它们是"类型标识符",代表了确定的类型,如age和 day 被定义为整型变量,amount和average被定义为实型变量。
一旦定义了变量,就确定了它的类型,也就是说,就确定了该变量的取值范围和对该变量所能进行的运算。
(三)算术表达式
⑴算术表达式的定义
pascal语言中的算术表达式是由符合pascal语法规定的运算对象(包括常量、变量、函数)、算术运算符、圆括号组成的有意义的式子。如:A+3.14159*5/8.4-Abs(-1123)
⑵算术运算符
常用的有以下6个算术运算符:
① + (加)
② - (减)
③ * (乘)
④ / (实数除)得到结果为实型.如5.0/2.0=2.5, 5/2=2. 5,4/2=2.0而不等于2。
⑤ DIV (整除) DIV它要求除数和被除数均为整型, 结果也为整型。如10 DIV 2=5,10 DIV 3=3, 5 DIV 10=0.-15 DIV 4= -3。DIV运算只取商的整数部分,参与DIV运算的两个对象不能为实型。
⑥ mod (求余),也只能用于整数运算,结果为整数。例如:10 mod 4=2 , -17 mod 4= -1 , 4 mod (-3)=1, - 4 mod 3= -1,即 a mod b=a-(a div b)*b。
(3)运算优先顺序
如果一个表达式里出现两个或两个以上的运算符, 则必须规定它们的运算次序。pascal规定:
①表达式中相同优先级的运算符,按从左到右顺序计算;
②表达式中不同优先级的运算符,按从高到低顺序计算;
③括号优先级最高,从内到外逐层降低;
在算术运算中运算符的优先顺序与数学上的四则运算一致,即"先乘除后加减"(注:"MOD"、"DIV"运算的优先级与"*"、"/"相同)。
二、赋值语句
变量既然代表一个存储单元,其值是可变的,那么其中的值是怎么提供的,又是怎么改变的呢?可以通过赋值语句来进行。
1、 赋值语句的格式
变量名:=表达式;
其中":="称为赋值号。
2、 执行过程
计算机先计算赋值号右边表达式的值,然后将表达式的值赋给变量名代表的变量。如:A:=(9*8)-(2-1); A:=A+1
三、输出语句
输出语句的作用是将程序运算的结果输出到屏幕或打印机等输出设备。这里通常是指输出到屏幕。
(一)输出语句的两种格式
1、 write语句
格式Write(表达式1,表达式2,……);
如:write(1,2,3,4);
write(1.2,3.4,5);
write('My name is Liping');
2、 writeln语句
格式:
Write(表达式1,表达式2,……)或writeln
(二)输出语句的功能
计算机执行到某一输出语句时,先计算出输出语句中的每个表达式的值,并将每一个表达式的值一个接一个地输出到屏幕上。
Write语句与writeln语句格式上都相似,但它们在功能上有所不同,两个语句的区别在于,write语句将其后括号中的表达式一个接一个输出后,没有换行。而writeln语句则在输出各个表达式的值后换行。
例如以下两个程序段的输出分别为:
write(1,2,3,4);write(5,6);
输出为:
123456
writeln(1,2,3,4);write(5,6);
输出为:
1234
56
四、应用例析
例1:
某仓库5月1日有粮食100吨,5月2日又调进20吨,5月3日卖出库存的3分之二,5月4日又调进库存的3倍粮食,问该仓库从5月1日到5月4日期间每天的粮食分别是多少吨?(输出每天的库存量)
分析:在这个问题中,主要要描述从5月1日到5月4日期间仓库的粮食库存量,且易知它是不断变化的。因此我们可以用一个变量A来描述仓库的粮食库存量。
程序可写如下:
Program ex1;
Var A : integer;
Begin
A:=100;Writeln('5/1:',A);
A:=A+20;Writeln('5/2:',A);
A:=A div 3; writeln('5/3:',A);
A:=A *4; writeln('5/4:',A);Readln;
End.
例2:
有三个小朋友甲乙丙。甲有50粒糖果,乙有43粒糖果,两有13粒糖果。现在他们做一个游戏。从甲开始,将自己的糖分三份,自己留一份,其余两份分别给乙与丙,多余的糖果自己吃掉,然后乙与丙也依次这样做。问最后甲、乙、丙三人各有书多少粒糖果?
分析:
这个问题中我们关心的是在游戏过程中每个小朋友的糖果个数,且他们所拥有的的糖果数是在变化的。因此可用a,b,c三个变量分别存放甲乙丙三个小朋友在某一时刻所拥有的糖果数。对于每人,分糖后,他的糖果数一定为原来的糖果数 div 3(因为分糖过程糖果的数目不一定都刚好分完,用整除恰恰可以表示多余的糖自己吃掉)。而其他两人则增加与这个小朋友现在拥有的一样的糖果。
程序可写如下:
program ex2;
var A,B,C:integer;
begin
A:=50;B:=43;C:=13; {初始时每个小朋友所拥有的糖果数}
A:=A div 3; B:=B+A;C:=C+A;{甲小朋友分糖果后,每个人拥有的糖果数变化情况}
B:=B div 3; A:=A+B;C:=C+B; {乙小朋友分糖果后,每个人拥有的糖果数变化情况}
C:=C div 3; A:=A+C;B:=B+C; {丙小朋友分糖果后,每个人拥有的糖果数变化情况}
writeln('A=',A,'B=',B,'C=',C); {输出结果}
readln;
end.
注:
上程序中倒数第三行中'A='表示一个字符串(即用一对单引号括起来的一串字符),对于字符串,输出字符串的内容(即引号内的所得字符,而引号不输出)。
以上程序的运行结果为:
A=51B=35C=16
练习二
1、已知某梯形的上底A=13,下底B=18,高H=9,求它的面积S。
2、某机关组织游泳比赛。将一堆西瓜分给前三名,把该堆西瓜中的一半又半个西瓜奖给第一名;剩下的一半又半个西瓜给第二名;把最后剩下的一半又半个西瓜给第三名,但每次分时并没切开任何一个西瓜,且刚好西瓜分完。问前三名各分到多少个西瓜
3、已知某圆的半径R=139,求该圆的周长C与面积S?
一、写语句的输出格式
在pascal语言中输出数据时是可以按照一定格式的,对整数隐含的输出形式为按十进制数形式。对实数的输出,隐含的形式是科学记数法形式(如果不想用科学记数法输出而用小数形式输出,要自己另行定义)。
事实上,输出语句中的每个输出项中的表达式之后可以加上格式说明,若输出项后没有加格式说明, 则数据按系统隐含的格式输出,还可加上一定格式符号按特定格式输出。
⒈隐含的输出格式
pascal语言为整型量、实型量、布尔型量和字符串( 用一对单引号括起来的字符序列)规定了每种数据所占的宽度(即一个数据占几列) ,一个数据所占的宽度称为"场宽"或"字段宽"。系统给出的隐含场宽称为标准场宽。每一种pascal版本给定的标准场宽不尽相同。下表给出标准pascal和pc机上两种pascal版所规定的标准场宽。
标准场宽
━━━━━━━━━━━━━━━━━
数据类型 标准pascal Turbo pascal
─────────────────
integer 10 实际长度
real 22 17
布尔型 10 4或5
字符串 串长 串长
━━━━━━━━━━━━━━━━━
在Turbo Pascal系统中,对于整型字符串的输出都是按数据本身长度输出,对于布尔型数据(只有True和False两种值),TRUE为4列,FALSE为5列,一律采用大写输出。而real型数据的输出时,则按17列输出,其中第一列为符号位,正号不显示,后四位为"E±nn", 中间的12列为尾数部分。如:
writeln(sqrt(75));
则输出□8.6602540379E+00。
而writeln(sqrt(81));
则输出□9.0000000000E+00。
有时,在程序中往往根据实际情况,需要自己定义场宽。
⒉指定场宽
在写语句中输出项含有格式符号时,就是为了指定场宽。
⑴指定单场宽.
格式:write(表达式:N)或writeln(表达式:N),其中N为自然数,指定单场宽后,所有数据不再按标准场宽输出,而按指定场宽输出。若数据实际长度小于指定场宽时,则一律"向右靠齐,左留空格"。
如write(1234:8);write('abcdef':12)
输出结果:
□□□□1234□□□□□□abcdef
对于标准实型数据指定单场宽时,如果场宽大于标准场宽时,右靠齐按标准场宽格式输出17位,左留空格。若场宽小于标准场宽时,第一位仍为符号位,最后四位仍为"E±nn",中间部分为尾数显示部分。如果指定的宽度小于8位,则数据按8位格式"*.*E±nn "输出。
⑵指定双场宽
如果输出项是实数时,如果希望输出的实数不用科学记数法输出,而用小数形式输出,可以用指定双场宽方法输出。
双场宽输出格式为:write(实型表达式:m:n),其中m和n都是自然数,m 用以指定整个数据所占的宽度,n指定输出实数的小数位数。
如 : write(sqrt(75):9:4);
输出:□□□8.6602
如果双场宽不能满足输出数据的最低要求, 系统自动突破指定的场宽限制,按实际长度输出。
如:write(sqrt(75):5:4); 要使小数点后有4位数字,而总场宽为5,是不可能的(因为还有一个小数点, 小数点前面还有一个数字)。它最低限度要有6列,即输出为:
8.6602
例1
写出下列程序在turbo pascal下的输出结果.
program ex;
const s='abcdefg';
var
i:integer;
r:real;
c:char;b:boolean;
begin
i:=1234;r:=1234.5678;
c:='#';b:=true;
writeln(i,i:6,i:3);
writeln(r,r:12:5,r:8:5);
writeln(c,c:5);
writeln(s,s:10,s:5);
writeln(b,b:5,b:3);
end.
运行结果如下:
1234□□12341234
□1.2345678000E+03□□1234.567801234.56780
#□□□□#
abcdefg□□□abcdefgabcdefg
TRUE□TRUETRUE
3.应用例析
例2:
已知A=253,B=43,输出A*B的运算式子。即输出如下:
253*43=10879
253
* 43
759
+1012
10879
分析:
对于该问题,我们只要控制好输出时右靠齐即可。即前四行的总宽度一样(例如为12),第五行总宽度比前面少1。第六、七行总宽度与前四行一样。
参与程序如下:
var a,b:integer;
begin
a:=253;b:=43;
writeln(a:10,'*',b,'=',a*b);
writeln(a:12);
write('*':8);writeln(b:4);
writeln('--------':12);
writeln(a*3:12);
write('+':6);writeln(a*4:5);
writeln('--------':12);
writeln(a*b:12);
end.
二、 输入语句(读语句) 在程序中变量获得一个确定的值,固然可以用赋值语句,但是如果需要赋值的变量较多,或变量的值经常变化,则使用本节介绍的输入语句──读语句,将更为方便。读语句是在程序运行时由用户给变量提供数据的一种很灵活的输入动作,它有两种格式:
1.读语句的一般格式:
read(<变量名表>);
readln[(<变量名表>)];
其中变量名表是用逗号隔开的若干个变量名组成的。
功能:从标准输入文件(即INPUT,一般对应着键盘 )中读入数据,并依次赋给相应的变量。
说明:
①read和readln是标准过程名,它们是标准标识符。
②执行到read或readln语句时,系统处于等待状态,等待用户从键盘上输入数据,系统根据变量的数据类型的语法要求判断输入的字符是否合法。如执行read(a)语句,a是整型变量,则输入的字符为数字字符时是合法的,当输入结束时,则自动将刚接受的一串数字字符转换为整数赋给变量a。
③在输入数值型(整型或实型)数据时,数据间要用空格或回车分隔开各个数据,输入足够个数的数据,否则仍要继续等待输入,但最后一定要有回车,表示该输入行结束,直到数据足够,该读语句执行结束,程序继续运行。
例3.
设a、b、c为整型变量,需将它们的值分别赋以10,20,30,写出对应下列语句的所有可能输入格式。
Read(a,b,c);
解
根据③,即可列出所有可能输入格式
(a)10□20□30←┘
(b)10□20←┘
30←┘
(c)10←┘
20□30←┘
(d)10←┘
20←┘
30←┘
其中"←┘"表示回车键。下同。
④read语句与readln语句的第一个区别是:
read语句是一个接一个地读数据,在执行完本Read语句( 读完本语句中变量所需的数据)后,下一个读语句接着从该数据输入行中继续读数据,也就是说,不换行。如:
Read(a,b);
Read(c,d);
Read(e);
如果输入数据行如下:
1□2□3□4□5□6□←┘
则a,b,c,d,e的值分别为1,2,3,4,5,如果后面无读语句则数据6是多余的,这是允许的。
Readln则不同,在读完本Readln语句中变量所需的数据后, 该数据行中剩余的数据多余无用,或者说,在读完本Readln语句中变量所需数据后,一定要读到一个回车,否则多余的数据无用。
例4
设要达到例1同样的目的,但语句改为:
readln(a,b);readln(c)
则例3中的4种输入格式只有(b)(d)是有效的.
⑤readln语句与read语句的第二个区别是:read 后一定要有参数表,而readln可以不带参数表,即可以没有任何输入项, 只是等待读入一个换行符(回车)。经常用于暂停程序的运行,直到输入一个回车。
例5
设有下列语句:
read(a,b,c);
readln(d,e);
readln;
readln(f,g);
其中,所有变量均为整型。再设输入的数据如下:
1□2←┘
3□4□5□6□7□8←┘
9□10←┘
11←┘
12□13←┘
列表给出每个变量的值.
分析:
可以假想有一"数据位置指针",每读一个数据后,指针后移到该数据之后,每执行一个readln语句后,指针移到下一个数据行的开头。
各变量的值如下表所示。
━━━━━━━━━━━━━━━━━━━━━━━━━━
变量名 a b c d e f g
──────────────────────────
值 1 2 3 4 5 11 12
──────────────────────────
⑥为了避免可能出现的错误,建议在程序中按下列原则使用读语句:(A)如果没有特殊需要,在一个程序中尽量避免混合使用read语句和readln语句;(B)尽量用readln语句来输入数据, 一个数据行对应一个readln语句;(C)由于执行read或readln语句时, 系统不会提供任何提示信息,因此,编程时最好在readln语句之前加以适当提示,例如:
write('Input a,b,c:');
readln(a,b,c);
在执行时,屏幕上显示:
Input a,b,c:■
其中,"■"为光标。执行readln语句后,系统处于待待输入状态, 只有输入了所需数据后才继续往下执行。
三、顺序结构程序设计
到目前为止,我们可以用读、写语句和赋值语句编写一些简单的程序。通过阅读这些程序,可以逐步熟悉pascal程序的编写方法和应遵循的规则,为以后各章的学习打基础。
例6
试编一程序,输入一梯形的上底、下底、高, 求该梯形的面积。
分析:
整个程序分为三段:输入、计算、输出。程序中用a,b,h三个变量分别存放梯形的上、下底与高,S存放面积。 要而使用这些变量都要先说明,程序的执行部分中先输入上、下底与高,接着求面积S,最后输出结果S。
源程序如下:
program Tixing; {程序首部}
var a,b,h,s:real; {程序说明部分}
begin
write('Input a,b,h:');
readln(a,b,h); {程序执行部分}
s:=(a+b)*h/2;
write('s=',s:10:3);
end.
例7
某幼儿园里,有5个小朋友编号为1,2,3,4,5,他们按自己的编号顺序围坐在一张圆桌旁。他们身上都有若干个糖果,现在他们做一个分糖果游戏。从1号小朋友开始,将他的糖果均分三份(如果有多余的,则他将多余的糖果吃掉),自己留一份,其余两份分给他的相邻的两个小朋友。接着2号、3号、4号、5号小朋友也这如果做。问一轮后,每个小朋友手上分别有多少糖果。
分析:
这道问题与第二课中的例2基本一样,只不过这里有5位小朋友,且他们初始时糖果的数目不确定。这里用a,b,c,d,e分别存放5个小朋友的糖果。初始时它们的值改为由键盘输入。其它都与第二课中的例2类似。
参考程序如下:
program fentang;
var a,b,c,d,e:integer;
begin
write('Please Enter init numbers ');readln(a,b,c,d,e);
a:=a div 3;b:=b+a;e:=e+a;{1号均分后,1、2、5号的糖果数变化情况}
b:=b div 3;c:=c+b;a:=a+b;{2号均分后,1、2、3号的糖果数变化情况}
c:=c div 3;b:=b+c;d:=d+c;{3号均分后,2、3、4号的糖果数变化情况}
d:=d div 3;c:=c+d;e:=e+d;{4号均分后,3、4、5号的糖果数变化情况}
e:=e div 3;d:=d+e;a:=a+e;{5号均分后,4、5、1号的糖果数变化情况}
{输出结果}
writeln('a=',a);
writeln('b=',b);
writeln('c=',c);
writeln('d=',d);
writeln('e=',e);
readln;{暂停}
end.
例8
编一程序求半径为R的圆的周长与面积?
分析:
程序要先输入半径R,然后求周长c和面积s,最后输出c和s.
源程序如下:
program circle;
const PI=3.14159;
var r,c,s:real;
begin
write('Enter R=');readln(r);
c:=2*pi*r;
s:=pi*sqr(r);
writeln('c=',c:10:2);
writeln('s=',s:10:2);
end.
在程序中,为了输出实型周长C和面积S时,按照小数形式输出,采用了指定双场宽格式。
练习三
1. 编一程序,将摄氏温度换为华氏温度。公式为:
其中f为华氏温度,c是摄氏温度。
2. 编一程序,输入三角形的三边a、b、c(假设这三边可以构成一个三角形),求三角形的面积S?
(提示:可利用海伦公式
在现实生活中,我们每天都要进行根据实际情况进行选择。例如,原打算明天去公园,但如果明天天气不好,将留在家里看电视。所以人也会根据条件进行行为的选择。计算机也会根据不同情况作出各种逻辑判断,进行一定的选择。在这课与下一课中,我们将会发现,我们是通过选择结构语句来实现程序的逻辑判断功能。
一、PASCAL中的布尔(逻辑)类型
在前面,我们学习了整型(integer)与实型(real)。其中integer型数据取值范围为-32768到32767之间所有整数。而real型数据取值范围为其绝对值在10-38到1038之间的所有实数。它们都是数值型的(即值都为数)。布尔型(Boolean)是一种数据的类型,这种类型只有两种值,即"真"与"假"。
1、 布尔常量
在Pascal语言中"真"用ture表示,"假"用False表示。所以布尔类型只有TRUE与FALSE两个常量。
2、 布尔变量(BOOLEAN)
如果我们将某些变量说明成布尔型,那么这些变量就是布尔变量,它们只能用于存放布尔值(ture或false)。
例如,VAR A,B:BOOLEAN;
3、 布尔类型是顺序类型
由于这种类型只有两个常量,Pascal语言中规定ture的序号为1,false的序号为0。若某种类型的常量是有限的,那么这种类型的常量通常都有一个序号,我们称这种类型为顺序类型。如前面我们学过的整型(integer),以及后面要学到的字符型(char)都是顺序类型。
4、 布尔类型的输入与输出
a)输出
VAR A,B:BOOLEAN;
BEGIN
A:=TRUE;B:=FALSE;
WRITELN(A,B);
END.
TRUEFALSE
b)布尔类型变量不能直接用读语句输入
布尔类型变量不能通过读语句给它们提供值。事实上,我们可以通过间接方式对布尔变量进行值的输入。
例如,以下程序是错误的:
var a,b,c:Boolean;
begin
readln(a,b,c); {错误语句}
writeln(a,b,c);
end.
二、关系表达式与布尔表达式
1、什么是关系表达式
用小括号、>、<、>=、<=、=、<>将两个算术表达式连接起来的式子就称为关系表达式(比较式)。
如:3+7>8,x+y<10,2*7<=13等都是关系表达式。
2、关系表达式的值
很显然,这几个关系表达式中第一个是正确的,第三个是错误的,而第二个表达式可能是对的,也可能是错的。所以我们很容易发现,这些表达式的值是"对"的或"不对"的(或者说,是"真"的或"假"的),即关系表达式的值为布尔值。表示该比较式两端式子的大小关系是否成立。如3+2>6是错的,故它的值为FALSE。同样,45>=32是对的,故该表达式的值为true。
关系表达式用于表示一个命题。如:"m为偶数"可表示为:m mod 2=0。"n为正数"可表示为:n>0。
3.布尔运算及布尔表达式
为了表示更复杂的命题,Pascal还引入三种逻辑运算符:not、and、or。它们分别相当于数学上的"非"、"且"和"或"的意义。
这三个运算符的运算对象为布尔量,其中not为单目运算,只有一个运算对象,and与or为双目运算,有两个运算对象。它们的运算真值表如下:
| a | b | Not a | a and b | a or b | a xor b |
| false | false | true | false | false | false |
| false | true | true | false | ture | true |
| true | false | false | false | true | true |
| true | true | false | true | true | false |
于是,对于一个关系表达式,或多个关系表达式用布尔运算符连接起来的式子就称为布尔表达式。布尔表达式的值也为布尔值。
如果一个表达式里出现两个或两个以上的运算符, 则必须规定它们的运算次序。pascal规定:
①表达式中相同优先级的运算符,按从左到右顺序计算;
②表达式中不同优先级的运算符,按从高到低顺序计算;
③括号优先级最高,从内到外逐层降低;
对于一个复杂的表达式可能同时包含算术运算、关系运算和逻辑运算以及函数运算。运算的优先顺序为:括号à函数ànotà*、/、div、mod、andà+、-、or、xorà关系运算。
对于复杂的命题,我们可以用布尔表达式来表示。例如,命题:"m,n都是偶数或都是奇数"可表示为"(m mod 2=0)and(n mod 2=0) or(m mod 2=1)and(n mod 2=1)"。
三、简单的IF语句
1、格式
Ⅰ、IF <布尔表达式>THEN 语句;
Ⅱ、IF <布尔表达式>THEN 语句1 ELSE 语句2;
(注意Ⅱ型IF语句中语句1后无";"号)
2、功能 Ⅰ、执行IF语句时,先计算<布尔表达式>的值,若为TRUE则执行语句,否则不执行任何操作。
Ⅱ、执行IF语句时,先计算<布尔表达式>的值,若为TRUE则执行语句1,否则执行语句2;
3、示例
1)例4.2输入一个整数a,判断是否为偶数。(是输出"yes"否则输出"no")。
Program ex4_2;
Var a:integer;
Begin
Write('a=');readln(a);
If (a mod 2 =0)then writeln('yes')
Else writeln('no');
Readln;
End.
2)华榕超市里卖电池,每个电池8角钱,若数量超过10个,则可打75折。
Program ex4_3;
Var Num:integer;Price,Total:real;
Begin
Write('Num=');readln(Num);
Price=0.8;
If Num>10 then Price:=Price*0.75;
Total:=Num*Price;
Writeln('Total=',Total:0:2);
Readln;
End.
3)编写一与电脑猜"红"或"黑"的游戏。
分析:用1代表红,0代表黑。先由计算机先出答案,然后再由人猜,猜对输出"YOU WIN"否则输出"YOU LOST"。为了模拟猜"红"或"黑"的随意性,程序中需要用到随机函数random(n)。
函数是什么呢,例如大家都知道|-2|=2,|58|=58,那么|x|=?。
如果我们用y表示|x|,那么 .这里y=|x|就是一个函数,也就是说函数是一个关于一个或多个自变量(未知量,如上例中的x)的运算结果。
在pascal语言中,系统提供了许多内部函数,其中包括|x|函数,当然它用abs(x)表示。我们如果要求x2-y的绝对值,可以调用内部函数abs(x*x-y)即可求得。Random(n)也是一个内部函数,调用它能得到0~n-1之间的整数(但它不确定的,或说是随机的)。同时由于函数是一个运算结果,所以函数的调用只能出现在表达式中。
Program ex4_3;
Uses crt;
Var Computer,People:integer;
Begin
Randomize;
Computer:=random(2);
Write('You guess(0-Red 1-Black):');readln(People);
If People=Computer then writeln('YOU WIN')
Else writeln('YOU LOST');
Readln;
End.
作业:.某车站行李托运收费标准是:10公斤或10公斤以下,收费2.5元,超过10公斤的行李,按每超过1公斤增加1.5元进行收费。 试编一程序,输入行李的重量,算出托运费。
一、IF语句的嵌套
在if语句中,如果then子句或else子句仍是一个if语句, 则称为if语句的嵌套。
例1 计算下列函数
分析:根据输入的x值,先分成x>0与x≤0两种情况,然后对于情况x≤0,再区分x是小于0,还是等于0。
源程序如下:
program ex;
var
x:real;
y:integer;
begin
wrtie('Input x:');readln(x);
if x>0 then y:=1{x>0时,y的值为1}
else {x≤0时}
if x=0 then y:=0
else y:=-1;
writeln('x=',x:6:2,'y=',y);
end.
显然,以上的程序中,在then子句中嵌套了一个Ⅱ型if语句。当然程序也可以写成如下形式:
program ex;
var
x:real;y:integer;
begin
wrtie('Input x:');readln(x);
if x>=0 then
if x>0 then y:=1
else y:=0
else y=-1;
writeln('x=',x:6:2,'y=',y);
end.
但是对于本题,下面的程序是不对的。
y:=0;
if x>=0 then
if x>0 then y:=1
else y:=-1;
明显,从此人的程序书写格式可以看出,他想让else与第一个if配对,而事实上,这是错的。因为pascal规定:else与它上面的距它最近的then配对,因此以上程序段的逻辑意义就与题义不符。
要使上程序段中esle与第一个then配对,应将程序段修改为:
y:=0; 或者 y:=0;
if x>=0 if x>=0
then if x>0 then
then y:=1 begin
else if x>0 then Y:=1;
else y:=-1; end
else Y:=-1;
二、case语句
上面我们知道可以用嵌套的if语句实现多分支的选择结构。但是如果分支越来越多时,用嵌套的if语句实现多分支就显得繁杂。当多分支选择的各个条件由同一个表达式的不同结果值决定时,可以用case语句实现。它的选择过程,很象一个多路开关,即由case语句的选择表达式的值,决定切换至哪一语句去工作。因此在分支结构程序设计中,它是一种强有力的手段。在实现多路径分支控制时,用case对某些问题的处理和设计,比用if语句写程序具有更简洁、清晰之感。
(一)、情况语句的一般形式:
case <表达式> of
<情况标号表1>:语句1;
<情况标号表2>:语句2;
:
<情况标号表n>:语句n
end;
其中case、of、end是Pascal的保留字, 表达式的值必须是顺序类型,它可以是整型、布尔型及以后学习的字符型、枚举型和子界型。情况标号表是一串用逗号隔开的与表达式类型一致的常量序列。语句可以是任何语句,包括复合语句和空语句。
(二)、case语句的执行过程
先计算表达式(称为情况表达式)的值,如果它的值等于某一个常量(称为情况常量,也称情况标号),则执行该情况常量后面的语句,在执行完语句后,跳到case语句的末尾end处。
(三)、说明
①情况表达式必须是顺序类型的;
②情况常量是情况表达式可能具有的值,因而应与情况表达式具有相同的类型;
③情况常量出现的次序可以是任意的;
④同一情况常量不能在同一个case语句中出现两次或两次以上;
⑤每个分语句前可以有一个或若干个用逗号隔开的情况常量;
⑥如果情况表达式的值不落在情况常的范围内,则认为本case语句无效,执行case语句的下一个语句。turbo pascal中增加了一个"否则"的情况,即增加一个else子句,但也是可省的。
⑦每个常量后面只能是一个语句或一个复合语句。
例2 根据x的值,求函数Y的值:
分析:利用case语句进行程序设计, 关键在于巧妙地构造情况表达式。本例中三种情况可用一个表达式区分出来:Trunc(x/100)。因为x在(0~100)之间时表达式值为0;x在[100,200)时表达式值为1 ;其余部分可用else子句表示。
源程序如下:
program ex;
var x,y:real;
begin
write('Input x:');readln(x);
case trunc(x/100) of
0:y:=x+1;
1:y:=x-1;
else y:=0;
end;{end of case}
writeln('x=',x:8:2),'y=',y:8:2);
end.
三、选择结构的程序设计
例3 输入一个年号,判断它是否是闰年。
分析:判断闰年的算法是:如果此年号能被400除尽, 或者它能被4整除而不能被100整除,则它是闰年。否则,它是平年。
源程序如下:
program ex;
var year:integer;
begin
write('Input year:');readln(year);
write(year:6);
if (year mod 400=0 ) then
writeln('is a leap year.')
else
if (year mod 4=0)and(year mod 100<>0)
then writeln('is a leap year.')
else writeln('is not a leap year.');
end.
例4 判断1995年,每个月份的天数。
分析:程序分为:输入月份,计算该月的天数,输出天数
源程序如下:
program days;
var month,days:integer;
begin
write('Input month:');readln(month);
case month of
1,3,5,7,8,10,12:days:=31;
4,6,9,11 :days:=30;
2 :days:=28;
else days:=0;
end;
if days<>0 then writeln('Days=',days);
end.
例5 期未来临了,班长小Q决定将剩余班费X元钱,用于购买若干支钢笔奖励给一些学习好、表现好的同学。已知商店里有三种钢笔,它们的单价为6元、5元和4元。小Q想买尽量多的笔(鼓励尽量多的同学),同时他又不想有剩余钱。请您编一程序,帮小Q制订出一种买笔的方案。
分析:对于以上的实际问题,要买尽量多的笔,易知都买4元的笔肯定可以买最多支笔。因此最多可买的笔为x div 4支。由于小q要把钱用完,故我们可以按以下方法将钱用完:
若买完x div 4支4元钱的笔,还剩1元,则4元钱的笔少买1支,换成一支5元笔即可;若买完x div 4支4元钱的笔,还剩2元,则4元钱的笔少买1支,换成一支6元笔即可;若买完x div 4支4元钱的笔,还剩3元,则4元钱的笔少买2支,换成一支5元笔和一支6元笔即可。
从以上对买笔方案的调整,可以看出笔的数目都是x div 4,因此该方案的确为最优方案。
源程序如下:
program pen;
var a,b,c:integer;{a,b,c分别表示在买笔方案中,6元、5元和4元钱笔的数目}
x,y:integer;{x,y分别表示剩余班费和买完最多的4元笔后剩的钱}
begin
write('x=');readln(x){输入x}
c:=x div 4;{4元笔最多买的数目}
y:=x mod 4;{求买完c支4元笔后剩余的钱数y}
case y of
0 : begin a:=0;b:=0; end;
1 : begin a:=0;b:=1;c:=c-1; end;
2 : begin a:=1;b:=0; c:=c-1;end;
3 : begin a:=1;b:=1; c:=c-2;end;
end;
writeln('a=',a,'b=',b,'c=',c);
end.
练 习
1.输入三角形的三个边,判断它是何类型的三角形(等边三角形?等腰三角形?一般三角形?)。
2.输入三个数,按由大到小顺序打印出来。
3.计算1901年2099年之间的某月某日是星期几。
4.输入两个正整数a,b。b最大不超过三位数,a不大于31。使a在左,b在右,拼接成一个新的数c。例如:a=2,b=16,则c=216;若a=18,b=476,则c=18476。
提示:求c的公式为:
c=a×K+b
其中:
在实际应用中,会经常遇到许多有规律性的重复运算,这就需要掌握本章所介绍的循环结构程序设计。在Pascal语言中,循环结构程序通常由三种的循环语句来实现。它们分别为FOR循环、当循环和直到循环。通常将一组重复执行的语句称为循环体,而控制重复执行或终止执行由重复终止条件决定。因此,重复语句是由循环体及重复终止条件两部分组成。
一、for语句的一般格式
for <控制变量>:=<表达式1> to <表达式2> do <语句>;
for <控制变量>:=<表达式1> downto <表达式2> do <语句>;
其中for、to、downto和do是Pascal保留字。表达式1 与表达式2的值也称为初值和终值。
二、For语句执行过程
①先将初值赋给左边的变量(称为循环控制变量);
②判断循环控制变量的值是否已"超过"终值,如已超过,则跳到步骤⑥;
③如果末超过终值,则执行do后面的那个语句(称为循环体);
④循环变量递增(对to)或递减(对downt o)1;
⑤返回步骤②;
⑥循环结束,执行for循环下面的一个语句。
三、说明
①循环控制变量必须是顺序类型。例如,可以是整型、字符型等,但不能为实型。
②循环控制变量的值递增或递减的规律是:选用to则为递增;选用downto则递减。
③所谓循环控制变量的值"超过"终值,对递增型循环,"超过"指大于,对递减型循环,"超 过"指小于。
④循环体可以是一个基本语句,也可以是一个复合语句。
⑤循环控制变量的初值和终值一经确定,循环次数就确定了。但是在循环体内对循环变量的值进行修改,常常会使得循环提前结束或进入死环。建议不要在循环体中随意修改控制变量的值。
⑥for语句中的初值、终值都可以是顺序类型的常量、变量、表达式。
四、应用举例
例1.输出1-100之间的所有偶数。
var i:integer;
begin
for i:=1 to 100 do
if i mod 2=0 then write(i:5);
end.
例2.求N!=1*2*3*…*N ,这里N不大于10。
分析:程序要先输入N,然后从1累乘到N。
程序如下:
var
n,i : integer;{i为循环变量}
S : longint;{s作为累乘器}
begin
write('Enter n=');readln(n);{输入n}
s:=1;
for i:=2 to n do{从2到n累乘到s中}
s:=s*i;
writeln(n,'!=',s);{输出n!的值}
end.
练 习
1. 求s=1+4+7+…+298的值。
2. 编写一个评分程序,接受用户输入10个选手的得分(0-10分),然后去掉一个最高分和一个最低分,求出某选手的最后得分(平均分)。
3. 用一张一元票换1分、2分和5分的硬币,每种至少一枚, 问有哪几种换法(各几枚)?
一、WHILE循环
对于for循环有时也称为计数循环,当循环次数未知,只能根据某一条件来决定是否进行循环时,用while 语句或repeat语句实现循环要更方便。
while语句的形式为:
while <布尔表达式> do<语句>;
其意义为:当布尔表达式的值为true时,执行do后面的语句。
while语句的执行过程为:
①判断布尔表达式的值,如果其值为真,执行步骤2,否则执行步骤4;
②执行循环体语句(do后面的语句);
③返回步骤1;
④结束循环,执行while的下一个语句。
说明:这里while和do为保留字,while语句的特点是先判断,后执行。 当布尔表达式成立时,重复执行do后面的语句(循环体)。
例1 、求恰好使s=1+1/2+1/3+…+1/n的值大于10时n的值。
分析:"恰好使s的值大于10"意思是当表达式s的前n-1项的和小于或等于10,而加上了第n项后s的值大于10。从数学角度,我们很难计算这个n的值。故从第一项开始,当s的值小于或等于10时,就继续将下一项值累加起来。当s的值超过10时,最后一项的项数即为要求的n。
程序如下:
var
s : real;
n : integer;{n表示项数}
begin
s:=0.0;n:=0;
while s<=10 do{当s的值还未超过10时}
begin
n:=n+1;{项数加1}
s:=s+1/n;{将下一项值累加到s}
end;
writlen('n=',n);{输出结果}
end.
例2、求两个正整数m和n的最大公约数。
分析:求两个正整数的最大公约数采用的辗转相除法求解。以下是辗转的算法:
分别用m,n,r表示被除数、除数、余数。
①求m/n的余数r.
②若r=0,则n为最大公约数.若r≠0,执行第③步.
③将n的值放在m中,将r的值放在n中.
④返回重新执行第①步。
程序如下:
program ex4_4;
var m,n,a,b,r:integer;
begin
write('Input m,n:');
readln(m,n);
a:=m;b:=n;r:=a mod b;
while r<>0 do
begin
a:=b;b:=r;
r:=a mod b;
end;
writeln('The greatest common divide is:',b:8);
end.
二、直到循环(REPEAT-until语句)
用while语句可以实现"当型循环",用repeat-until 语句可以实现"直到型循环"。repeat-until语句的含义是:"重复执行循环,直到指定的条件为真时为止"。
直到循环语句的一般形式:
Repeat
<语句1>;
:
<语句n>;
until <布尔表达式>;
其中Repeat、until是Pascal保留字,repeat与until之间的所有语句称为循环体。
说明:
①repeat语句的特点是:先执行循环,后判断结束条件,因而至少要执行一次循环体。
②repeat-until是一个整体,它是一个(构造型)语句,不要误认为repeat是一个语句, until是另一个语句。
③repeat语句在布尔表达式的值为真时不再执行循环体,且循环体可以是若干个语句,不需用begin和end把它们包起来, repeat 和until已经起了begin和end的作用。while循环和repeat循环是可以相互转化的。
对于例2中求两个正整数的最大公约数,程序可用repeat-until循环实现如下:
var
m,n,a,b,r : integer;
begin
write('Input m,n=');
readln(m,n);
a:=m;b:=n;
repeat
r:=a mod b;
a:=b;b:=r;
until r=0;
writeln('The greatest common divide is',a);
end.
以上我们已介绍了三种循环语句。一般说来,用for 循环比较简明,只要能用for循环,就尽量作用for循环。只在无法使用for循环时才用while循环和repeat-until循环, 而且 while 循环和repeat-until循环是可以互相替代的。for循环在大多数场合也能用whiel和repeat-until循环来代替。一般for循环用于有确定次数循环,而while和repeat-until循环用于未确定循环次数的循环。
当一个循环的循环体中又包含循环结构程序时,我们就称之为循环嵌套。
三、循环结构程序设计
例3 求1!+2!+…+10!的值。
分析:这个问题是求10自然数的阶乘之和,可以用for 循环来实现。程序结构如下:
for n:=1 to 10 do
begin
①N!的值àt
②累加N!的值t
end
显然,通过10次的循环可求出1!,2!…,10!,并同时累加起来, 可求得S的值。而求T=N!,又可以用一个for循环来实现:
t=1;
for j:=1 to n do
t:=t*j;
因此,整个程序为:
program ex4_5;
var t,s:real;
i,j,n:integer;
begin
S:=0;
for n:=1 to 10 do
begin
t:=1;
for j:=1 to n do
t:=t*j;
S:=S+t;
end;
writeln('s=',s:0:0);
end.
以上的程序是一个二重的for循环嵌套。这是比较好想的方法,但实际上对于求n!,我们可以根据求出的(n-1)!乘上n即可得到,而无需重新从1再累乘到n。
程序可改为:
program ex4_5;
var t,s:real;
i,j,n:integer;
begin
S:=0;t:=1;
for n:=1 to 10 do
begin
t:=t*n;
S:=S+t;
end;
writeln('s=',s:0:0);
end.
显然第二个程序的效率要比第一个高得多。第一程序要进行1+2+…+10=55次循环,而第二程序进行10次循环。如题目中求的是1!+2!+…+1000!,则两个程序的效率区别更明显。
例4 一个炊事员上街采购,用500元钱买了90只鸡, 其中母鸡一只15元,公鸡一只10元,小鸡一只5元,正好把钱买完。问母鸡、公鸡、小鸡各买多少只?
分析:设母鸡I只,公鸡J只,则小鸡为90-I-J只,则15*I+ 10* J+(90-I-J)*5=500,显然一个方程求两个未知数是不能直接求解。必须组合出所有可能的i,j值,看是否满足条件。这里I的值可以是0到33,J的值可以0到50。
源程序如下:
programr ex4_6;
var i,j,k:integer;
begin
for i:=1 to 5 do
for j:=1 to 8 do
begin
k:=90-i-j;
if 15*i+10*j+5*k=500 then writeln(i:5,j:5,k:5);
end;
end.
例5、求100-200之间的所有素数。
分析:我们可对100-200之间的每一整数进行判断,判断它是否为素数,是则输出。而对于任意整数i,根据素数定义,我们从2开始,到 ,找i的第一个约数。若找到第一个约数,则i必然不是素数。否则i为素数。
源程序如下:
var
i : integer;
x : integer;
begin
for i:=100 to 200 do
begin
x:=2;
while (x<=trunc(sqrt(i)))and(i modx<>0)do
begin
x:=x+1;
end;
if x>trunc(sqrt(i)) then write(i:8);
end;
end.
练 习
1、输入一个正整数n,将n分解成质因数幂的乘积形式。
例如:36=22*32
2、输出如下图形。
3、编写一程序,验证角谷猜想。所谓的角谷猜想是:"对于任意大于1的自然数n,若n为奇数,则将n变为3*n+1,否则将n变为n的一半。经过若干次这样的变换,一定会使n变为1。"
4.有一堆100多个的零件,若三个三个数,剩二个;若五个五个数,剩三个;若七个七个数,剩五个。请你编一个程序计算出这堆零件至少是多少个?
一、为什么要使用数组
例1 输入50个学生的某门课程的成绩,打印出低于平均分的同学号数与成绩。
分析:在解决这个问题时,虽然可以通过读入一个数就累加一个数的办法来求学生的总分,进而求出平均分。但因为只有读入最后一个学生的分数以后才能求得平均分,且要打印出低于平均分的同学,故必须把50个学生的成绩都保留下来, 然后逐个和平均分比较,把高于平均分的成绩打印出来。如果,用简单变量a1,a2,…,a50存放这些数据,可想而知程序要很长且繁。
要想如数学中使用下标变量ai形式表示这50个数,则可以引入下标变量a[i]。这样问题的程序可写为:
tot:=0;{tot表示总分}
for i:=1 to 50 do {循环读入每一个学生的成绩,并累加它到总分}
begin
read(a[i]);
tot:=tot+a[i];
end;
ave:=tot/50;{计算平均分}
for i:=1 to 50 do
if a[i]<ave then writeln('No.',i,' ',a[i]);{如果第i个同学成绩小于平均分,则将输出}
而要在程序中使用下标变量,则必须先说明这些下标变量的整体―数组,即数组是若干个同名(如上面的下标变量的名字都为a)下标变量的集合。
二、一维数组
当数组中每个元素只带有一个下标时,我们称这样的数组为一维数组。
1、一维数组的定义
(1)类型定义
要使用数组类型等构造类型以及第6章要学习的自定义类型(枚举类型与子界类型),应在说明部分进行类型说明。 这样定义的数据类型适用整个程序。
类型定义一般格式为:
type
<标识符1>=<类型1>;
<标识符2>=<类型2>;
:
<标识符n>=<类型n>;
其中type是Pascal保留字,表示开始一个类型定义段。在其后可以定义若干个数据类型定义。<标识符>是为定义的类型取的名字, 称它为类型标识符。
类型定义后,也就确定了该类型数据取值的范围,以及数据所能执行的运算。
(2)一维数组类型的定义
一维数组类型的一般格式:
array[下标1..下标2] of <基类型>;
说明:其中array和of是pascal保留字。下标1和下标2 是同一顺序类型,且下标2的序号大于下标1的序号。它给出了数组中每个元素(下标变量) 允许使用的下标类型,也决定了数组中元素的个数。基类型是指数组元素的类型,它可以是任何类型,同一个数组中的元素具有相同类型。因此我们可以说,数组是由固定数量的相同类型的元素组成的。
再次提请注意:类型和变量是两个不同概念,不能混淆。就数组而言,程序的执行部分使用的不是数组类型(标识符)而是数组变量(标识符)。
一般在定义数组类型标识符后定义相应的数组变量,如:
type arraytype=array[1..8]of integer;
var a1,a2:arraytype;
其中arraytype为一个类型标识符,表示一个下标值可以是1到 8,数组元素类型为整型的一维数组;而a1,a2则是这种类型的数组变量。
也可以将其全并起来:
var a1,a2:array[1..8]of integer;
当在说明部分定义了一个数组变量之后,pascal 编译程序为所定义的数组在内存空间开辟一串连续的存储单元。
例如,设程序中有如下说明:
type rowtype=array[1..8]of integer;
coltype=array['a'..'e']of integer;
var a:rowtype;b:coltype;
2、一维数组的引用
当定义了一个数组,则数组中的各个元素就共用一个数组名( 即该数组变量名),它们之间是通过下标不同以示区别的。 对数组的操作归根到底就是对数组元素的操作。一维数组元素的引用格式为:
数组名[下标表达式]
说明:①下标表达式值的类型, 必须与数组类型定义中下标类型完全一致,并且不允许超越所定义的下标下界和上界。
②数组是一个整体,数组名是一个整体的标识,要对数组进行操作,必须对其元素操作。数组元素可以象同类型的普通变量那样作用。如:a[3]:=34;是对数组a中第三个下标变量赋以34的值。read(a[4]);是从键盘读入一个数到数组a第4个元素中去。
特殊地,如果两个数组类型一致,它们之间可以整个数组元素进行传送。如:
var a,b,c:array[1..100] of integer;
begin
c:=a;a:=b;b:=c;
end.
在上程序中,a,b,c三个数组类型完全一致, 它们之间可以实现整数组传送,例子中,先将a数组所有元素的值依次传送给数组c,同样b数组传给a,数组c又传送给b,上程序段实际上实现了a,b 两个数组所有元素的交换。
对于一维数组的输入与输出, 都只能对其中的元素逐个的输入与输出。在下面的应用示例中将详细介绍。
三、一维数组应用示例
例2 输入50个数,要求程序按输入时的逆序把这50个数打印出来。也就是说,请你按输入相反顺序打印这50个数。
分析:我们可定义一个数组a用以存放输入的50个数, 然后将数组a内容逆序输出。
源程序如下:
program ex5_1;
type arr=array[1..50]of integer; {说明一数组类型arr}
var a:arr;i:integer;
begin
writeln('Enter 50 integer:');
for i:=1 to 50 do read(a[i]);{从键盘上输入50个整数}
readln;
for i:=50 downto 1 do {逆序输出这50个数}
write(a[i]:10);
end.
例3 输入十个正整数,把这十个数按由小到大的顺序排列。
将数据按一定顺序排列称为排序,排序的算法有很多,其中选择排序是一种较简单的方法。
分析:要把十个数按从小到大顺序排列,则排完后,第一个数最小,第二个数次小,……。因此,我们第一步可将第一个数与其后的各个数依次比较,若发现,比它小的,则与之交换,比较结束后,则第一个数已是最小的数(最小的泡往下冒)。同理,第二步,将第二个数与其后各个数再依次比较,又可得出次小的数。如此方法进行比较,最后一次,将第九个数与第十个数比较,以决定次大的数。于是十个数的顺序排列结束。
例如下面对5个进行排序,这个五个数分别为8 2 9 10 5。按选择排序方法,过程如下:
初始数据 :8 2 9 10 5
第一次排序:8 2 9 10 5
9 2 8 10 5
10 2 8 9 5
10 2 8 9 5
第二次排序:10 8 2 9 5
10 9 2 8 5
10 9 2 8 5
第三次排序:10 9 8 2 5
10 9 8 2 5
第四次排序:10 9 8 5 2
对于十个数,则排序要进行9次。源程序如下:
program ex5_2;
var a:array[1..10]of integer;
i,j,t:integer;
begin
writeln('Input 10 integers:');
for i:=1 to 10 do read(a[i]);{读入10个初始数据}
readln;
for i:=1 to 9 do{进行9次排序}
begin
for j:=i+1 to 10 do{将第i个数与其后所有数比较}
if a[i]<a[j] then {若有比a[i]大,则与之交换}
begin
t:=a[i];a[i]:=a[j];a[j]:=t;
end;
write(a[i]:5);
end;
end.
练习:
1.输入一串小写字母(以"."为结束标志),统计出每个字母在该字符串中出现的次数(若某字母不出现,则不要输出)。
例:
输入:aaaabbbccc.
输出:a:4
b:3
c:3
2.输入一个不大于32767的正整数N,将它转换成一个二进制数。
例如:
输入:100
输出: 1100100
3.输入一个由10个整数组成的序列,其中序列中任意连续三个整数都互不相同,求该序列中所有递增或递减子序列的个数。
例如:
输入:1 10 8 5 9 3 2 6 7 4
输出:6
对应的递增或递减子序列为:
1 10
10 8 5
5 9
9 3 2
2 6 7
7 4
一、多维数组的定义
当一维数组元素的类型也是一维数组时,便构成了二维数组。二维数组定义的一般格式:
array[下标类型1] of array[下标类型2] of 元素类型;
但我们一般这样定义二维数组:
array[下标类型1,下标类型2] of 元素类型;
说明:其中两个下标类型与一维数组定义一样,可以看成"下界1..上界1"和"下界2..上界2",给出二维数组中每个元素( 双下标变量)可以使用下标值的范围。of后面的元素类型就是基类型。
一般地,n维数组的格式为:
array[下标类型1,下标类型2,…,下标类型n] of 元素类型;
其中,下标类型的个数即数组的维数,且说明了每个下标的类型及取值范围。
二、多维数组元素的引用
多维数组的数组元素引用与一维数组元素引用类似,区别在于多维数组元素的引用必须给出多个下标。
引用的格式为:
<数组名>[下标1,下标2,…,下标n]
说明:显然,每个下标表达式的类型应与对应的下标类型一致,且取值不超出下标类型所指定的范围。
例如,设有说明:
type matrix=array[1..5,1..4]of integer;
var a:matrix;
则表示a是二维数组,共有5*4=20个元素,它们是:
a[1,1]a[1,2]a[1,3]a[1,4]
a[2,1]a[2,2]a[2,3]a[2,4]
a[3,1]a[3,2]a[3,3]a[3,4]
a[4,1]a[4,2]a[4,3]a[4,4]
a[5,1]a[5,2]a[5,3]a[5,4]
因此可以看成一个矩阵,a[4,2]即表示第4行、第2列的元素。由于计算机的存储器是一维的,要把二维数组的元素存放到存储器中,pascal是按行(第一个下标)的次序存放,即按a[1,1]a[1,2]a[1,3]a[1,4]a[2,1]…,a[5,4]的次序存放于存储器中某一组连续的存储单元之内。
对于整个二维数组的元素引用时,大多采用二重循环来实现。如:给如上说明的二维数组a进行赋值:a[i,j]=i*j。
for i:=1 to 5 do
for j:=1 to 4 do
a[i,j]:=i*j;
对二维数组的输入与输出也同样可用二重循环来实现:
for i:=1 to 5 do
begin
for j:=1 to 4 do
read(a[i,j]);
readln;
end;
for i:=1 to 5 do
begin
for j:=1 to 4 do
write(a[i,j]:5);
writeln;
end;
三、多维数组的应用示例
例1设有一程序:
program ex5_3;
const n=3;
type matrix=array[1..n,1..n]of integer;
var a:matrix;
i,j:1..n;
begin
for i:=1 to n do
begin
for j:=1 to n do
read(a[i,j]);
readln;
end;
for i:=1 to n do
begin
for j:=1 to n do
write(a[j,i]:5);
writeln;
end;
end.
且运行程序时的输入为:
2□1□3←┘
3□3□1←┘
1□2□1←┘
则程序的输出应是:
2□3□1
1□3□2
3□1□1
例2 输入4名学生数学、物理、英语、化学、pascal五门课的考试成绩,求出每名学生的平均分,打印出表格。
分析:用二维数组a存放所给数据,第一下标表示学生的学号, 第二个下标表示该学生某科成绩,如a[i,1]、a[i,2]、a[i,3]、a[i,4]、a[i,5]分别存放第i号学生数学、物理、英语、化学、pascal 五门课的考试成绩,由于要求每个学生的总分和平均分, 所以第二下标可多开两列,分别存放每个学生5门成绩和总分、平均分。
源程序如下:
program ex5_4;
var a:array[1..4,1..7]of real;
i,j:integer;
begin
fillchar(a,sizeof(a),0);
{函数fillchar用以将a中所有元素置为0}
writeln('Enter 4 students score');
for i:=1 to 4 do
begin
for j:=1 to 5 do {读入每个人5科成绩}
begin
read(a[i,j]);
{读每科成绩时同时统计总分}
a[i,6]:=a[i,6]+a[i,j];
end;
readln;
a[i,7]:=a[i,6]/5;{求平均分}
end;
{输出成绩表}
writeln( 'No. Mat. Phy. Eng. Che. Pas. Tot. Ave.');
for i:=1 to 4 do
begin
write(i:2,' ');
for j:=1 to 7 do
write(a[i,j]:9:2);
writeln;
end;
end.
四、数组类型的应用
例3 输入一串字符,字符个数不超过100,且以"."结束。判断它们是否构成回文。
分析:所谓回文指从左到右和从右到左读一串字符的值是一样的,如12321,ABCBA,AA等。先读入要判断的一串字符(放入数组letter中),并记住这串字符的长度,然后首尾字符比较,并不断向中间靠拢,就可以判断出是否为回文。
源程序如下:
program ex5_5;
var
letter : array[1..100]of char;
i,j : 0..100;
ch : char;
begin
{读入一个字符串以'.'号结束}
write('Input a string:');
i:=0;read(ch);
while ch<>'.' do
begin
i:=i+1;letter[i]:=ch;
read(ch)
end;
{判断它是否是回文}
j:=1;
while (j<i)and(letter[j]=letter[i])do
begin
i:=i-1;j:=j+1;
end;
if j>=i thenwriteln('Yes.')
else writeln('No.');
end.
例4 奇数阶魔阵
魔阵是用自然数1,2,3…,n2填n阶方阵的各个元素位置,使方阵的每行的元素之和、每列元素之和及主对角线元素之和均相等。奇数阶魔阵的一个算法是将自然数数列从方阵的中间一行最后一个位置排起,每次总是向右下角排(即Aij的下一个是Ai+1,j+1)。但若遇以下四种情形,则应修正排数法。
(1) 列排完(即j=n+1时),则转排第一列;
(2) 行排完(即i=n+1时),则转排第一行;
(3) 对An,n的下一个总是An,n-1;
(4) 若Aij已排进一个自然数,则排Ai-1,j-2。
例如3阶方阵,则按上述算法可排成:
4 3 8
9 5 1
2 7 6
有了以上的算法,解题主要思路可用伪代码描述如下:
1 in div 2+1,yn /*排数的初始位置*/
2 a[i,j]1;
3 for k:=2 to nn do
4 计算下一个排数位置(i,j);
5 if a[i,j]<>0 then
6 ii-1;
7 jj-2;
8 a[i,j]k;
9 endfor
对于计算下一个排数位置,按上述的四种情形进行,但我们应先处理第三处情况。算法描述如下:
1 if (i=n)and(j=n) then
2 jj-1; /*下一个位置为(n,n-1)*/;
3 else
4 ii mod n +1;
5 jj mod n +1;
6 endif;
源程序如下:
program ex5_7;
var
a : array[1..99,1..99]of integer;
i,j,k,n : integer;
begin
fillchar(a,sizeof(a),0);
write('n=');readln(n);
i:=n div 2+1;j:=n;
a[i,j]:=1;
for k:=2 to n*n do
begin
if (i=n)and(j=n) then
j:=j-1
else
begin
i:=i mod n +1;
j:=j mod n +1;
end;
if a[i,j]<>0 then
begin
i:=i-1;
j:=j-2;
end;
a[i,j]:=k;
end;
for i:=1 to n do
begin
for j:=1 to n do
write(a[i,j]:5);
writeln;
end;
end.
练习:
1、 输入N个同学的语、数、英三科成绩,计算他们的总分与平均分,并统计出每个同学的名次,最后以表格的形式输出。
2、 输出杨辉三角的前N行(N<10)。
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
一、字符、字符串类型的使用
(一)字符类型
字符类型为由一个字符组成的字符常量或字符变量 。
字符常量定义:
const
字符常量='字符'
字符变量定义:Ⅱ
Var
字符变量:char;
字符类型是一个有序类型, 字符的大小顺序按其ASCⅡ代码的大小而定。函数succ、pred、ord适用于字符类型。
例如:后继函数:succ('a')='b'
前继函数:pred('B')='A'
序号函数:ord('A')=65
例1 按字母表顺序和逆序每隔一个字母打印。即打印出:
a c e g I k m o q s u w y
z x r v t p n l j h f d b
程序如下:
program ex8_1;
var letter:char;
begin
for letter:='a' to 'z' do
if (ord(letter)-ord('a'))mod 2=0 thenwrite(letter:3);
writeln;
for letter:='z' downto 'a' do
if (ord(letter)-ord('z'))mod 2 =0 thenwrite(letter:3);
writeln;
end.
分析:程序中,我们利用了字符类型是顺序类型这一特性,直接将字符类型变量作为循环变量,使程序处理起来比较直观。
(二)字符串类型
字符串是由字符组成的有穷序列。
字符串类型定义:
type <字符串类型标识符>=string[n];
var
字符串变量: 字符串类型标识符;
其中:n是定义的字符串长度,必须是0~255之间的自然整数,第0号单元中存放串的实际长度,程序运行时由系统自动提供,第1~n号单元中存放串的字符。若将string[n]写成string,则默认n值为255。
例如:type
man=string[8];
line=string;
var
name:man;
screenline:line;
另一种字符类型的定义方式为把类型说明的变量定义合并在一起。
例如:VAR
name:STRING[8];
screenline:STRING;
Turbo Pascal中,一个字符串中的字符可以通过其对应的下标灵活使用。
例如:var
name:string;
begin
readln(nsme);
for i:=1 to ord(name[0])do
writeln(name[i]);
end.
语句writeln(name[i])输出name串中第i个字符。
例2 求输入英文句子单词的平均长度.
程序如下:
program ex8_2;
var
ch:string;
s,count,j:integer;
begin
write('The sentence is :');
readln(ch);
s:=0;
count:=0;
j:=0;
repeat
inc(j);
if not (ch[j] in [':',',',';','''','!','?','.','']) then inc(s);
if ch[j] in[' ','.','!','?'] then inc(count);
until (j=ord(ch[0])) or(ch[j] in ['.','!','?']);
if ch[j]<>'.' then writeln('It is not asentence.')
else writeln('Average length is ',s/count:10:4);
end.
分析:程序中,变量s用于存句子中英文字母的总数,变量count用于存放句子中单词的个数,ch[j]表示ch串中的第j个位置上的字符,ord(ch[0])为ch串的串长度。程序充分利用Turbo Pascal允许直接通过字符串下标得到串中的字符这一特点,使程序比较简捷。
二、字符串的操作
(一)字符串的运算和比较
由字符串的常量、变量和运算符组成的表达式称为字符串表达式。
字符串运算符包括:
1.+:连接运算符
例如:'Turbo '+'PASCAL'的结果是'TurboPASCAL'。
若连接的结果字符串长度超过255,则被截成255个字符。若连接后的字符串存放在定义的字符串变量中,当其长度超过定义的字符串长度时,超过部份字符串被截断。
例如:var
str1,str2,str3:string[8];
begin
str1:='Turbo ';
str2:='PASCAL';
str3:=str1+str2;
end.
则str3的值为:'Turbo PA'。
2.=、〈〉、〈、〈=、〉、〉=:关系运算符
两个字符串的比较规则为,从左到右按照ASCⅡ码值逐个比较,遇到ASCⅡ码不等时,规定ASCⅡ码值大的字符所在的字符串为大。
例如:'AB'〈'AC' 结果为真;
'12'〈'2' 结果为真;
'PASCAL '='PASCAL' 结果为假;
例3 对给定的10个国家名,按其字母的顺序输出。
程序如下:
program ex8_3;
var i,j,k:integer;
t:string[20];
cname:array[1..10] of string[20];
begin
for i:=1 to 10 do readln(cname[i]);
for i:=1 to 9 do
begin
k:=i;
for j:=i+1 to 10 do
if cname[k]>cname[j] then k:=j;
t:=cname[i];cname[i]:=cname[k];cname[k]:=t;
end;
for i:=1 to 10 do writeln(cname[i]);
end.
分析:程序中,当执行到if cname[k]>cname[j]时,自动将cname[k]串与cname[j]串中的每一个字符逐个比较,直至遇到不等而决定其大小。这种比较方式是计算机中字符串比较的一般方式。
三、字符串的函数和过程
Turbo Pascal提供了八个标准函数和标准过程,见下表,利用这些标准函数与标准过程,一些涉及到字符串的问题可以灵活解决。
| 函数和过程名 | 功 能 | 说 明 |
| copy(s,m,n) | 取s中第m个字符开始的n个字符 | 若m大于s的长度,则返回空串;否则,若m+n大于s的长度,则截断 |
| length(s) | 求s的动态的长度 | 返回值为整数 |
| pos(sub,s) | 在s中找子串sub | 返回值为sub在s中的位置,为byte型 |
| insert(sour,s,m) | 在s的第m个字符位置处插入子串sour | 若返回串超过255,则截断 |
| delete(s,m,n) | 删除s中第m个字符开始的n个字符串 | 若m大于s的长度,则不删除;否则,若m+n大于s的长度,则删除到结尾 |
| Str(x[:w[:d]],s) | 将整数或实数x转换成字符串s | w 和 d是整型表达式,意义同带字宽的write语句 |
| val(s,x,code) | 将字符串S 转换成整数或实数x |
|
| upcase(ch) | 将字母ch转换成大写字母 | 若ch不为小写字母,则不转换 |
例4 校对输入日期(以标准英语日期,月/日/年)的正确性,若输入正确则以年.月.日的方式输出。
程序如下:
program ex8_4;
const
max:array[1..12] of byte
=(31,29,31,30,31,30,31,31,30,31,30,31);
var
st:string;
p,w,y,m,d:integer;
procedure err;
begin
write('Input Error!');
readln;
halt;
end;
procedure init(var x:integer);
begin
p:=pos('/',st);
if (p=0) or (p=1) or (p>3) then err;
val(copy(st,1,p-1),x,w);
if w<>0 then err;
delete(st,1,p);
end;
begin
write('The Date is :');
readln(st);
init(m);
init(d);
val(st,y,w);
if not (length(st)<>4) or (w<>0) or(m>12) or (d>max[m]) then err;
if (m=2) and (d=29)
then if y mod 100=0
then begin
if y mod 400<>0 then err;
end
else if y mod 4<>0 then err;
write('Date : ',y,'.',m,'.',d);
readln;
end.
分析:此题的题意很简单,但在程序处理时还需考虑以下几方面的问题。
1.判定输入的月和日应是1位或2位的数字,程序中用了一个过程inst,利用串函数pos,求得分隔符/所在的位置而判定输入的月和日是否为1位或2位,利用标准过程val判定输入的月和日是否为数字;
2.判定月和日是否规定的日期范围及输入的年是否正确;
3.若输入的月是2月份,则还需考虑闰年的情况。
例5 对输入的一句子实现查找且置换的功能。
程序如下:
program ex8_5;
var
s1,s,o:string;
i:integer;
begin
write('The text:');
readln(s1);
write('Find:');readln(s);
write('Replace:');readln(o);
i:=pos(s,s1);
while i<>0 do begin
delete(s1,i,length(s));
insert(o,s1,i);
i:=pos(s,s1);
end;
writeln(s1);
readln;
end.
分析:程序中,输入要查找的字符串及要置换的字符串,充分用上了字符串处理的标准过程delete、insert及标准函数pos。
在前面几章中我们用到了整型、实型、布尔型、字符型的数据。以上数据类型是由pascal规定的标准数据类型,只要写integer,real,boolean,char, pascal 编译系统就能识别并按这些类型来处理。pascal还允许用户定义一些类型,这是其它一些语言所没有的,这就使得pascal使用灵活、功能丰富。
一、枚举类型
随着计算机的不断普及,程序不仅只用于数值计算,还更广泛地用于处理非数值的数据。例如,性别、月份、星期几、颜色、单位名、学历、职业等,都不是数值数据。
在其它程序设计语言中,一般用一个数值来代表某一状态,这种处理方法不直观,易读性差。如果能在程序中用自然语言中有相应含义的单词来代表某一状态,则程序就很容易阅读和理解。也就是说,事先考虑到某一变量可能取的值,尽量用自然语言中含义清楚的单词来表示它的每一个值,这种方法称为枚举方法,用这种方法定义的类型称枚举类型。
枚举类型是一种很有实用价值的数据类型,它是pascal一项重要创新。
(一)枚举类型的定义
枚举类型是一种自定义类型,要使用枚举类型当然也要先说明枚举类型。
枚举类型的一般格式:
(标识符1,标识符2,…,标识符n)
说明:①括号中的每一个标识符都称为枚举元素或枚举常量。
②定义枚举类型时列出的所有枚举元素构成了这种枚举类型的值域(取值范围),也就是说,该类型的变量所有可能的取值都列出了。
例如,下列类型定义是合法的:
type days=(sun,mon,tue,wed,thu,fri,sat);
colors=(red,yellow,blue,white,black,green);
而下列类型定义是错误的(因为枚举元素非标识符):
type colortype=('red','yellow','blue','white');
numbers=(1,3,5,7,9);
ty=(for,do,while);
(二)枚举类型变量
定义了枚举类型,就可以把某些变量说明成该类型。如:
var holiday,workday:day;
incolor:colors;
也可以把变量的说明与类型的定义合并在一起,如:
var holiday,workday:(sun,mon,tue,wed,thu,fri,sat);
incolor:(red,yellow,blue,white,black,green);
(三)枚举类型的性质
⒈枚举类型属于顺序类型
根据定义类型时各枚举元素的排列顺序确定它们的序号,第一个枚举元素的序号为0。例如:设有定义:
type days=(sun,mon,tue,wed,thu,fri,sat);
则:
ord(sun)=0,ord(mon)=1,ord(sat)=6;succ(sun)=mon,succ(mon)=tue,
succ(fri)=sat;pred(mon)=sun,pred(tue)=mon,pred(sat)=fri。
应注意的是:枚举类型中的第一个元素无前趋,最后一个元素无后继。
⒉对枚举类型只能进行赋值运算和关系运算
一旦定义了枚举类型及这种类型的变量,则在语句部分只能对枚举类型变量赋值,或进行关系运算,不能进行算术运算和逻辑运算。
在枚举元素比较时,实际上是对其序号的比较。当然,赋值或比较时,应注意类型一致。
例如,设程序有如下说明:
type days=(sun,mon,tue,wed,thu,fri,sat);
colors=(red,yellow,blue,white,black,green);
var color:colors;
weekday:days;
则下列比较或语句是合法的:
weekday:=mon;
if weekday=sun then write('rest');
weekday<>sun
而下面比较或语句是不合法的:
mon:=weekday;
mon:=1;
if weekday=sun or sat then write('rest');
sun>red
weekday<>color
⒊枚举变量的值只能用赋值语句来获得
也就是说,不能用read(或readln)读一个枚举型的值。同样,也不能用write(或writeln)输出一个枚举型的值。如write(red)是非法的,会发生编译错误。千万不要误认为,该语句的结果是输出"red"三个字符。
但对枚举数据的输入与输出可通过间接方式进行。输入时,一般可输入一个代码,通过程序进行转换,输出时,也只是打印出与枚举元素相对应的字符串。这在后面的例题中将有使用示例。
⒋同一个枚举元素不能出现在两个或两个以上的枚举类型定义中。
如:
type color1=(red,yellow,white);
color2=(blue,red,black);
是不允许的,因为red属于两个枚举类型。
(四)、枚举类型应用举例
例1 一周七天用sun,mon,tue,wed,thu,fri,sat表示, 要求利用枚举类型编程:当输入星期几的数字,能输出它的后一天是星期几(也用英文表示)。
源程序如下:
program ex6_1;
type week=(sun,mon,tue,wed,thu,fri,sat);
var
i : integer;
day,sucday : week;
begin
write('What date is it');readln(i);
case i of {根据输入i转换成枚举型}
1:day:=mon;
2:day:=tue;
3:day:=wed;
4:day:=thu;
5:day:=fri;
6:day:=sat;
7:day:=sun;
end;
{计算明天sucday}
if (day=sat) then sucday:=sun
else sucday:=succ(day);
{输出明天是星期几}
write('The next day is ');
case sucday of
sun:writeln('sunday');
mon:writeln('monday');
tue:writeln('tuesday');
wed:writeln('wednesay');
thu:writeln('thursday');
fri:writeln('friday');
sat:writeln('saturday');
end;
end.
评注:程序中变量day、sucday分别表示今天、明天。
二、子界类型
如果我们定义一个变量i为integer类型,那么i的值在微型机系统的pascal中,使用2字节的定义表示法,取值范围为-32768~32767。而事实上,每个程序中所用的变量的值都有一个确定的范围。
例如,人的年龄一般不超过150,一个班级的学生不超过100人,一年中的月数不超过12,一月中的天数不超过31,等等。
如果我们能在程序中对所用的变量的值域作具体规定的话,就便于检查出那些不合法的数据,这就能更好地保证程序运行的正确性。而且在一定程度上还会节省内存空间。
子界类型就很好解决如上问题。此外,在数组的定义中,常用到子界类型,以规定数组下标的范围,上一章有关数组知识中我们已用到。
(一)子界类型定义
子界类型的一般格式:
<常量1>..<常量2>
说明: ①其中常量1称为子界的下界,常量2称为子界的上界。
②下界和上界必须是同一顺序类型(该类型称为子界类型的基类型),且上界的序号必须大于下界的序号。例如,下列说明:
type age=0.5..150;
letter=0..'z';
let1='z'..'a';
都是错误的。
③可以直接在变量说明中定义子界类型。如:
type letter='a'..'d';
var ch1,ch2:letter;
可以合并成:
var ch1,ch2:'a'..'d';
当然,将类型定义和变量定义分开,则更为清晰。
(二)子界类型数据的运算规则
⒈凡可使用基类型的运算规则同样适用该类型的子界类型。
例如,可以使用整型变量的地方,也可以使用以整型为基类型的子界类型数据。
⒉对基类型的运算规则同样适用于该类型的子界类型。
例如,div,mod要求参加运算的数据为整, 因而也可以为整型的任何子界类型数据。
⒊基类型相同的不同子界类型数据可以进行混合运算。
例如:设有如下说明:
type a=1..100;
b=1.1000;
c=1..500;
var
x:a;
y:b;
t:c;
z:integer;
则下列语句也是合法的:
Z:=Sqr(x)+y+t;
下列语句:
t:=x+y+z;
当X+Y+Z的值在1~500范围内时是合法的,否则会出错。
(三)子界类型应用举例
例2 利用子界类型作为情况语句标号,编一个对数字,大小写字母和特殊字符进行判别的程序。
源程序如下:
program cas;
var c:char;
begin
readln(c);
case c of
'0'..'9':writeln('digits');
'A'..'Z':writeln('UPPER-CASELETTERS');
'a'..'z':writeln('lower-caseletters');
esle writeln('special charactors');
end;
end.
例3 使用子界型情况语句,当输入月、日、年(10 30 1986),输出30 Oct 1986。
源程序如下:
program ex6_3;
var month:1..12;
date:1..31;
year:1900..1999;
begin
write('Enter date(mm-dd-yy):');
readln(month,date,year);
write(date);
case month of
1:write('Jan':5);
2:write('Feb':5);
3:write('Mar':5);
4:write('Apr':5);
5:write('May':5);
6:write('Jun':5);
7:write('Jul':5);
8:write('Aug':5);
9:write('Sep':5);
10:write('Oct':5);
11:write('Nov':5);
12:write('Dec':5);
end;
writeln(year:7);
end.
枚举类型和子界类型均是顺序类型,在前面一章数组的定义时,实际上我们已经用到了子界类型,数组中的下标类型确切地讲可以是和枚举类型或子界类型,大多数情况下用子界类型。
如有如下说明:
type color=(red,yellow,blue,white,black);
var
a:array[color]of integer;
b:array[1..100]of color;
都是允许的。
三、集合类型
集合是由具有某些共同特征的元素构成的一个整体。在pascal中,一个集合是由具有同一有序类型的一组数据元素所组成,这一有序类型称为该集合的基类型。
(一)集合类型的定义和变量的说明
集合类型的一般形式为:
set of <基类型>;
说明: ①基类型可以是任意顺序类型, 而不能是实型或其它构造类型。同时,基类型的数据的序号不得超过255。例如下列说明是合法的:
type letters=set of 'A'..'Z';
numbers=set of 0..9;
s1=set of char;
ss=(sun,mon,tue,wed,thu,fri,sat);
s2=set of ss;
②与其它自定义类型一样, 可以将类型说明与变量说明合并在一起.如:
type numbers=set of 0..9;
var s:numbers;
与 var s:set of 0..9;等价。
(二)集合的值
集合的值是用"["和"]"括起来,中间为用逗号隔开的若干个集合的元素。如:
[] 空集
[1,2,3]
['a','e','i','o','u']
都是集合。
说明:
①集合的值放在一对方括号中,各元素之间用逗号隔开。
②在集合中可以没有任何元素,这样的集合称为空集。
③在集合中,如果元素的值是连续的,则可用子界型的表示方法表示。例如:
[1,2,3,4,5,7,8,9,10,15]
可以表示成:
[1..5,7..10,15]
④集合的值与方括号内元素出现的次序无关。例如,[1,5,8 ]和[5,1,8]的值相等。
⑤在集合中同一元素的重复出现对集合的值没有影响。例如,[1,8,5,1,8]与[1,5,8]的值相等。
⑥每个元素可用基类型所允许的表达式来表示。如[1,1+2,4]、[ch]、[succ(ch)]。
(三)集合的运算
⒈赋值运算
只能通过赋值语句给集合变量赋值,不能通过读语句赋值,也不能通过write(或writeln)语句直接输出集合变量的值。
⒉集合的并、交、差运算
可以对集合进行并、交、差三种运算,每种运算都只能有一个运算符、两个运算对象,所得结果仍为集合。三种运算符分别用"+"、"*"、"-"表示。注意它们与算术运算的区别。
⒊集合的关系运算
集合可以进行相等或不相等、包含或被包含的关系运算,还能测试一个元素是否在集合中。所用的运算符分别是:=、<>、>=、<=、in
它们都是二目运算,且前4个运算符的运算对象都是相容的集合类型,最后一个运算符的右边为集合,左边为与集合基类型相同的表达式。
例4 设有如下说明:
type weekday=(sun,mon,tue,wed,thu,fri,sat);
week=set of weekday;
subnum=set of 1..50;
写出下列表达式的值:
⑴[sun,sat]+[sun,tue,fri]
⑵[sun,fri]*[mon,tue]
⑶[wun,sat]*[sun..sat]
⑷[sun]-[mon,tue]
⑸[mon]-[mon,tue]
⑹[sun..sat]-[mon,sun,sat]
⑺[1,2,3,5]=[1,5,3,2]
⑻[1,2,3,4]<>[1..4]
⑼[1,2,3,5]>=[1..3]
⑽[1..5]<=[1..4]
⑾[1,2,3]<=[1..3]
⑿ 2 in[1..10]
答: 表达式的值分别是:
⑴ [sun,sat,tue,fri]
⑵ [ ]
⑶ [sun,sat]
⑷ [ ]
⑸ [ ]
⑹ [tue..fri]
⑺ TRUE
⑻ FALSE
⑼ TRUE
⑽ FALSE
⑾ TRUE
⑿ TRUE
例5 输入一系列字符,对其中的数字字符、字母字符和其它字符分别计数。输入'?'后结束。
源程序如下:
program ex10_2;
var id,il,io:integer;
ch:char;
letter:set of char;
digit:set of '0'..'9';
begin
letter=['a'..'z','A'..'Z'];
digit:=['0'..'9'];
id:=0;il:=0;io:=0;
repeat
read(ch);
if ch in letter
then il:=il+1
else if ch in digit
then id:=id+1
else io:=io+1;
until ch='?';
writeln('letter:',il,'digit:',id,'Other:',io);
end.
四、记录类型
在程序中对于组织和处理大批量的数据来说,数组是一种十分方便而又灵活的工具,但是数组在使用中有一个基本限制,这就是:一个数组中的所有元素都必须具有相同的类型。但在实际问题中可能会遇到另一类数据,它是由性质各不相同的成份组成的,即它的各个成
份可能具有不同的类型。例如,有关一个学生的数据包含下列项目:
学号 字符串类型
姓名 字符串类型
年龄 整型
性别 字符型
成绩 实型数组
Pascal给我们提供了一种叫做记录的结构类型。在一个记录中,可以包含不同类型的并且互相相关的一些数据。
(一)记录类型的定义
在pascal中,记录由一组称为"域"的分量组成,每个域可以具有不同的类型。
记录类型定义的一般形式:
record
<域名1>:<类型1>;
<域名2>:<类型2>;
: :
: :
<域名n>:<类型n>;
end;
说明:①域名也称域变量标识符, 应符合标识符的语法规则。在同一个记录中类型中,各个域不能取相同的名,但在不同的记录类型中,两个类型中的域名要以相同。
②记录类型的定义和记录变量可以合并为一个定义,如:
type date=record
year:1900..1999;
month:1..12;
day:1..31
end;
var x:date;
可以合并成:
var x: record
year:1900..1999;
month:1..12;
day:1..31
end;
③对记录的操作,除了可以进行整体赋值, 只能对记录的分量──域变量进行。
④域变量的表示方法如下:
记录变量名.域名
如前面定义的记录X,其3个分量分别为:x.year ,x.month ,x.day。
⑤域变量的使用和一般的变量一样, 即域变量是属于什么数据类型,便可以进行那种数据类型所允许的操作。
(二)记录的嵌套
当一个记录类型的某一个域类型也是记录类型的时候,我们说发生了记录的嵌套,看下面的例子:
例6 某人事登记表可用一个记录表示, 其中各项数据具有不同的类型,分别命名一个标识符。而其中的"出生年月日"又包括三项数据,还可以用一个嵌套在内层的记录表示。
具体定义如下:
type sexs=(male,female);
date=record
year:1900..1999;
month:1..12;
day:1..31;
end;
personal=record
name:string[15];
sex:sexs;
birthdate:date;
home:string[40];
end;
例7 设计一个函数比较两个dates日期类型记录变量的迟早。
设函数名、形参及函数类型定义为:
AearlyB(A,B:dates):boolean;
函数的形参为两个dates类型的值参数。当函数值为true时表示日期A早于日期B,否则日期A迟于日期B或等于日期B。显然不能对A、B两个记录变量直接进行比较,而要依具体的意义逐域处理。
源程序如下:
program ex6_7;
type dates=record
year:1900.1999;
month:1..12;
day:1..31
end;
var x,y:dates;
function AearlyB(A,B:dates):boolean;
var earln:boolean;
begin
early:=false;
if (A.year<B.year) then early:=true;
if (A.year=B.year)and(A.month<B.month)
then early:=true;
if(A.year=B.year)and(A.month=B.month)and(A.day<B.day)
then early:=true;
AearlyB:=early;
end;{of AearlyB}
begin
write('Input DATE X(mm-dd-yy):')readln(X.month,X.day,X.year);
write('Input DATEY(mm-dd-yy):')readln(Y.month,Y.day,Y.year);
if AearlyB(X,Y) then writeln(Date X early!') elsewriteln('Date X not early!');
end.
(三)开域语句
在程序中对记录进行处理时,经常要引用同一记录中不同的域,每次都按6.4.1节所述的格式引用,非常乏味。为此Pascal提供了一个with语句,可以提供引用域的简单形式。
开域语句一般形式:
with <记录变量名表> do
<语句>
功能: 在do后的语句中使用with后的记录的域时, 只要直接写出域名即可,即可以省略图10.2.2中的记录变量名和"."。
说明: ①一般在with后只使用一个记录变量名。如:
write('Input year:');
readln(x.year);
write('Input month:');
readln(x.month);
write('Input day:');
readln(x.day);
可以改写成:
with x do
begin
write('Input year:');readln(year);
write('Input month:');readln(month);
write('Input day:');readln(day);
end;
②设x,y是相同类型的记录变量,下列语句是非法的:
with x,y do...;
③with后接若干个记录名时,应是嵌套的关系。如有记录说明:
var x:record
i:integer;
y:record
j:0..5;
k:real;
end;
m:real
end;
可以使用:
with x do
begin
read(i);
with y do
read(j,k);
readln(m);
end;
或简写为:
with x,y do
readln(i,j,k,m);
例8 读入10个日期,再对每个日期输出第二天的日期。输入日期的格式是月、日、年,如9□30□1993,输出的格式为10/1/1993。
分析: 可用一个记录变量today表示日期。知道一个日期后要更新为第二天的日期,应判断输入的日期是否为当月的最后一天,或当年的最后一天。
源程序如下:
program ex6_8;
type date=record
month:1..12;
day:1..31;
year:1900..1999;
end;
var today:array[1..10]of date;
i:integer;
maxdays:28..31;
begin
for i:=1 to 10 do {输入10个日期}
with today[i] do
readln(month,day,year);
for i:=1 to 10 do
with today[i] do{求第i个日期中月份最后一天maxdays}
begin
case month of
1,3,5,7,8,10,12:maxdays:=31;
4,6,9,11 :maxdays:=30;
2 :if(year mod400=0) or( year mod 4=0)
and(year mod 100<>0)
then maxdays:=29
else maxdays:=28;
end;
if day=maxdays
then begin
day:=1;
if month=12
then begin
month:=1;year:=year+1;
end
else month:=month+1;
end
else day:=day+1;
writeln(month,'/',day,'/',year);
end;
end.
五、应用实例
例9 编制用筛法求1-n(n≤200)以内素数的程序。
分析: 由希腊著名数学家埃拉托色尼提出的所谓"筛法",步骤如下:
①将所有候选数放入筛中;
②找筛中最小数(必为素数)next,放入集合primes中;
③将next的所有倍数从筛中筛去;
④重复②~④直到筛空。
编程时,用集合变量sieve表示筛子,用集合primes存放所有素数。
源程序如下:
program ex10_3;
const n=200;
var sieve,primes:set of 2..n;
next,j:integer;
begin
sieve:=[2..n];{将所有候选数放入筛中}
primes:=[];{素数集合置空}
next:=2;
repeat
{找筛sieve中最小一个数}
while not(next in sieve) and(next<=n)do
next:=succ(next);
primes:=primes+[next];{将最小数放入素数集合中}
{将这个素数的倍数从筛中删去}
j:=next;
while j<=n do
begin
sieve:=sieve-[j];
j:=j+next;
end
until sieve=[];
j:=0;
for next:=2 to n do{打印出所有素数}
if next in primes then
begin
write(next:5);
j:=j+1;
if j mod 10=0 then writeln;
end;
writeln;
end.
练习
1.一家水果店出售四种水果,每公斤的价格是:苹果1.50元,桔子1.80元,香蕉2.0,菠萝1.60元。编一个程序,使售货员只要从键盘输入货物的代码及重量,计算机便能显示货物的名称、单价、重量及总价。
2.输入一个英语句子,以句号.为结束标志, 统计句子中元音字母出现的次数,把句子所有辅音字母组成一个集合,并把这些辅音字母打印出来。
3.编程序建立某班25人的数学课程成绩表,要求用数组类型和记录类型,其成绩表格式如下:
姓名 性别 平时成绩 期中考试 期终考试 总评成绩
张良 男 90 85 92 ?
王心 男 70 82 71 ?
……
李英 女 82 84 75 ?
其中总评成绩=平时成绩×20%+期中考试×30%+期终考试×%50。
4. 输入五个学生的出生日期(月/日/年)和当天的日期,然后用计算机计算出每个人到当天为止的年龄各是多少?(如某人1975年10月1日出生,今天是94年12月1日,则他的年龄应为19岁,而另一人的出生日期为76年12月30日,则他的年龄为17岁。)
前面我们曾经学习了程序设计中的三种基本控制结构(顺序、分支、循环)。用它们可以组成任何程序。但在应用中,还经常用到子程序结构。
通常,在程序设计中,我们会发现一些程序段在程序的不同地方反复出现,此时可以将这些程序段作为相对独立的整体,用一个标识符给它起一个名字,凡是程序中出现该程序段的地方,只要简单地写上其标识符即可。这样的程序段,我们称之为子程序。
子程序的使用不仅缩短了程序,节省了内存空间及减少了程序的编译时间,而且有利于结构化程序设计。因为一个复杂的问题总可将其分解成若干个子问题来解决,如果子问题依然很复杂,还可以将它继续分解,直到每个子问题都是一个具有独立任务的模块。这样编制的程序结构清晰,逻辑关系明确,无论是编写、阅读、调试还是修改,都会带来极大的好处。
在一个程序中可以只有主程序而没有子程序(本章以前都是如此),但不能没有主程序,也就是说不能单独执行子程序。pascal中子程序有两种形式:函数和过程。
一、函数
在此之前,我们曾经介绍并使用了pascal提供的各种标准函数,如ABS,SUCC等等,这些函数为我们编写程序提供了很大的方便。但这些函数只是常用的基本函数,编程时经常需要自定义一些函数。
(一)函数的说明
在pascal中,函数也遵循先说明后使用的规则,在程序中,函数的说明放在调用该函数的程序(主程序或其它子程序)的说明部分。函数的结构主程序的结构很相似。
函数定义的一般格式:
function <函数名>(<形式参数表>):<类型>; {函数首部}
说明:
①函数由首部与函数体两部分组成。
②函数首部以关键字function开头。
③函数名是用户自定义的标识符。
④函数的类型也就是函数值的类型,所求得的函数值通过函数名传回调用它的程序。可见,函数的作用一般是为了求得一个值。
⑤形式参数简称形参,形参即函数的自变量。自变量的初值来源于函数调用。在函数中,形参一般格式如下:
变量名表1:类型标识符1;变量名表2:类型标识符2;…;变量名表n:类型标识符n
可见形参表相当于变量说明,对函数自变量进行说明,但应特别注意:此处只能使用类型标识符,而不能直接使用类型。
⑥当缺省形参表(当然要同时省去一对括号)时,称为无参函数。
⑦函数体与程序体基本相似,由说明部分和执行部分组成。
⑧函数体中的说明部分用来对本函数使用的标号、常量、类型、变量、子程序加以说明,这些量只在本函数内有效。
⑨函数体的执行部分由begin开头,end结束,中间有若干用分号隔开的语句,只是end后应跟分号,不能像程序那样用句号"."。
⑩在函数体的执行部分,至少应该给函数名赋一次值,以使在函数执行结束后把函数值带回调用程序。
(二)函数的调用
我们可以在任何与函数值类型兼容的表达式中调用函数,或者说,函数调用只能出现在允许表达式出现的地方,或作为表达式的一个因子。
函数调用方式与标准函数的调用方式相同。
函数调用的一般格式:
<函数名>
或
<函数名>(实在参数表)
说明:①实在参数简称实参。实参的个数必须与函数说明中形参的个数一致,实参的类型与形参的类型应当一一对应。
②调用函数时,一般的,实参必须有确定的值。
③函数调用的步骤为:计算实参的值,"赋给"对应的形参;
(三)函数的应用举例
例1 求正整数A和B之间的完全数(A<B).
分析:所谓完全数是指它的小于该数本身的因子之和等于它本身,如6=1+2+3,6即是一个完全数。因此我们可定义一个布尔型函数perfect(x),若x是完全数,其值为TURE,否则为FALSE。整个程序算法如下:
1 for i:=A to B do
2 if perfect(i) then writeln(i);
源程序如下:
program ex7_1;
var
i,a,b : integer;
function perfect(x:integer):boolean;
var
k,sum : integer;
begin
{累加x所有小于本身的因数}
sum:=1;
for k:=2 to x div 2 do
if x mod k=0 then sum:=sum+k;
{判断x是否是完全数}
perfect:=x=sum; {将结果赋值给函数名}
end;{end of perfect}
begin{主程序开始}
write('Input a,b:');
repeat {输入0<a<b}
readln(a,b);
until (a>0)and(b>0)and(a<b);
writeln('List of all perfect numbers:');
{从a到b逐个判断,是完全数则打印出来
for i:=a to b do
if perfect(i) then writeln(i);
end.
自定义函数只是主程序的说明部分,若主程序中没有调用函数,则系统不会执行函数子程序。当主程序调用一次函数时,则将实在参数的值传给函数的形式参数,控制转向函数子程序去执行,子程序执行完毕后自动返回调用处。
二、过程
在pascal中,自定义过程与自定义函数一样,都需要先定义后调用。函数一般用于求值,而过程一般实现某些操作。
(一)过程的说明
过程说明的一般格式为:
procedure <过程名> (<形式参数表>); {过程首部}
说明: ①过程首部以关键字procedure开头。
②过程名是用户自定义的标识符,只用来标识一个过程,不能代表任何数据,因此不能说明"过程的类型"。
③形参表缺省(当然要同时省去一对括号)时,称为无参过程。
④形参表的一般格式形式如下:
[var] 变量名表:类型;…;[var] 变量名表:类型。
其中带var的称为变量形参,不带var的称为值形参。在函数中,形参一般都是值形参,很少用变量形参(但可以使用)。例如,下列形参表中:
(x,y:real;n:integer;var w:real;var k:integer;b:real)
x、y、n、b为值形参,而w、k为变量形参。
调用过程时,通过值形参给过程提供原始数据,通过变量形参将值带回调用程序。因此,可以说,值形参是过程的输入参数,变量形参是过程的输出参数。有关变参,这在后面内容具体叙述。
⑤过程体与程序、函数体类似。与函数体不同的是:函数体的执行部分至少有一个语句给函数名赋值,而过程体的执行部分不能给过程名赋值,因为过程名不能代表任何数据。
⑥过程体的说明部分可以定义只在本过程有效的标号、常量、类型、变量、子程序等。
(二)过程的调用
过程调用是通过一条独立的过程调用语句来实现的,它与函数调用完全不同。过程调用与调与标准过程(如write,read等)的方式相同。调用的一般格式为:
<过程名>
或
<过程名>(实在参数表)
说明: ①实参的个数、类型必须与形参一一对应。
②对应于值形参的实参可以是表达式,对应于变量形参的实参只能是变量。
③过程调用的步骤为:计算实参的值;将值或变量的"地址"传送给对应的形参;执行过程体;返回调用处。
过程与函数有下列主要区别:
①过程的首部与函数的首部不同;
②函数通常是为了求一个函数值,而过程可以得到若干个运算结果,也可用来完成一系列的数据处理,或用来完成与计算无关的各种操作;
③调用方式不同。函数的调用出现在表达式中,而过程调用是一个独立的语句。
(三)过程的应用举例
例2 输出以下一个图形:
*
**
***
****
*****
******
分析:我们前面学习可用的二重循环打印出上图形, 现我们设置一个过程打印出N个连续的"*"号。
源程序如下:
program ex7_2;
var i:integer;
procedure draw_a_line(n:integer); {该过程打印出连续n 个星号,并换行}
var j:integer;
begin
for j:=1 to n do
write('*');
writeln;
end;
begin
for i:=1 to 6 do
draw_a_line(i);{调用过程,第I行打印i个连续星号}
end.
三、过程、函数的数据传递
在程序调用子程序时,调用程序将数据传递给被调用的过程或函数,而当子程序运行结束后,结果又可以通过函数名、变参。当然也可以用全局变量等形式实现数据的传递。这一节我们,就来研究参数传递与局部变量、全局变量等问题。
(一)数值参数和变量参数
前面已经讲过,pascal子程序中形式参数有数值形参(简称值参)和变量形参(变参)两种。事实上,还有函数形参和过程形参两种,只是应用并不太多,我们不作深入地研究。
1、值形参
值参的一般格式如§7.1.1所示。应该强调的是:
①形参表中只能使用类型标识符,而不能使用类型。
②值形参和对应的实参必须一一对应,包括个数和类型。
③实参和值形参之间数据传递是单向的,只能由实参传送给形参,相当赋值运算。
④一个特殊情况是,当值形参是实型变量名时,对应的实参可以是整型表达式。
⑤值形参作为子程序的局部量,当控制返回程序后,值形参的存储单元释放。
2、变量形参
变量形参的一般格式如§7.2.1所示,必须在形参前加关键字var。
应该注意的是:
①与变量形参对应的实参只能是变量名,而不能是表达式。
②与变量形参对应的实参可以根据需要决定是否事先有值。
③变量形参与对应的实参的类型必须完全相同。
④对变量形参,运行时不另外开辟存储单元,而是与对应的实参使用相同的存储单元。也就是说,调用子程序时,是将实参的地址传送给对应的变量形参。
⑤当控制返回到调用程序后,变量形参的存储单元不释放,但变量形参本身无定义,即不得再使用。
⑥选用形式参时,到底是使用值形参还是变量形参,应慎重考虑。值形参需要另开辟存储空间,而变量形参会带来一些副作用。一般在函数中使用值形参,而在过程中才使用变量形参,但也有例外。
例3 写出下列两个程序的运行结果。
program ex1; programex2;
var a,b:integer; vara,b:integer;
procedure swap(x,y:integer); procedure swap(Var x,y:integer) ;
var t:integer; vart:integer;
begin begin
t:=x;x:=y;y:=t; t:=x;x:=y;y:=t;
end; end;
begin begin
a:=1;b:=2; a:=1;b:=2;
writeln(a:3,b:3); writeln(a:3,b:3);
swap(a,b); swap(a,b);
writeln(a:3,b:3); writeln(a:3,b:3);
end. end.
分析:这两个程序唯一的区别是ex1中将x,y作为值形参,而 ex2中将x,y作为变量形参,因此在ex2中对x,y的修改实际上是对调用该过程时与它们对应的变量a,b的修改,故最后,a,b的值为2,1。而ex1中调用swap过程时,只是将a,b的值传递给x,y,之后在过程中的操作与a,b无关。
答:ex1的运行结果为: ex2的运行结果为:
1 2 1 2
1 2 2 1
(二)全程变量、局部变量及它们的作用域
在主程序的说明部分和子程序的说明部分均可以说明变量,但它们的作用范围是特定的。
1、局部量及其作用域
在介绍过程和函数的说明时,我们曾指出,凡是在子程序内部作用的变量,应该在本子程序内加以说明。这种在子程序内部说明的变量称为局部变量。形式参数也只是在该子程序中有效,因此也属于局部变量。
一个变量的作用域是指在程序中能对此变量进行存取的程序范围。因此,局部变量的作用域就是其所在的子程序。实际上,局部变量只是当其所在的子程序被调用时才具有确定的存储单元,当控制从子程序返回到调用程序后,局部变量的存储单元就被释放,从而变得无定义。
事实上,在子程序内定义的标号、符号常量、类型、子程序也与局部变量具有相同的作用域。
2、全程量及其作用域
全程量是指在主程序的说明部分中说明的量。全程量的作用域分两种情况:
①当全程量和局部量不同名时,其作用域是整个程序范围(自定义起直到主程序结束)。
②当全程量和局部量同名时,全程量的作用域不包含局部量的作用域。
例4 写出下列程序的运行结果:
program ex7_4;
var x,y:integer;
procedure a;
var x:integer;
begin
x:=2;
writeln('#',x,'#');
writeln('#',y,'#');
end;{of a}
begin{main program}
x:=1;y:=2;
writeln('*',x,'*',y);
a;
writeln('***',x,'***',y);
end.
分析:程序中x,y是全局变量,但在过程a中也有变量x,故全程变量x的作用域为除过程a外的任何地方。而y的作用域包含了子程序a,即整个程序。
答:运行结果如下:
*1*2
#2#
#2#
***1***2
评注:变量作用域内对变量的操作都是对同一存储单元中的量进行的。
四、过程和函数的嵌套
Pascal语言中,使用过程和函数,能使程序设计简短,便于阅读,节省存贮单元和编译时间。程序往往设计成分层结构,由一个主程序和若干个过程及函数组成。在过程或函数中,还可以说明另一些过程或函数,即过程或函数可以分层嵌套。在同一层中亦可说明几个并列的过程或函数。例如:
上例过程的分层嵌套关系如下:0层主程序sample内并列两个1层过程P1a和P1b。过程P1a又嵌套两个2层过程p2a和p2b,2层的第二过程p2b又嵌套过程p3,p3就是第3层。其中p1b,p2a和p3不再嵌套别的过程,称为基本过程。这种分层结构的程序设计,特别要注意局部变量的使用范围和过程调用的要求。
在主程序sample中定义的变量,可以在所有的过程中使用,主程序可调用p1a和p1b两个过程。过程p1a中定义的变量,只能在p2a,p2b和p3中使用。它能调用p2a,p2b两个过程,而不能调用p3和p1b。在过程p1b中定义的变量,只能在p1b中使用,它只能调用过程p1a。过程p2a不能调用任何过程。过程p2b可以调用并列过程p2a和p3,而过程p3可以调用p2a过程。
过程调用是有条件的,过程定义在先,调用在后。同一层过程,后说明的过程可以调用先说明的过程。如果要调用在它后面定义的过程(或函数),可使用<向前引用>FORWARD这个扩充标识符。 要注意的是<向前引用>过程(或函数)首部中形式参数表写一次即可, 不必重复。如:
procedure extend(var a,b:integer);
forward;
表示过程extend<向前引用>。因此,过程extend 的说明部分只须如下书写:
procedure extend;
<说明部分>
begin
:
end;
五、子程序(模块化)结构的程序设计
例5 对6到60的偶数验证哥德巴赫猜想:不小于6的偶数可分解成两个素数之和。
分析:用布尔型函数prime(x)判断x是否是素数,若是, 函数值为真,否则,函数值为假。算法如下所示。
1. t:=6
2. while t≤60 do
3. t11;
4. repeat
5. t11+2; /* 找下一个素数a */
6. until prime(t1)andprime(t-t1); /*直到a,b都是素数*/
7.writeln(i,'=',t1,'+',t-t1);
8. tt+2;
9. endwhile
源程序如下:
program ex9_7;
var t,t1:integer;
function prime(x:integer):boolean;
var i:integer;
begin
if x=1
then prime:=false
else if x=2
then prime:=true
else begin
prime:=true;
i:=2;
while (i<=round(sqrt(x)))and(x modi<>0) do
i:=i+1;
if i<=round(sqrt(x)) thenprime:=false;
end;
end;{of prime}
begin
t:=6;
while t<=60 do
begin
t1:=1;
repeat
t1:=t1+2;
until prime(t1) and prime(t-t1);
writeln(t,'=',t1,'+',t-t1);
t:=t+2;
end;
end.
例6 编写一个给一个分数约分的程序。
源程序如下:
program ex7_6; ┌──变量参数
var a,b:integer; ↓
procedure common(var x,y:integer);
var i,j,k:integer;
begin
{求x,y的最大公约数}
i:=x;j:=y;
repeat
k:=i mod j;
i:=j;j:=k;
until k=0;
{对x,y进行约分}
x:=x div i;y:=y div i;
end;
begin
write('Input a,b=');readln(a,b);
common(a,b);
writeln(a,b:5);
end.
如输入:
Input a,b=12 8
则输出:
3 2
练习
1. 输入5个正整数求它们的最大公约数。(提示:可用一个数组将5个数存放起来,然后求第一个数和第二个数的公约数,再求第三个数与前两个数公约数的公约数,这样求得前三个整数最大公约数……如此类推可求出5个整数的最大公约数)
2. 给一维数组输入任意6个整数,假设为:
7 4 8 9 1 5
请建立一个具有以下内容的方阵:
7 4 8 9 1 5
4 8 9 1 5 7
8 9 1 5 7 4
9 1 5 7 4 8
1 5 7 4 8 9
5 7 4 8 9 1
(请用子程序编写)。
3. 求两个正整数的最小公倍数。
4. 输入一个任意位的正整数,将其反向输出。
5. 有五位同学,其各科成绩如下:
学号 数学 语文 英语 总分 名次
1 108 97 90
2 98 88 100
3 100 43 89
4 84 63 50
5 97 87 100
(1)编写一个过程enter,输入每个学生成绩并计算各人的总分。
(2)编写过程minci,用以排出每个人的名次。
(3)按学号顺序输出。
前面介绍的各种简单类型的数据和构造类型的数据属于静态数据。在程序中,这些类型
的变量一经说明,就在内存中占有固定的存储单元,直到该程序结束。
程序设计中,使用静态数据结构可以解决不少实际问题,但也有不便之处。如建立一个
大小未定的姓名表,随时要在姓名表中插入或删除一个或几个数据。而用新的数据类型──
指针类型。通过指针变量,可以在程序的执行过程中动态地建立变量,它的个数不再受限制,
可方便地高效地增加或删除若干数据。
一、指针的定义及操作
(一)指针类型和指针变量
在pascal中,指针变量(也称动态变量)存放某个存储单元的地址;也就是说, 指针变量
指示某个存储单元。
指针类型的格式为:^基类型
说明: ①一个指针只能指示某一种类型数据的存储单元,这种数据类型就是指针的基类
型。基类型可以是除指针、文件外的所有类型。例如,下列说明:
type pointer=^Integer;
var p1,p2:pointer;
定义了两个指针变量p1和p2,这两个指针可以指示一个整型存储单元(即p1、p2 中存放的是某存储单元的地址,而该存储单元恰好能存放一个整型数据)。
②和其它类型变量一样,也可以在var区直接定义指针型变量。
例如:var a:^real; b:^boolean;
又如:type person=record
name:string[20];
sex:(male,female);
age:1..100
end;
var pts:^person;
③pascal规定所有类型都必须先定义后使用,但只有在定义指针类型时可以例外,如下
列定义是合法的:
type pointer=^rec;
rec=record
a:integer;
b:char
end;
(二)开辟和释放动态存储单元
1、开辟动态存储单元
在pascal中,指针变量的值一般是通过系统分配的,开辟一个动态存储单元必须调用标
准过程new。
new过程的调用的一般格式:
New(指针变量)
功能:开辟一个存储单元,此单元能存放的数据的类型正好是指针的基类型,并把此存
储单元的地址赋给指针变量。
说明:①这实际上是给指针变量赋初值的基本方法。例如,设有说明:var p:^Integer;
这只定义了P是一个指示整型存储单元的指针变量,但这个单元尚未开辟,或者说P中尚未有值(某存储单元的首地址)。当程序中执行了语句new(p)才给p赋值,即在内存中开辟(分配)一个整型变量存储单元,并把此单元的地址放在变量p中。示意如下图:
(a)编译时给 (b)执行New(p)后 (c)(b)的简略表示
p分配空间 生成新单元
?表示值不定 新单元的地址为XXXX
内存单元示意图
②一个指针变量只能存放一个地址。如再一次执行New(p)语句,将在内存中开辟另外一个新的整型变量存储单元,并把此新单元的地址放在p中,从而丢失了原存储单元的地址。
③当不再使用p当前所指的存储单元时,可以通过标准过程Dispose释放该存储单元。
⒉释放动态存储单元
dispose语句的一般格式:dispose(指针变量)
功能:释放指针所指向的存储单元,使指针变量的值无定义。
(三)动态存储单元的引用
在给一个指针变量赋以某存储单元的地址后,就可以使用这个存储单元。
引用动态存储单元一般格式:<指针变量>^
说明:①在用New过程给指针变量开辟了一个它所指向的存储单元后,要使用此存储单元的唯一方法是利用该指针。
②对动态存储单元所能进行的操作是该类型(指针的基类型)所允许的全部操作。
例1 设有下列说明:
var p:^integer; i:integer;
画出执行下列操作后的内存示意图:
New(p); P^:=4;i:=p^;
解: 如下图所示。
(a)编译时 (b)执行New语句 (c)执行P^:=4 (d)执行i:=P^
分配存储
单元
内存单元示意图
(四)对指针变量的操作
前已述及,对指针所指向的变量(如P^)可以进行指针的基类型所允许的 全部操作。
对指针变量本身,除可用New、Dispose过程外,尚允许下列操作:
⒈具有同一基类型的指针变量之间相互赋值
例2 设有下列说明与程序段:
var p1,p2,p3:^integer;
begin
New(P1) ; New(P2); New(P3);
P1:=P2; P2:=P3;
end;
2、可以给指针变量赋nil值
nil是PASCAL的关键字,它表示指针的值为"空"。例如,执行:
p1:=ni1后,p1的值是有定义的,但p1不指向任何存储单元。
3、可以对指针变量进行相等或不相等的比较运算
在实际应用中,通常可以在指针变量之间,或指针变量与nil之间进行相等(=)或不相等(<>=的比较,比较的结果为布尔量。
例3 输入两个整数,按从小到大打印出来。
分析:不用指针类型可以很方便地编程,但为了示例指针的用法,我们利用指针类型。定义一个过程swap用以交换两个指针的值。
源程序如下:
Type pointer=^integer;
var p1,p2:pointer;
procedure swap(var q1,q2:pointer);
var q:pointer;
begin
q:=q1;
q1:=q2;
q2:=q;
end;
begin
new(p1);new(p2);
write('Input 2 data:');readln(pq^,p2^);
if p1^>p2^ then swap(p1,p2);
writeln('Output 2 data:',p1^:4,p2^:4);
end.
二、链表结构
设有一批整数(12,56,45,86,77,……,),如何存放呢? 当然我们可以选择以前学过的数组类型。但是,在使用数组前必须确定数组元素的个数。如果把数组定义得大了,就会有大量空闲存储单元,定义得小了,又会在运行中发生下标越界的错误,这是静态存储分配的局限性。
利用本章介绍的指针类型可以构造一个简单而实用的动态存储分配结构――链表结构。
下图是一个简单链表结构示意图:
其中:①每个框表示链表的一个元素,称为结点。
②框的顶部表示了该存储单元的地址(当然,这里的地址是假想的)。
③每个结点包含两个域:一个域存放整数,称为数据域,另一个域存放下一个结点(称为该结点的后继结点,相应地,该结点为后继结点的前趋结点)的地址。
④链表的第一个结点称为表头,最后一个结点表尾,称为指针域;
⑤指向表头的指针head称为头指针(当head为nil时,称为空链表),在这个指针变量中存放了表头的地址。
⑥在表尾结点中,由指针域不指向任何结点,一般放入nil。
(一)链表的基本结构
由上图可以看出:
①链表中的每个结点至少应该包含两个域;一是数据域,一是指针域。因此,每个结点都是一个记录类型,指针的基类型也正是这个记录类型。因此,head可以这样定义:
type pointer=^ rec;
rec=record
data:integer;
next:pointer;
end;
var head:pointer;
②相邻结点的地址不一定是连续的。整个链表是通过指针来顺序访问的,一旦失去了一个指针值,后面的元素将全部丢失。
③与数组结构相比,使用链表结构时;可根据需要采用适当的操作步骤使链表加长或缩 短,而使存储分配具有一定的灵活性。这是链表结构的优点。
④与数组结构相比,数组元素的引用比较简单,直接用"数组名[下标]"即可,因为数组元素占用连续的存储单元,而引用链表元素的操作却比较复杂。
(二)单向链表的基本操作
上图所示的链表称为单向链表。下面我们通过一些例题来说明对单向链表的基本操作,并假设类型说明如前所述。
例6 编写一个过程,将读入的一串整数存入链表,并统计整数的个数。
分析:过程的输入为一串整数,这在执行部分用读语句完成。过程的输出有两个:一是链表的头指针,一是整数的个数,这两个输出可以用变量形参来实现。
由于不知道整数的个数,我们用一个特殊的9999作为结束标记。
过程如下:
procedure creat(var h:pointer;var n:integer);
var p,q:pointer;x:integer;
begin
n:=0;h:=nil; read(x);
while x<>9999 do
begin
New(p);
n:=n+1;p^.data:=x;
if n=1 then h:=p
else q^.next:=p;
q:=p;read(x)
end;
if h<>nil then q^.next:=nil;
Dispose(p);
end;
例7 编一过程打印链表head中的所有整数,5个一行。
分析:设置一个工作指针P,从头结点顺次移到尾结点,每移一次打印一个数据。
过程如下:
procedure print(head:pointer);
var p:pointer; n:integer;
begin
n:=0;p:=head;
while p<>nil do
begin
write(p^.data:8);n:=n+1;
if n mod 5=0 then writeln;
p:=p^.next;
end;
writeln;
end;
(三)链表结点的插入与删除
链表由于使用指针来连接,因而提供了更多了灵活性,可以插入删除任何一个成分。
设有如下定义:
type pointer=^rec;
rec=record
data:integer;
next:pointer
end;
var head:pointer;
⒈结点的插入
如下图所示,要在P结点和Q结点之间插入一个结点m,其操作如下:
只要作如下操作即可:
New(m);
read(m^.data);
m^.next:=q;
p^.next:=m;
例8 设链表head中的数据是按从小到大顺序存放的,在链表中插入一个数,使链表仍有序。
分析:显然,应分两步:查找、插入。设po指向要插入的结点,若仅知道po应插在p之前(作为p的前趋结点)是无法插入的,应同时知道p的前趋结点地址q。
当然,如果插在链表原头结点这前或原链表为空表或插在原尾结点之后,则插入时又必须作特殊处理。
过程如下:
procedure inserting(var head:pointer;x:integer);
var po,p,q:pointer;
begin
new(po);po^.data:=x;
p:=head;
if head=nil{原表为空表}
then begin
head:=po;po^.next:=nil;
end
else begin
while (p^.data<x)and(p^.next<>nil)do
begin
q:=p;p:=p^.next
end;
if p^.data>=x{不是插在原尾结点之后}
then begin
if head=p then head:=po
else q^.next:=po;
po^.next:=p
end
else begin
po^.next:=po;
po^.next:=nil
end;
end;
end;
⒉结点的删除
如下图所示,要在删除结点P的操作如下:
要删除结点P,则只要将其前趋结点的指针域指向P 的后继结点即可。
q^.next:=p^.next;
dispose(p);
例9 将链表head中值为X的第一个结点删除
分析: 有三种情况存在:头结点的值为X; 除头结点外的某个结点值为X;无值为X的结点。为将前两种情况统一起来,我们在头结点之前添加一个值不为X的哨兵结点。
算法分两步:查找、删除。
过程如下:
procedure deleteing(var head:pointer;x:integer);
var p,q:pointer;
begin
New(p);p^.data:=x-1;p^.next:=head;
head:=p;{以上为添加哨兵结点}
while(x<>p^.data)and(p^.next<>nil)do
begin
q:=p;
p:=p^.next
end;
if x=p^.data{存在值为X的结点}
then q^.next:=p^.next
else writeln('NOt found!');
head:=head^.next{删除哨兵}
end;
(四)环形链表结构
在单向链表中,表尾结点的指针为空。如果让表尾结点的指针域指向表头结点,则称为单向环形链表,简称单链环。如图所示。
单链环示意图
(五)双向链表结构
单链表中,每个结点只有一个指向其后继结点的指针域。如果每个结点不仅有一个指向其后继结点的指针域,还有一个指向其前趋的指针域,则这种链表称为双向链表。如图所示。
双向链表示意图
可用如下定义一个数据域为整型的双向链表:
type pointer=^node;
node=record
prev:pointer;
data:integer;
next:pointer;
end;
对双向链表的插入、删除特别方便。与单向链环相似,我们还可定义双向链环。
三、综合例析
例10 读入一串以"#"为结束标志的字符,统计每个字符出现的次数。
分析:设置一个链表存放,每读入一个字符,就从链表的头结点向后扫描链表,如果在链表中此字符已存在,则其频率加1,否则将该字符的结点作为链表的新头结点,相应频率为1。
源程序如下:
program ex11_10;
type ref=^letters;
letters=record
key:char;
count:integer;
next:ref;
end;
var k:char;
sentinel,head:ref;
procedure search(x:char);
var w:ref;
begin
w:=head;
sentinel^.key:=x;
while w^.key<>x do w:=w^.next;
if w<>sentinel
then w^.count:=w^.count+1
else begin
w:=head;new(head);
with head^ do
begin
key:=x;count:=1;next:=w;
end
end;
end;{of search}
procedure printlist(w:ref);
begin
while w<>sentinel do
begin
writeln(w^.key:2,w^.count:10);
w:=w^.next;
end;
end;{of printlist}
begin{main program}
new(sentine);
with sentinel^ do
begin
key:='#';count:=0;next:=nil;
end;
head:=sentinel;
read(k);
while k<>'#' do
begin
search(k);read(k);
end;
printlist(head);
end.
例11 用链表重写筛法求2~100之间所有素数程序。
源程序如下:
program ex11_12;
uses crt;
type link=^code;
code=record
key:integer;
next:link;
end;
var head:link;
procedure printlist(h:link);{打印链表h}
var p:link;
begin
p:=h;
while p<>nil do
begin
write(p^.key,'-->');
p:=p^.next;
end;
end;
procedure buildlink;{建立链表}
var p,q:link;
i:integer;
begin
new(head);
head^.key:=2;
p:=head;
for i:=3 to 100 do
begin
new(q);
q^.key:=i;
q^.next:=nil;
p^.next:=q;
p:=q;
end;
end;
procedure prime;{筛法将找到的素数的倍数从链表中删除}
var h,p,q:link;
begin
h:=head;
while h<>nil do
begin
p:=h;q:=p^.next;
while q<>nil do
if (q^.key mod h^.key=0) then
begin
p^.next:=q^.next;
dispose(q);
q:=p^.next;
end
else begin
p:=q;
q:=q^.next;
end;
h:=h^.next;
end;
end;
begin{main program}
clrscr;
buildlink;
printlist(head);
writeln;
prime;
printlist(head);
end.
练习
1、围绕着山顶有10个洞,一只兔子和一只狐狸各住一个洞,狐狸总想吃掉兔子。一天兔子对狐狸说,你想吃我有一个条件,你先把洞编号1到10。你从第10号洞出发,先到第1号洞找我,第二次隔一个洞找我,第三次隔两个洞找我,以后依次类推,次数不限。若能找到我,你就可以饱餐一顿,在没找到我之前不能停止。狐狸一想只有10个洞,寻找的次数又不限,哪有找不到的道理,就答应了条件。结果就是没找着。
利用单链环编程,假定狐狸找了1000次,兔子躲在哪个洞里才安全。
2、某医院病房的订位管理中, 将病人的记录按姓名的字母顺序排成一个链表。试编写程序,从键盘上输入下列字母,就可对病员记录进行管理:
(1)i───新病人入院(插入一个病员记录)。
(2)d───病人出院(删除一个病员记录,并显示该记录)。
(3)s───查询某病员记录(显示该记录或"未找到")。
(4)q───在屏幕上列出所有的病员记录并结束程序。
3、编写一个简单的大学生新生入校登记表处理程序。
在DOS操作中,我们所谈及的文件称之为外部文件。外部文件是存储在外部设备上, 如:外存储器上,可由计算机操作系统进行管理,如用dir、type等命令直接对文件进行操作。
Pascal所谈及的文件,称之为内部文件。内部文件的特点是文件的实体(实际文件)也是存储在外存储器上,成为外部文件的一分子,但在使用时必须在程序内部以一定的语句与实际文件联系起来,建立一一对应的关系,用内部文件的逻辑名对实际文件进行操作。内部文件的逻辑名必须符合PASCAL语言标识符的取名规则。
Pascal中的文件主要用于存放大量的数据。如:成绩管理,原始数据很多,使用文件先将其存入磁盘,通过程序读出文件中的数据再进行处理,比不使用文件要来得方便、有效。
Pascal中的一个文件定义为同一类型的元素组成的线性序列。文件中的各个元素按一定顺序排列,可以从头至尾访问每一个元素,从定义上看,文件与数组相似,但它们之间有着明显不同的特征,主要表现在:
(1)文件的每一个元素顺序存贮于外部文件设备上(如磁盘上)。因此文件可以在程序进行前由Pascal程序或用文字编辑软件,如edit、ws、Turbo Pascal的edit命令等产生,或在运行过程中由程序产生,且运行完后,依然存贮在外部设备上。
(2)在系统内部,通过文件指针来管理对文件的访问。文件指针是一个保存程序在文件中位置踪迹的计算器,在一固定时刻,程序仅能对文件中的一个元素进行读或写的操作,在向文件写入一个元素或从文件读取一个元素后,相应的文件指针就前进到下一元素位置。而数组是按下标访问。
(3)在文件类型定义中无需规定文件的长度即元素的个数,就是说元素的数据可动态改变,一个文件可以非常之大,包含许许多多元素,也可以没有任何元素,即为一个空文件。而数组的元素个数则是确定的。
使用文件大致有以下几个步骤;
(1)说明文件类型,定义文件标识符;
(2)建立内部文件与外部文件的联系;
(3)打开文件;
(4)对文件进行操作;
(5)关闭文件。
Turbo Pascal将文件分为三类:文本文件(顺序)、有类型文件(顺序或随机)和无类型文件(顺序或随机)。下面将介绍这些文件及其操作。
一、文本文件
文本文件又称为正文文件或行文文件,可供人们直接阅读,是人机通信的基本数据形式之一。文本文件可用文字编辑程序(如DOS的edit或TurboPascal的编辑命令edit)直接建立、阅读和修改, 也可以由PASCAL程序在运行过程中建立。
1、文本文件的定义:
文本文件的类型为TEXT,它是由ASCII字符组成的,是Pascal提供的标准文件之一。标准文件 TEXT已由Pascal说明如下:
TYPE TEXT=FILE OF CHAR;
因此,TEXT同标准类型INTEGER、READ等一样可以直接用于变量说明之中,无需再由用户说明。 例如:
VAR F1,F2:TEXT;
这里定义了两个文本文件变量F1和F2。
2、文本文件的建立
文本文件的建立有两种方法:
(1)直接用Turbo Pascal的Edit建立原始数据文件。
例1 将下表中的数据存入名为A.dat的文件中。
3 4
29 30 50 60
80 90 70 75
60 50 70 45
操作步骤:
①进入Turbo Pascal的编辑状态;
②输入数据;
③存盘,文件名取A.dat。
此时,已将数据存入文本文件A.dat中。文本文件也可用DOS中的Edit等软件建立。
(2)用程序的方式建立中间数据或结果数据文件。
用程序的方式建立文件操作步骤为:
①定义文本文件变量;
②把一外部文件名赋于文本文件变量,使该文本文件与一相应外部文件相关联;
命令格式:ASSIGN(f,name)
f为定义的文本文件变量
name为实际文件文件名
如:ASSIGN(F1,`FILEIN.DAT`)
或:ASSIGN(F1,`PAS\FILEIN.RES`)
这样在程序中对文本文件变量F1的操作,也就是对外部实际文件`FILEIN.DAT`或`FILEIN.RES`的操作。上例中文件`FILEIN.DAT`是存贮在当前目录中,而文件`FILEIN.RES`则是存贮在PAS子目录中。
③打开文本文件,准备写;
命令格式1:REWRITE(f)
功能:创建并打开新文件准备写,若已有同名文件则删除再创建
命令格式2:APPEND(f)
功能:打开已存在的文件并追加
④对文件进行写操作;
命令格式:WRITE(f,<项目名>)
或:WRITELN(f,<项目名>)
功能:将项目内容写入文件f中
⑤文件操作完毕后,关闭文件。
命令格式:CLOSE(f)
例2 从键盘上读入表12.1的数据,用程序写入名为B.dat的文件中。
3、读取文本文件
文本文件内容读出操作步骤:
①定义文本文件变量;
②用ASSIGN(f,name)命令,将内部文件f与实际文件name联系起来;
③打开文本文件,准备读;
命令格式:READ(f,<变量名表>) READLN(f,<变量名表>)
功能:读文件f中指针指向的数据于变量中
文本文件提供了另外两个命令,在文本的操作中很有用处,它们是:
EOLN(f):回送行结束符
EOF(f):回送文件结束符
⑤文件操作完毕,用CLOSE(f)命令关闭文件。
例3 读出例12.1建立的文本文件,并输出。
由于文本文件是以ASCII码的方式存储,故查看文本文件的内容是极为方便,在DOS状态可使用 DOS中TYPE等命令进行查看,在Turbo Pascal中可以象取程序一样取出文件进行查看。
4、文本文件的特点
(1)行结构
文本文件由若干行组成,行与行之间用行结束标记隔开,文件末尾有一个文件结束标记。由于各行长度可能不同,所以无法计算出给定行在文本文件中的确定位置,从而只能顺序地处理文本文件,而且不能对一文本文件同时进行输入和输出。
(2)自动转换功能
文本文件的每一个元素均为字符型,但在将文件元素读入到一个变量(整型,实型或字符串型)中时,Pascal会自动将其转换为与变量相同的数据类型。与此相反在将一个变量写入文本文件时,也会自动转移为字符型。
例4 某学习小组有10人,参加某次测验,考核6门功课, 统计每人的总分及各门的平均分,将原始数据及结果数据放入文本文件中。
分析
(1)利用Turbo Pascal的EDIT建立原始数据文件TESTIN.DAT存贮在磁盘中,其内容如下:
10 6
1 78 89 67 90 98 67
2 90 93 86 84 86 93
3 93 85 78 89 78 98
4 67 89 76 67 98 74
5 83 75 92 78 89 74
6 76 57 89 84 73 71
7 81 93 74 76 78 86
8 68 83 91 83 78 89
9 63 71 83 94 78 95
10 78 99 90 80 86 70
(2)程序读入原始数据文件,求每人的总分及各门的平均分;
(3)建立结果数据文件,文件名为TEXTIN.RES.
程序:
例5 读入一个行长不定的文本文件。排版,建立一个行长固定为60个字符的文件, 排版要求:(1)当行末不是一个完整单词时,行最后一个字符位用'-'代替, 表示与下一行行头组成完整的单词;(2)第一行行头为两个空格,其余各行行头均不含有空格。
分析
(1)建立原始数据文件。
(2)程序边读入原始数据文件内容,边排版。
(3)每排完一行行长为60字符,并符合题中排版条件,写入目标文件中。
设原始数据TEXTCOPY.DAT文件内容如下:
Pavel was arrested.
That dat Mother did not light the stove.
Evening came and a cold wind was blowing.
There was a knock at the window.
Then another.
Mother was used to such knocks,but this time she gavea little start of joy.
Throwing a shawl over her shoulders,she opened thedoor.
程序:
对TEXTCOPY.DAT文本文件运行程序得到排版结果文件TEXTCOPY.RES内容如下:
Pavel was arrested.That dat Mother did not lightthe stov-
evening came and a cold wind was blowing.There was aknock
at the window.Then another.Mother was used to suchknocks,b-
ut this time she gave a little start of joy.Throwinga shawl
over her shoulders,she opened the door.
二、有类型文件
文本文件的元素均为字型符。若要在文件中存贮混合型数据,必须使用有类型文件。
1、有类型文件的定义
有类型文件中的元素可以是混合型的,并以二进制格式存贮,因此有类型文件(除了字符类型文件,因为它实质上是文本文件)不象文本文件那样可以用编辑软件等进行阅读和处理。
有类型文件的类型说明的格式为:
类型标识符=File of 基类型;
其中基类型可以是除了文件类型外的任何类型。例如:
FILE1=FILE OF INTEGER;
FILE2=FILE OF ARRAY[1--10] OF STRING;
FILE3=FILE OF SET OF CHAR;
FILE4=FILE OF REAL;
FILE5=FILE OF RECORD;
NAME:STRING;
COURSE:ARRAY[1--10] OF READ;
SUN:READ;
END;
等等,其中FILE2,FILE3,FILE5中的数组、集合、记录等类型可以先说明再来定义文件变量。
例如:
VAR
F1:FILE;
F2,F3:FILE3;
F4:FILE5;
与前面所有类型说明和变量定义一样,文件类型说明和变量定义也可以合并在一起,例如:
VAR
F1:FILE OF INTEGER;
F2,F3:FILE OF SET OF CHAR;
F4:FILE OF RECORD
NAME:STRING;
COURSE:ARRAY[1--10] OF REAL;
SUM:READ;
END;
Turbo Pascal对有类型文件的访问既可以顺序方式也可以用随机方式。
为了能随机访问有类型文件,Turbo Pascal提供如下几个命令:
命令格式1:seek(f,n)
功能:移动当前指针到指定f文件的第n个分量,f为非文本文件,n为长整型
命令格式2:filepos(f)
功能:回送当前文件指针,当前文件指针在文件头时,返回,函数值为长整型
命令格式3:filesize(f)
功能:回送文件长度,如文件空,则返回零,函数值为长整型
2、有类型文件的建立
有类型文件的建立只能通过程序的方式进行,其操作步骤与文本文件程序方式建立的步骤相仿,不同之处:(1)有类型文件的定义与文本文件的定义不同;(2)有类型文件可以利用SEEK命令指定指针随机写入。
3、有类型文件的访问
有类型文件访问的操作步骤与文本文件的程序访问操作步骤相仿,区别之处:(1)有类型文件的定义与文本文件的定义不同;(2)有类型文件可以利用SEEK命令访问文件记录中的任一记录与记录中的任一元素。
例6 建立几个学生的姓名序、座号、六门课程成绩总分的有类型文件。
分析:为简单起见,这里假设已有一文本文件FILEDATA.TXT,其内容如下:
10
li hong
1 89 67 56 98 76 45
wang ming
2 99 87 98 96 95 84
zhang yi hong
3 78 69 68 69 91 81
chang hong
4 81 93 82 93 75 76
lin xing
5 78 65 90 79 89 90
luo ze
6 96 85 76 68 69 91
lin jin jin
7 86 81 72 74 95 96
wang zheng
8 92 84 78 89 75 97
mao ling
9 84 86 92 86 69 89
cheng yi
10 86 94 81 94 86 87
第一个数10表示有10个学生,紧接着是第一个学生的姓名、座号、6科成绩,然后是第二个学生,等等。
从文本文件中读出数据,求出各人的总分,建立有类型文件,设文件名为filedata.fil,文件的类型为记录studreco,见下例程序。
程序:
例7 产生数1-16的平方、立方、四次方表存入有类型文件中, 并用顺序的方式访问一遍,用随机方式访问文件中的11和15两数及相应的平方、立方、四次方值。
分析:建立有类型文件文件名为BIAO.FIL,文件的类型为实数型。
(1)产生数1-16及其平方、立方、四次方值,写入BIAO.FIL,并顺序读出输出;
(2)用SEEK指针分别指向11和15数所在文件的位置,其位置数分别为10×4和14×4(注意文件的第一个位置是0),读出其值及相应的平方、立方、四次方值输出。
程序:
程序运行结果如下:
另外,Turbo Pascal还提供了第三种形式文件即无类型文件,无类型文件是低层I/O通道,如果不考虑有类型文件、 文本文件等存在磁盘上字节序列的逻辑解释,则数据的物理存储只不过是一些字节序列。这样它就与内存的物理单元一一对应。无类型文件用128个连续的字节做为一个记录(或分量)进行输入输出操作,数据直接在磁盘文件和变量之间传输,省去了文件缓解区,因此比其它文件少占内存,主要用来直接访问固定长元素的任意磁盘文件。
无类型文件的具体操作在这里就不一一介绍,请参看有关的书籍。
三、综合例析
例8 建立城市飞机往返邻接表。文本文件CITY.DAT内容如下:
第一行两个数字N和V;
N代表可以被访问的城市数,N是正数<100;
V代表下面要列出的直飞航线数,V是正数<100;
接下来N行是一个个城市名,可乘飞机访问这些城市;
接下来V行是每行有两个城市,两城市中间用空格隔开,表示这两个城市具有直通航线。
如:CITY1 CITY2表示乘飞机从CITY1到CITY2或从CITY2到CITY1。
生成文件CITY.RES,由0、1组成的N×N邻接表。
邻接表定义为:
分析
(1)用从文本文件city.dat中读入N个城市名存入一些数组CT中;
(2)读入V行互通航班城市名,每读一行,查找两城市在CT中的位置L、K,建立邻接关系,lj[l,k]=1和lj[k,j]=1;
(3)将生成的邻接表写入文本文件CITY.RES中。
设CITY.DAT内容如下:
10 20
fuzhou
beijin
shanghai
wuhan
hongkong
tiangjin
shenyan
nanchan
chansa
guangzhou
fuzhou beijin
fuzhou shanghai
fuzhou guangzhou
beijin shanghai
guangzhou beijin
wuhan fuzhou
shanghai guangzhou
hongkong beijin
fuzhou hongkong
nanchan beijin
nanchan tiangjin
tiangjin beijin
chansa shanghai
guangzhou wuhan
chansa beijin
wuhan beijin
shenyan beijin
shenyan tiangjin
shenyan shanghai
shenyan guangzhou
程序:
得到CITY.RES文件内容如下:
10
1 fuzhou
2 beijin
3 shanghai
4 wuhan
5 hongkong
6 tiangjin
7 shenyan
8 nanchan
9 chansa
10 guangzhou
0 1 1 1 1 0 0 0 0 1
1 0 1 1 1 1 1 1 1 1
1 1 0 0 0 0 1 0 1 1
1 1 0 0 0 0 0 0 0 1
1 1 0 0 0 0 0 0 0 0
0 1 0 0 0 0 1 1 0 0
0 1 1 0 0 1 0 0 0 1
0 1 0 0 0 1 0 0 0 0
0 1 1 0 0 0 0 0 0 0
1 1 1 1 0 0 1 0 0 0
例9 对例12.3的FILEDATE.FIL文件内容按总分的高低顺序排序。
分析:
文件的排序就是将文本文件的各分量按一定要求排列使文件有序,文件排序有内排序和外排序二种,内排序是指将文件各分量存入一个数组,再对数组排列,最后将该数组存入原来的文件。外排列不同于内排列,它不是将文件分量存入数组,而是对文件直接排序,内排序比外排序速度要快,但当文件很大时,无法调入内存,此时用外排序法较合适。
本程序使用过程SEEK,实现外排序。
程序:
习 题
1、编一程序,计算文本文件中行结束标志的数目。
2、计算文本文件的行长度的平均值、最大值和最小值。
3、一文本文件FILE.DAT存放N个学生某学科成绩,将成绩转换成直方图存入FILE.RES文件中。
如FILE.DAT内容为:
5
78 90 87 73 84
得到直方图文件FILE.RES内容为:
5
********
*********
*********
*******
********
4、银行账目文件含有每一开户的账目细节:开户号、姓名、地址、收支平衡额。写一程序,读入每一开户的账目,生成银行账目文件。
5、通讯录文件每个记录内容为:姓名、住址、单位、邮编、电话,编一程序按姓名顺序建立通讯录文件,要求先建立文件,再对文件按姓名顺序进行外排序。
字符串函数
求长度length
定义:function Length(S:String): Integer;
例子:
var
S: String;
begin
Readln (S);
Writeln('"', S, '"');
Writeln('length = ', Length(S));
end.
复制子串copy
定义:function Copy(S: String; Index: Integer; Count: Integer): String;
注意:S 是字符串类型的表达式。Index和Count是整型表达式。Copy 返回S中从Index开始,Count个字符长的一个子串。
例子:
var S: String;
begin
S := 'ABCDEF';
S := Copy(S, 2, 3); { 'BCD' }
end.
插入子串insert
定义:procedureInsert(Source: String; var S: String; Index: Integer);
注意:Source 是字符串类型的表达式。 S 是任意长度字符串类型变量。Index 是整型表达式。Insert 把 Source插在S中Index处。如果结果字符串的长度大于255,那么255之后的字符将被删除。
例子:
var
S: String;
begin
S := 'Honest Lincoln';
Insert('Abe ', S, 8); { 'Honest Abe Lincoln' }
end.
删除子串delete
定义:procedureDelete(var S: String; Index: Integer; Count:Integer);
注意:S 是字符串类型变量。 Index和Countare是整型表达式。Delete 删除S中从Index开始的Count个字符。如果Index大于S的长度,则不删除任何字符;如果Count大于S中从Index开始的实际字符数,则删除实际的字符数。
例子:
var
s: string;
begin
s := 'Honest Abe Lincoln';
Delete(s,8,4);
Writeln(s); { 'Honest Lincoln' }
Delete(s,9,10);
Writeln(s); { 'Honest L' }
end.
字符串转为数值val
定义:procedure Val(S; var V; var Code: Integer);
在这里:
S 是由一系列数字字符构成的字符串类型变量;。
V 是整型或实型变量;
Code 是Integer型变量
注意:Val将S转为它的数值形式。
例子:
var s:string;I, Code: Integer;
begin
s:='1234';
val(s,i,code);
writeln(i); { 1234 }
end.
数值转为字符串str
定义:procedure Str(X [: Width [: Decimals ]]; var S:string);
注意:将数值X转成字符串形式。
例子:
var
S: string[11];
begin
Str(I, S);
IntToStr := S;
end;
begin
Writeln(IntToStr(-5322));
Readln;
end.
求子串起始位置pos
定义:functionPos(Substr: String; S: String): Byte;
注意:Substr和S字符串类型表达式。Pos在S中搜索Substr并返回一个integer值。这个值是Substr的第一个字符在S中的位置。如果在S中没有找到Substr,则Pos返回0。
例子:
var S: String;
begin
S := ' 123.5';
{ Convert spaces to zeroes }
while Pos(' ', S) > 0 do
S[Pos(' ', S)] := '0';
end.
字符完全串连+
定义:操作符+把两个字符串联在一起。
例子:
var s1,s2,s:string;
begin
s1:='Turbo ';
s2:='pascal';
s:=s1+s2; { 'Turbo pascal' }
end.
字符串压缩空格串连-
定义:操作符-去掉第一个字符串最后的空格后,将两个字符串联在一起。
例子:
var s1,s2,s:string;
begin
s1:='Turbo ';
s2:='pascal';
s:=s1-s2; { 'Turbopascal' }
end.
Pascal中的数学函数
求绝对值函数abs(x)
定义:function Abs(X):(Same type as parameter);
说明:X可以是整型,也可以是实型;返回值和X的类型一致
例子:
var
r: Real;
i: Integer;
begin
r := Abs(-2.3); { 2.3 }
i := Abs(-157); { 157 }
end.
取整函数int(x)
定义:functionInt(X: Real): Real;
注意:X是实型数,返回值也是实型的;返回的是X的整数部分,也就是说,X被截尾了(而不是四舍五入)
例子:
var R: Real;
begin
R := Int(123.567); { 123.0 }
R := Int(-123.456); { -123.0 }
end.
截尾函数trunc(x)
定义:function Trunc(X: Real): Longint;
注意:X是实型表达式. Trunc 返回Longint型的X的整数部分
例子:
begin
Writeln(1.4, ' becomes ', Trunc(1.4)); { 1 }
Writeln(1.5, ' becomes ', Trunc(1.5)); { 1 }
Writeln(-1.4, 'becomes ', Trunc(-1.4)); { -1 }
Writeln(-1.5, 'becomes ', Trunc(-1.5)); { -1 }
end.
四舍五入函数round(x)
定义:functionRound(X: Real): Longint;
注意:X是实型表达式. Round 返回Longint型的X的四舍五入值.如果返回值超出了Longint的表示范围,则出错.
例子:
begin
Writeln(1.4, ' rounds to ', Round(1.4)); { 1 }
Writeln(1.5, ' rounds to ', Round(1.5)); { 2 }
Writeln(-1.4, 'rounds to ', Round(-1.4));{ -1 }
Writeln(-1.5, 'rounds to ', Round(-1.5));{ -2 }
end.
取小数函数frac(x)
定义:functionFrac(X: Real): Real;
注意:X 是实型表达式. 结果返回 X 的小数部分; 也就是说,Frac(X)= X - Int(_X).
例子:
var
R: Real;
begin
R := Frac(123.456); { 0.456 }
R := Frac(-123.456); { -0.456 }
end.
求平方根函数sqrt(x)和平方函数sqr(x)
定义:
平方根:function Sqrt(X: Real): Real;
注意:X 是实型表达式. 返回实型的X的平方根.
平方:function Sqr(X): (Same type as parameter);
注意:X 是实型或整型表达式.返回值的类型和X的类型一致,大小是X的平方,即X*X.
例子:
begin
Writeln('5 squared is ', Sqr(5)); { 25 }
Writeln('The square root of 2 is ',Sqrt(2.0)); { 1.414 }
end.
大家听说过fillchar这个标准过程吧。 很好用的。
var a:array [1..10] of arrtype;
执行fillchar(a,sizeof(a),0);
当arrtype为
1.real(其他差不多) 使得a中的元素全部成为0.0
2.integer(byte,word,longint,shortint都相同) 全部为0
3.boolean 全部为false
4.char 全部为#0
执行fillchar(a,size(a),1);
写几个特殊的
1.integer 全部为157(不知道为什么)
2.real 很大的一个数,同上。
3.boolean 全部为true
4.byte,shortint 全部为1,所以integer不行可以暂时用这两个嘛。 要不然就减去156
任何一个天才都不敢说,他编的程序是100%正确的。几乎每一个稍微复杂一点的程序都必须经过反复的调试,修改,最终才完成。所以说,程序的调试是编程中的一项重要技术。我们现在就来掌握一下基本的程序调试。
我们以下的示范,是以时下比较流行的Borland Pascal 7.0为例子,其他的编程环境可能略有不同,但大致上是一致的。
我们先编一个比较简单的程序,看看程序是如何调试的。
program tiaoshi; var i:integer; begin for i:=1 to 300 do begin if i mod 2 = 0 then if i mod 3 = 0 then if i mod 5 = 0 then writeln(i); end; end.
该程序是输出300以内同时能被2,3,5整除的整数。 现在我们开始调试。调试有多种方法,先介绍一种,权且叫步骤法,步骤法就是模拟计算机的运算,把程序每一步执行的情况都反映出来。通常,我们有F8即STEP这个功能来实现,如图:
不断地按F8,计算机就会一步步地执行程序,直到执行到最后的“end.”为止。
可能你还没有发现F8的威力,我们不妨把上面的程序略微修改一下,再配合另外的一种调试的利器watch,你就会发现步骤法的用处。
program tiaoshi; var i:integer; a,b,c:boolean; begin for i:=1 to 300 do begin a:=false; b:=false; c:=false; if i mod 2 = 0 then a:=true; if i mod 3 = 0 then b:=true; if i mod 5 = 0 then c:=true; if a and b and c then writeln(i); end; end.
如图,我们单击菜单栏中debug选项,里面有一项叫watch的选项,我们单击它。
就会出现一个watch窗口:
watch窗口可以让我们观察变量的变化情况,具体操作是在watches窗口内按Insert键:
这时,屏幕上弹出一个菜单,我们输入所需要观察的变量名,我们分别输入i,a,b,c这4个变量名,于是watches窗口内就有如下的4个变量的状态:
这时,我们再次使用步骤法,我们会发现,这4个变量的状态随着程序的执行而不断变化,比如:
这样我们就可以方便地知道执行每一步之后,程序的各个变量的变化情况,从中我们可以知道我们的程序是否出错,在哪里出错,方便我们及时地修改。
下一次,我们介绍另外的一种方法,断点法
程序的调试(二) ——断点法
在前面我们已经学习了基本的程序调试方法——步骤法。步骤法有一个缺点,就是在遇到循环次数比较多或者语句比较多的时候,用起来比较费时,今天我们来学习一种新的也是常用的调试方法——断点法。
所谓断点法,就是在程序执行到某一行的时候,计算机自动停止运行,并保留这时各变量的状态,方便我们检查,校对。我们还是以前面求同时能被2,3,5整除的3000以内的自然数为例,具体操作如下:
我们把光标移动到程序的第14行,按下ctrl+F8,这时我们会发现,该行变成红色,这表明该行已经被设置成断点行,当我们每次运行到第14行的时候,计算机都会自动停下来供我们调试。
我们必须学以致用,赶快运用刚学的watch方法,看看这家伙到底有多厉害。
请记住,计算机是执行到断点行之前的一行,断点行并没有执行,所以这时b:=true这一句并没有执行。
断点行除了有以上用处之外,还有另外一个重要用处。它方便我们判断某个语句有没有执行或者是不是在正确的时刻执行,因为有时程序由于人为的疏忽,可能在循环或者递归时出现我们无法预料的混乱,这时候通过断点法,我们就能够判断程序是不是依照我们预期的顺序执行。
1、 break 是用来退出其所在的循环语句
即 : 不论在任何一个循环语句中 执行了 break 的话, 马上退出这个语句。
相当于 : goto 这一层循环语句 最末尾一句的下一句。
例如:var i : integer;
begin
for i := 1 to 10 do
begin
{1} writeln(i);
break;
writeln(i+1);
end;
readln
end.
执行结果 :
1
可见 第一次循环 时 , 执行了{1}句 后 , 执行 break ,然后马上退出了这个for语句。 {*****} 注意 : 以上两个语句 只 对 它们所在的 那层循环语句 起作用,也就是说 : 如果有多个 循环语句 相嵌套, 其中 某一层 执行了continue / break 语句, 它们并不能影响上面几层的循环语句。
2、exit 是退出当前程序块;
即 : 在任何子程序 中执行 exit ,那么 将退出 这个子程序;如果是在 主程序中执行 exit , 那么将退出整个程序。相当于 : goto 这个程序块 的 末尾 的 end 例如 : 试除法判断素数时,一旦整除,就把函数值赋为false ,然后exit;{******}注意 : 类似上面的 , exit也是只对当前 这一个 子程序产生作用,如果多重嵌套子程序 , 那么其中某个子程序执行了exit以后,将返回到 调用它的那个语句 的下一个语句。
3、halt : 没什么好说的,退出整个程序,Game Over.
例如 : 搜索时, 一旦找到一个解,就打印,然后执行halt,退出整个程序。使用exit , halt 应该注意的地方:要注意所有可能会退出 子程序或主程序 的地方 均要妥善处理好善后工作,比如 文件是否关闭,输出是否完整等。
最后说一句 , 使用这些语句 使得程序结构不止有一个出口,破坏了结构化程序设计的 标准控制结构 , 使程序难以调试 (但是往往便于编写),应尽量避免使用,因为它们完全可以用其它语句代替,所以,除非使用这些语句 能给 编写程序 带来 较大的方便,且可读性不受到影响,才值得一用。http://wenku.baidu.com/view/4a1b27d604a1b0717ed5dd25.html?re=view

















 3255
3255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









